 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying the key components in ResNet-50 for diabetic retinopathy grading from fundus images: a systematic investigation
Paper and Code
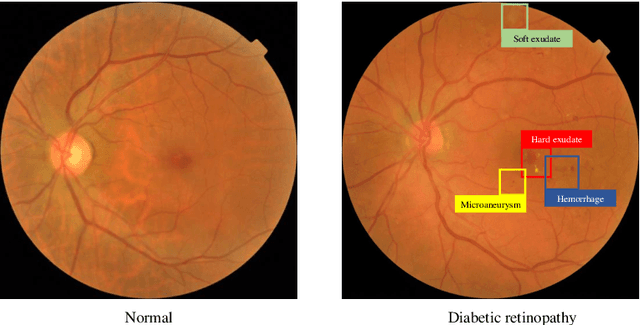
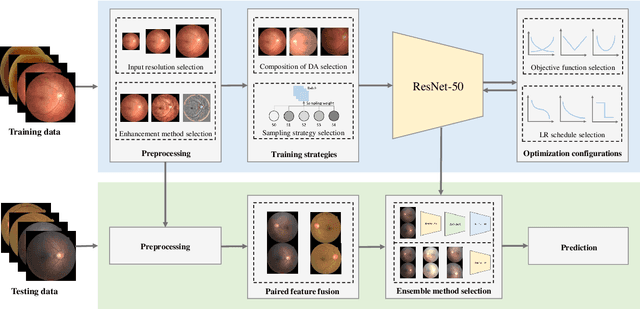

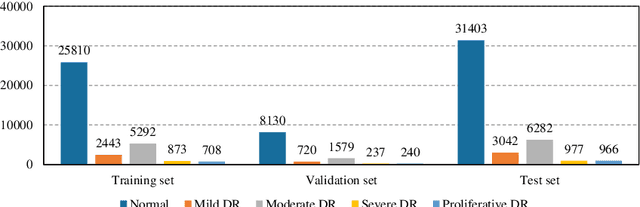
Although deep learning based diabetic retinopathy (DR) classification methods typically benefit from well-designed architectures of convolutional neural networks, the training setting also has a non-negligible impact on the prediction performance. The training setting includes various interdependent components, such as objective function, data sampling strategy and data augmentation approach. To identify the key components in a standard deep learning framework (ResNet-50) for DR grading, we systematically analyze the impact of several major components. Extensive experiments are conducted on a publicly-available dataset EyePACS. We demonstrate that (1) the ResNet-50 framework for DR grading is sensitive to input resolution, objective function, and composition of data augmentation, (2) using mean square error as the loss function can effectively improve the performance with respect to a task-specific evaluation metric, namely the quadratically-weighted Kappa, (3) utilizing eye pairs boosts the performance of DR grading and (4) using data resampling to address the problem of imbalanced data distribution in EyePACS hurts the performance. Based on these observations and an optimal combination of the investigated components, our framework, without any specialized network design, achieves the state-of-the-art result (0.8631 for Kappa) on the EyePACS test set (a total of 42670 fundus images) with only image-level labels. Our codes and pre-trained model are available at https://github.com/YijinHuang/pytorch-classification