 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Adaptive Moving-window Service Patrolling for Real-time Incident Management during High-impact Events
Apr 15, 2025



This paper presents the Traffic Adaptive Moving-window Patrolling Algorithm (TAMPA), designed to improve real-time incident management during major events like sports tournaments and concerts. Such events significantly stress transportation networks, requiring efficient and adaptive patrol solutions. TAMPA integrates predictive traffic modeling and real-time complaint estimation, dynamically optimizing patrol deployment. Using dynamic programming, the algorithm continuously adjusts patrol strategies within short planning windows, effectively balancing immediate response and efficient routing. Leveraging the Dvoretzky-Kiefer-Wolfowitz inequality, TAMPA detects significant shifts in complaint patterns, triggering proactive adjustments in patrol routes. Theoretical analyses ensure performance remains closely aligned with optimal solutions. Simulation results from an urban traffic network demonstrate TAMPA's superior performance, showing improvements of approximately 87.5\% over stationary methods and 114.2\% over random strategies. Future work includes enhancing adaptability and incorporating digital twin technology for improved predictive accuracy, particularly relevant for events like the 2026 FIFA World Cup at MetLife Stadium.
ADAPT: A Game-Theoretic and Neuro-Symbolic Framework for Automated Distributed Adaptive Penetration Testing
Oct 31, 2024The integration of AI into modern critical infrastructure systems, such as healthcare, has introduced new vulnerabilities that can significantly impact workflow, efficiency, and safety. Additionally, the increased connectivity has made traditional human-driven penetration testing insufficient for assessing risks and developing remediation strategies. Consequently, there is a pressing need for a distributed, adaptive, and efficient automated penetration testing framework that not only identifies vulnerabilities but also provides countermeasures to enhance security posture. This work presents ADAPT, a game-theoretic and neuro-symbolic framework for automated distributed adaptive penetration testing, specifically designed to address the unique cybersecurity challenges of AI-enabled healthcare infrastructure networks. We use a healthcare system case study to illustrate the methodologies within ADAPT. The proposed solution enables a learning-based risk assessment. Numerical experiments are used to demonstrate effective countermeasures against various tactical techniques employed by adversarial AI.
Multi-level Traffic-Responsive Tilt Camera Surveillance through Predictive Correlated Online Learning
Aug 05, 2024In urban traffic management, the primary challenge of dynamically and efficiently monitoring traffic conditions is compounded by the insufficient utilization of thousands of surveillance cameras along the intelligent transportation system. This paper introduces the multi-level Traffic-responsive Tilt Camera surveillance system (TTC-X), a novel framework designed for dynamic and efficient monitoring and management of traffic in urban networks. By leveraging widely deployed pan-tilt-cameras (PTCs), TTC-X overcomes the limitations of a fixed field of view in traditional surveillance systems by providing mobilized and 360-degree coverage. The innovation of TTC-X lies in the integration of advanced machine learning modules, including a detector-predictor-controller structure, with a novel Predictive Correlated Online Learning (PiCOL) methodology and the Spatial-Temporal Graph Predictor (STGP) for real-time traffic estimation and PTC control. The TTC-X is tested and evaluated under three experimental scenarios (e.g., maximum traffic flow capture, dynamic route planning, traffic state estimation) based on a simulation environment calibrated using real-world traffic data in Brooklyn, New York. The experimental results showed that TTC-X captured over 60\% total number of vehicles at the network level, dynamically adjusted its route recommendation in reaction to unexpected full-lane closure events, and reconstructed link-level traffic states with best MAE less than 1.25 vehicle/hour. Demonstrating scalability, cost-efficiency, and adaptability, TTC-X emerges as a powerful solution for urban traffic management in both cyber-physical and real-world environments.
Neurosymbolic Meta-Reinforcement Lookahead Learning Achieves Safe Self-Driving in Non-Stationary Environments
Sep 05, 2023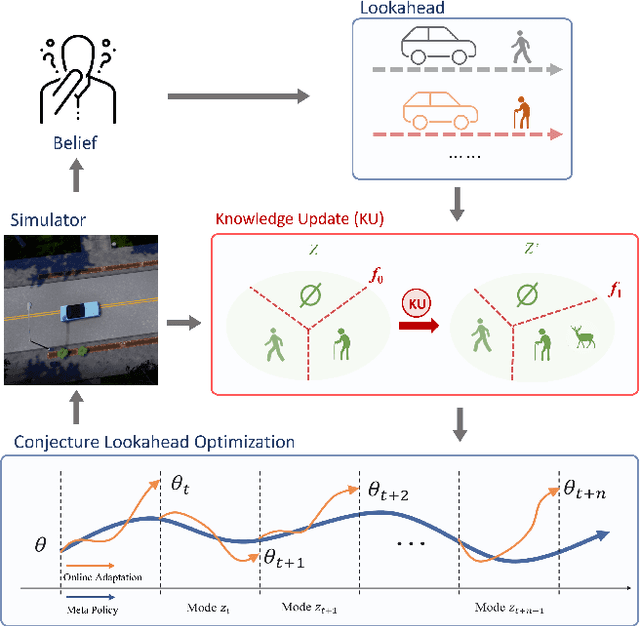
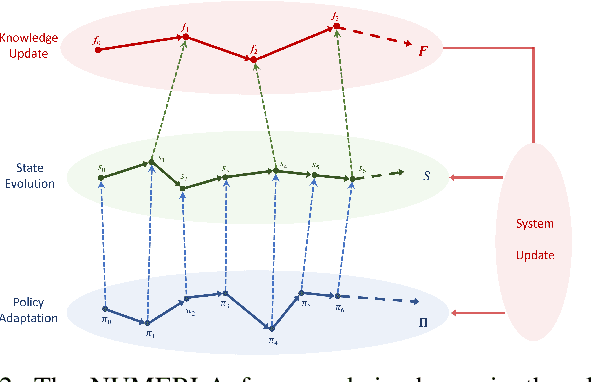
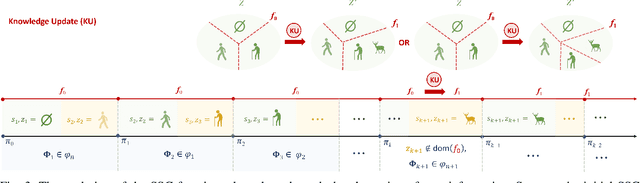
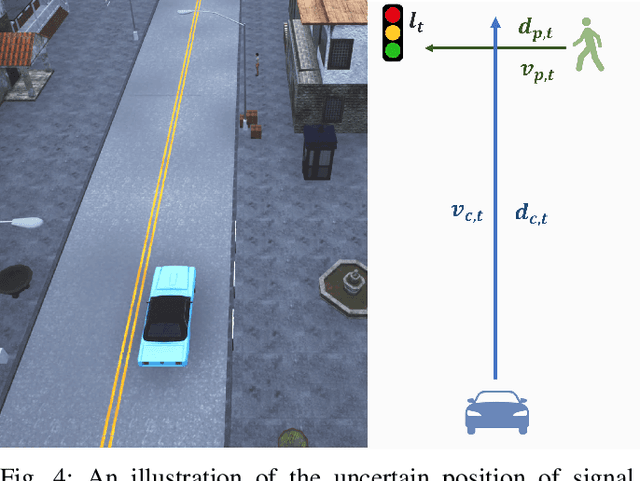
In the area of learning-driven artificial intelligence advancement, the integration of machine learning (ML) into self-driving (SD) technology stands as an impressive engineering feat. Yet, in real-world applications outside the confines of controlled laboratory scenarios, the deployment of self-driving technology assumes a life-critical role, necessitating heightened attention from researchers towards both safety and efficiency. To illustrate, when a self-driving model encounters an unfamiliar environment in real-time execution, the focus must not solely revolve around enhancing its anticipated performance; equal consideration must be given to ensuring its execution or real-time adaptation maintains a requisite level of safety. This study introduces an algorithm for online meta-reinforcement learning, employing lookahead symbolic constraints based on \emph{Neurosymbolic Meta-Reinforcement Lookahead Learning} (NUMERLA). NUMERLA proposes a lookahead updating mechanism that harmonizes the efficiency of online adaptations with the overarching goal of ensuring long-term safety. Experimental results demonstrate NUMERLA confers the self-driving agent with the capacity for real-time adaptability, leading to safe and self-adaptive driving under non-stationary urban human-vehicle interaction scenarios.
Generalizable Wireless Navigation through Physics-Informed Reinforcement Learning in Wireless Digital Twin
Jun 11, 2023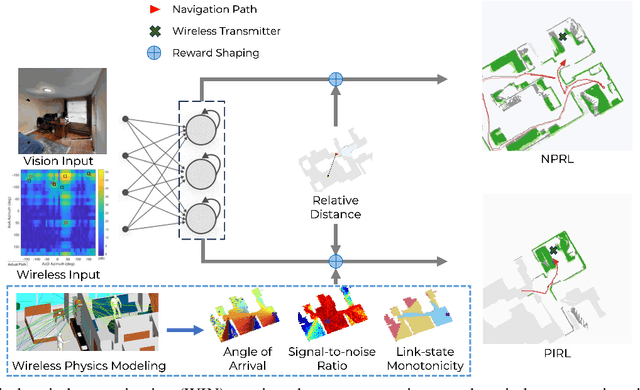
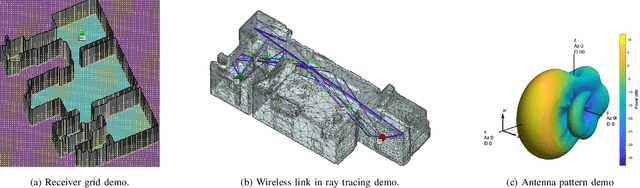
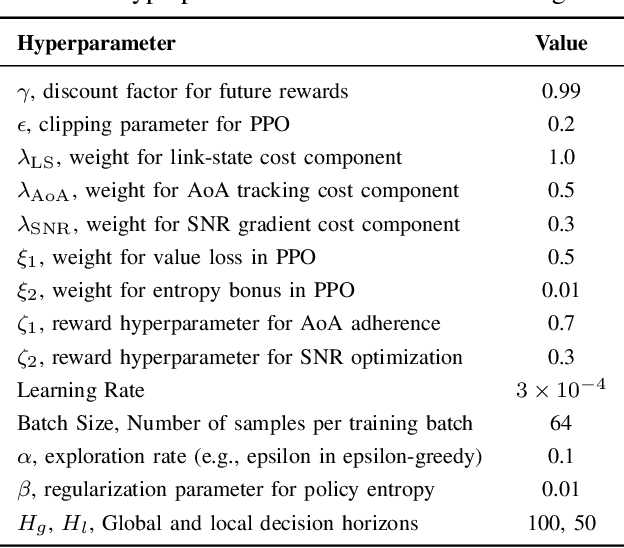
The growing focus on indoor robot navigation utilizing wireless signals has stemmed from the capability of these signals to capture high-resolution angular and temporal measurements. However, employing end-to-end generic reinforcement learning (RL) for wireless indoor navigation (WIN) in initially unknown environments remains a significant challenge, due to its limited generalization ability and poor sample efficiency. At the same time, purely model-based solutions, based on radio frequency propagation, are simple and generalizable, but unable to find optimal decisions in complex environments. This work proposes a novel physics-informed RL (PIRL) were a standard distance-to-target-based cost along with physics-informed terms on the optimal trajectory. The proposed PIRL is evaluated using a wireless digital twin (WDT) built upon simulations of a large class of indoor environments from the AI Habitat dataset augmented with electromagnetic radiation (EM) simulation for wireless signals. It is shown that the PIRL significantly outperforms both standard RL and purely physics-based solutions in terms of generalizability and performance. Furthermore, the resulting PIRL policy is explainable in that it is empirically consistent with the physics heuristic.
Level-$k$ Meta-Learning for Pedestrian-Aware Self-Driving
Dec 17, 2022



One challenge for self-driving cars is their interactions not only with other vehicles but also with pedestrians in urban environments. The unpredictability of pedestrian behaviors at intersections can lead to a high rate of accidents. The first pedestrian fatality caused by autonomous vehicles was reported in 2018 when a self-driving Uber vehicle struck a woman crossing an intersection in Tempe, Arizona in the nighttime. There is a need for creating machine intelligence that allows autonomous vehicles to control the car and adapt to different pedestrian behaviors to prevent accidents. In this work, (a) We develop a Level-$k$ Meta Reinforcement Learning model for the vehicle-human interactions and define its solution concept; (b) We test our LK-MRL structure in level-$0$ pedestrians interacting with level-$1$ car scenario, compare the trained policy with multiple baseline methods, and demonstrate its advantage in road safety; (c) Furthermore, based on the properties of level-$k$ thinking, we test our LK-MRL structure in level-$1$ pedestrians interacting with level-$2$ car scenario and verify by experimental results that LK-MRL maintains its advantageous with the using of reinforcement learning of producing different level of agents with strategies of the best response of their lower level thinkers, which provides us possible to create higher level scenarios.
Self-Adaptive Driving in Nonstationary Environments through Conjectural Online Lookahead Adaptation
Oct 06, 2022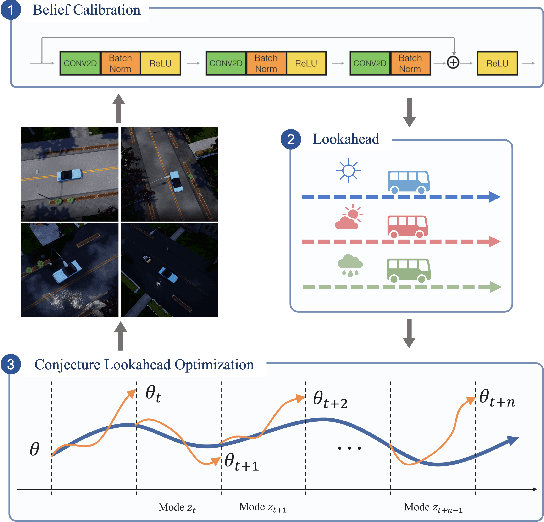


Powered by deep representation learning, reinforcement learning (RL) provides an end-to-end learning framework capable of solving self-driving (SD) tasks without manual designs. However, time-varying nonstationary environments cause proficient but specialized RL policies to fail at execution time. For example, an RL-based SD policy trained under sunny days does not generalize well to rainy weather. Even though meta learning enables the RL agent to adapt to new tasks/environments, its offline operation fails to equip the agent with online adaptation ability when facing nonstationary environments. This work proposes an online meta reinforcement learning algorithm based on the \emph{conjectural online lookahead adaptation} (COLA). COLA determines the online adaptation at every step by maximizing the agent's conjecture of the future performance in a lookahead horizon. Experimental results demonstrate that under dynamically changing weather and lighting conditions, the COLA-based self-adaptive driving outperforms the baseline policies in terms of online adaptability. A demo video, source code, and appendixes are available at {\tt https://github.com/Panshark/COLA}
Sampling Attacks on Meta Reinforcement Learning: A Minimax Formulation and Complexity Analysis
Jul 29, 2022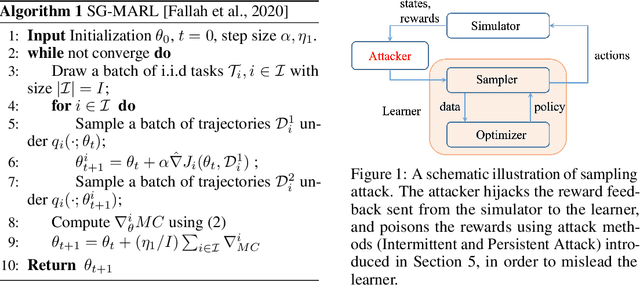
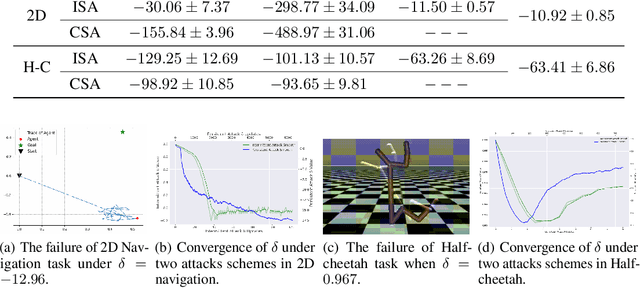
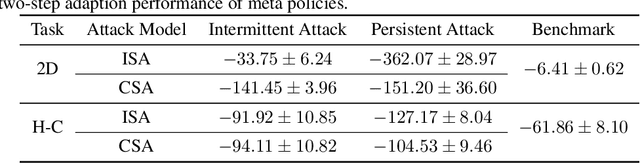
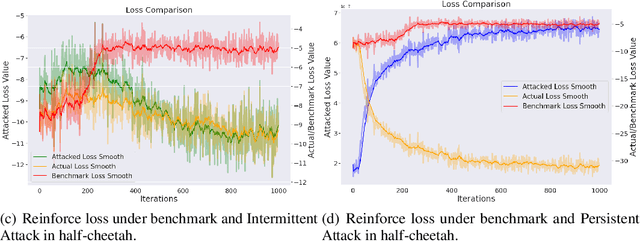
Meta reinforcement learning (meta RL), as a combination of meta-learning ideas and reinforcement learning (RL), enables the agent to adapt to different tasks using a few samples. However, this sampling-based adaptation also makes meta RL vulnerable to adversarial attacks. By manipulating the reward feedback from sampling processes in meta RL, an attacker can mislead the agent into building wrong knowledge from training experience, which deteriorates the agent's performance when dealing with different tasks after adaptation. This paper provides a game-theoretical underpinning for understanding this type of security risk. In particular, we formally define the sampling attack model as a Stackelberg game between the attacker and the agent, which yields a minimax formulation. It leads to two online attack schemes: Intermittent Attack and Persistent Attack, which enable the attacker to learn an optimal sampling attack, defined by an $\epsilon$-first-order stationary point, within $\mathcal{O}(\epsilon^{-2})$ iterations. These attack schemes freeride the learning progress concurrently without extra interactions with the environment. By corroborating the convergence results with numerical experiments, we observe that a minor effort of the attacker can significantly deteriorate the learning performance, and the minimax approach can also help robustify the meta RL algorithms.