 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Architectures for Real-Time ECG Interpretation on Limited Hardware
May 11, 2026Electrocardiogram (ECG) interpretation is essential for diagnosing a wide range of cardiac abnormalities. While deep learning has shown strong potential for automating ECG classification, many existing models rely on large, computationally intensive architectures that hinder practical deployment. In this paper, we present an empirical study of convolutional neural network (CNN) architectures, exploring tradeoffs between diagnostic accuracy and computational efficiency. We benchmark two established baselines: AttiaNet, a compact model composed of sequential temporal and spatial blocks, and DeepResidualCNN, the winning architecture of the 2021 PhysioNet/Computing in Cardiology Challenge. Building on these, we propose three lightweight models: (i) ParallelCNN, which employs dual temporal and spatial branches for parallel pattern extraction; (ii) ParallelCNNew, a variant with symmetric weight initialization for balanced feature learning; and (iii) SimpleNet, a streamlined architecture that jointly processes temporal and spatial dimensions. Our experiments span three publicly available 12-lead ECG datasets from Germany, China, and the United States, covering binary, multiclass, and multilabel classification tasks across diverse patient populations. We further evaluate the impact of integrating low-cost demographic metadata (age and sex) to improve performance with minimal overhead. To ensure fair comparison, we introduce a unified Efficiency Score that integrates model size, inference speed, memory usage, and AUC performance. By balancing diagnostic performance and efficiency, our models offer a scalable and viable foundation for next-generation AI systems in cardiovascular care.
* 9 pages, 6 figures, 3 tables. Published in: 2025 IEEE International Conference on Big Data (BigData), pp. 3275-3284. DOI: 10.1109/BIGDATA66926.2025.11402097
Monitoring morphometric drift in lifelong learning segmentation of the spinal cord
May 02, 2025Morphometric measures derived from spinal cord segmentations can serve as diagnostic and prognostic biomarkers in neurological diseases and injuries affecting the spinal cord. While robust, automatic segmentation methods to a wide variety of contrasts and pathologies have been developed over the past few years, whether their predictions are stable as the model is updated using new datasets has not been assessed. This is particularly important for deriving normative values from healthy participants. In this study, we present a spinal cord segmentation model trained on a multisite $(n=75)$ dataset, including 9 different MRI contrasts and several spinal cord pathologies. We also introduce a lifelong learning framework to automatically monitor the morphometric drift as the model is updated using additional datasets. The framework is triggered by an automatic GitHub Actions workflow every time a new model is created, recording the morphometric values derived from the model's predictions over time. As a real-world application of the proposed framework, we employed the spinal cord segmentation model to update a recently-introduced normative database of healthy participants containing commonly used measures of spinal cord morphometry. Results showed that: (i) our model outperforms previous versions and pathology-specific models on challenging lumbar spinal cord cases, achieving an average Dice score of $0.95 \pm 0.03$; (ii) the automatic workflow for monitoring morphometric drift provides a quick feedback loop for developing future segmentation models; and (iii) the scaling factor required to update the database of morphometric measures is nearly constant among slices across the given vertebral levels, showing minimum drift between the current and previous versions of the model monitored by the framework. The model is freely available in Spinal Cord Toolbox v7.0.
Impact of Data Patterns on Biotype identification Using Machine Learning
Mar 15, 2025



Background: Patient stratification in brain disorders remains a significant challenge, despite advances in machine learning and multimodal neuroimaging. Automated machine learning algorithms have been widely applied for identifying patient subtypes (biotypes), but results have been inconsistent across studies. These inconsistencies are often attributed to algorithmic limitations, yet an overlooked factor may be the statistical properties of the input data. This study investigates the contribution of data patterns on algorithm performance by leveraging synthetic brain morphometry data as an exemplar. Methods: Four widely used algorithms-SuStaIn, HYDRA, SmileGAN, and SurrealGAN were evaluated using multiple synthetic pseudo-patient datasets designed to include varying numbers and sizes of clusters and degrees of complexity of morphometric changes. Ground truth, representing predefined clusters, allowed for the evaluation of performance accuracy across algorithms and datasets. Results: SuStaIn failed to process datasets with more than 17 variables, highlighting computational inefficiencies. HYDRA was able to perform individual-level classification in multiple datasets with no clear pattern explaining failures. SmileGAN and SurrealGAN outperformed other algorithms in identifying variable-based disease patterns, but these patterns were not able to provide individual-level classification. Conclusions: Dataset characteristics significantly influence algorithm performance, often more than algorithmic design. The findings emphasize the need for rigorous validation using synthetic data before real-world application and highlight the limitations of current clustering approaches in capturing the heterogeneity of brain disorders. These insights extend beyond neuroimaging and have implications for machine learning applications in biomedical research.
FPT+: A Parameter and Memory Efficient Transfer Learning Method for High-resolution Medical Image Classification
Aug 05, 2024



The success of large-scale pre-trained models has established fine-tuning as a standard method for achieving significant improvements in downstream tasks. However, fine-tuning the entire parameter set of a pre-trained model is costly. Parameter-efficient transfer learning (PETL) has recently emerged as a cost-effective alternative for adapting pre-trained models to downstream tasks. Despite its advantages, the increasing model size and input resolution present challenges for PETL, as the training memory consumption is not reduced as effectively as the parameter usage. In this paper, we introduce Fine-grained Prompt Tuning plus (FPT+), a PETL method designed for high-resolution medical image classification, which significantly reduces memory consumption compared to other PETL methods. FPT+ performs transfer learning by training a lightweight side network and accessing pre-trained knowledge from a large pre-trained model (LPM) through fine-grained prompts and fusion modules. Specifically, we freeze the LPM and construct a learnable lightweight side network. The frozen LPM processes high-resolution images to extract fine-grained features, while the side network employs the corresponding down-sampled low-resolution images to minimize the memory usage. To enable the side network to leverage pre-trained knowledge, we propose fine-grained prompts and fusion modules, which collaborate to summarize information through the LPM's intermediate activations. We evaluate FPT+ on eight medical image datasets of varying sizes, modalities, and complexities. Experimental results demonstrate that FPT+ outperforms other PETL methods, using only 1.03% of the learnable parameters and 3.18% of the memory required for fine-tuning an entire ViT-B model. Our code is available at https://github.com/YijinHuang/FPT.
FPT: Fine-grained Prompt Tuning for Parameter and Memory Efficient Fine Tuning in High-resolution Medical Image Classification
Mar 12, 2024Parameter-efficient fine-tuning (PEFT) is proposed as a cost-effective way to transfer pre-trained models to downstream tasks, avoiding the high cost of updating entire large-scale pre-trained models (LPMs). In this work, we present Fine-grained Prompt Tuning (FPT), a novel PEFT method for medical image classification. FPT significantly reduces memory consumption compared to other PEFT methods, especially in high-resolution contexts. To achieve this, we first freeze the weights of the LPM and construct a learnable lightweight side network. The frozen LPM takes high-resolution images as input to extract fine-grained features, while the side network is fed low-resolution images to reduce memory usage. To allow the side network to access pre-trained knowledge, we introduce fine-grained prompts that summarize information from the LPM through a fusion module. Important tokens selection and preloading techniques are employed to further reduce training cost and memory requirements. We evaluate FPT on four medical datasets with varying sizes, modalities, and complexities. Experimental results demonstrate that FPT achieves comparable performance to fine-tuning the entire LPM while using only 1.8% of the learnable parameters and 13% of the memory costs of an encoder ViT-B model with a 512 x 512 input resolution.
MProtoNet: A Case-Based Interpretable Model for Brain Tumor Classification with 3D Multi-parametric Magnetic Resonance Imaging
Apr 14, 2023



Recent applications of deep convolutional neural networks in medical imaging raise concerns about their interpretability. While most explainable deep learning applications use post hoc methods (such as GradCAM) to generate feature attribution maps, there is a new type of case-based reasoning models, namely ProtoPNet and its variants, which identify prototypes during training and compare input image patches with those prototypes. We propose the first medical prototype network (MProtoNet) to extend ProtoPNet to brain tumor classification with 3D multi-parametric magnetic resonance imaging (mpMRI) data. To address different requirements between 2D natural images and 3D mpMRIs especially in terms of localizing attention regions, a new attention module with soft masking and online-CAM loss is introduced. Soft masking helps sharpen attention maps, while online-CAM loss directly utilizes image-level labels when training the attention module. MProtoNet achieves statistically significant improvements in interpretability metrics of both correctness and localization coherence (with a best activation precision of $0.713\pm0.058$) without human-annotated labels during training, when compared with GradCAM and several ProtoPNet variants. The source code is available at https://github.com/aywi/mprotonet.
Scanner Invariant Multiple Sclerosis Lesion Segmentation from MRI
Oct 22, 2019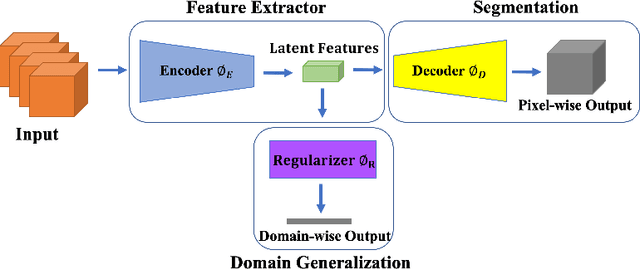
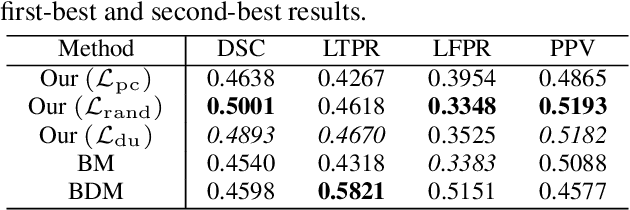
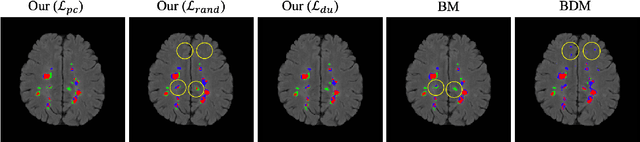
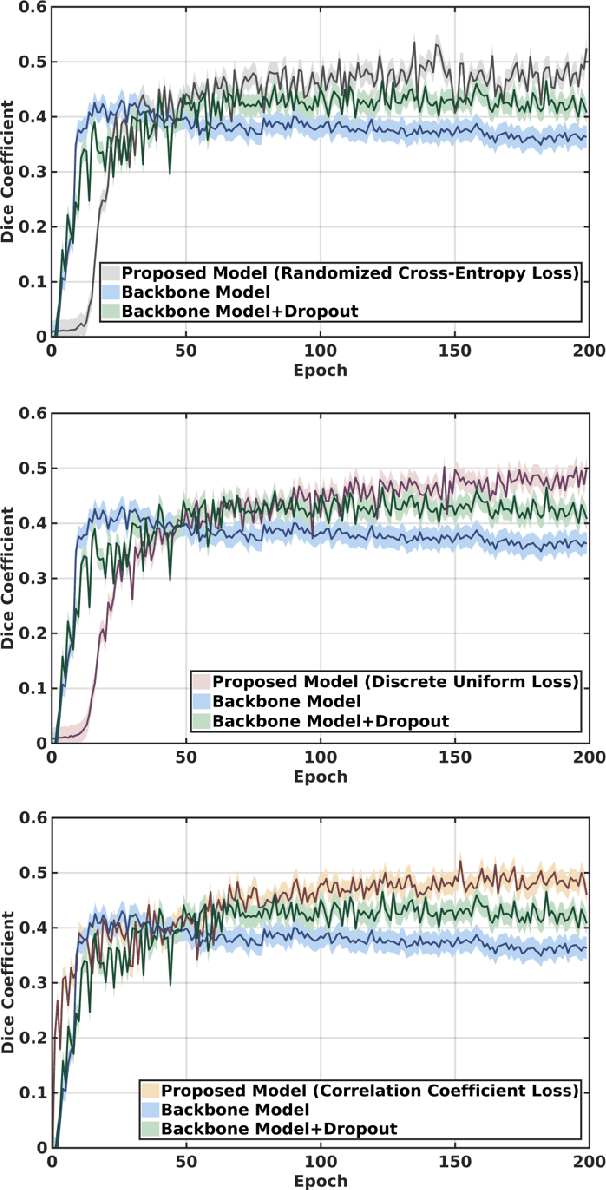
This paper presents a simple and effective generalization method for magnetic resonance imaging (MRI) segmentation when data is collected from multiple MRI scanning sites and as a consequence is affected by (site-)domain shifts. We propose to integrate a traditional encoder-decoder network with a regularization network. This added network includes an auxiliary loss term which is responsible for the reduction of the domain shift problem and for the resulting improved generalization. The proposed method was evaluated on multiple sclerosis lesion segmentation from MRI data. We tested the proposed model on an in-house clinical dataset including 117 patients from 56 different scanning sites. In the experiments, our method showed better generalization performance than other baseline networks.