 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Wireless Navigation through Physics-Informed Reinforcement Learning in Wireless Digital Twin
Paper and Code
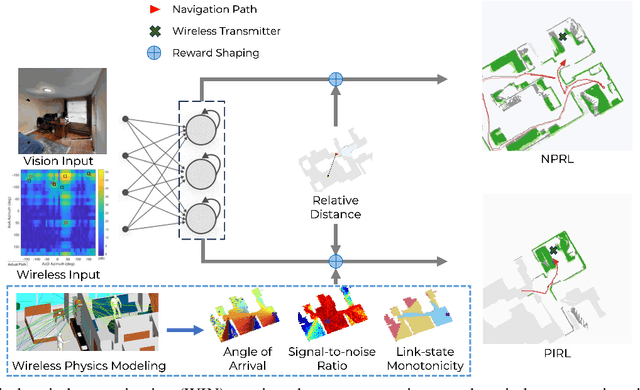
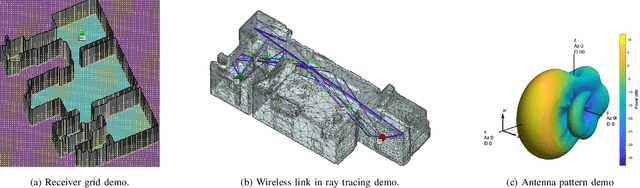
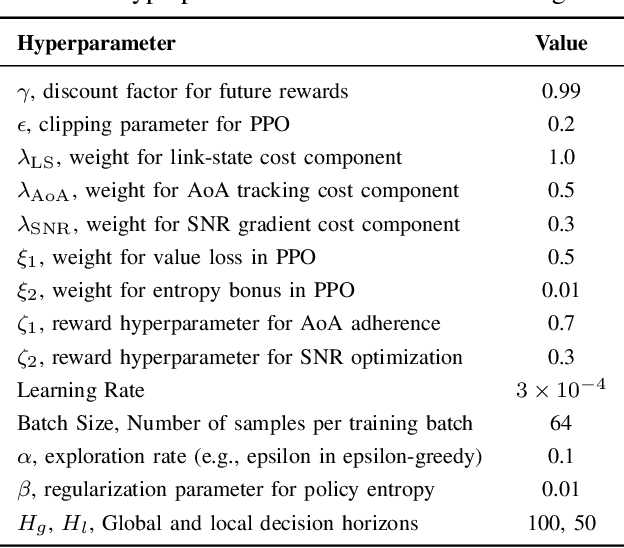
The growing focus on indoor robot navigation utilizing wireless signals has stemmed from the capability of these signals to capture high-resolution angular and temporal measurements. However, employing end-to-end generic reinforcement learning (RL) for wireless indoor navigation (WIN) in initially unknown environments remains a significant challenge, due to its limited generalization ability and poor sample efficiency. At the same time, purely model-based solutions, based on radio frequency propagation, are simple and generalizable, but unable to find optimal decisions in complex environments. This work proposes a novel physics-informed RL (PIRL) were a standard distance-to-target-based cost along with physics-informed terms on the optimal trajectory. The proposed PIRL is evaluated using a wireless digital twin (WDT) built upon simulations of a large class of indoor environments from the AI Habitat dataset augmented with electromagnetic radiation (EM) simulation for wireless signals. It is shown that the PIRL significantly outperforms both standard RL and purely physics-based solutions in terms of generalizability and performance. Furthermore, the resulting PIRL policy is explainable in that it is empirically consistent with the physics heuristic.