 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Graph VPR: A Text-to-Graph Expert System for Explainable Place Recognition in Changing Environments
Dec 21, 2025Visual Place Recognition (VPR) in long-term deployment requires reasoning beyond pixel similarity: systems must make transparent, interpretable decisions that remain robust under lighting, weather and seasonal change. We present Text2Graph VPR, an explainable semantic localization system that converts image sequences into textual scene descriptions, parses those descriptions into structured scene graphs, and reasons over the resulting graphs to identify places. Scene graphs capture objects, attributes and pairwise relations; we aggregate per-frame graphs into a compact place representation and perform retrieval with a dual-similarity mechanism that fuses learned Graph Attention Network (GAT) embeddings and a Shortest-Path (SP) kernel for structural matching. This hybrid design enables both learned semantic matching and topology-aware comparison, and -- critically -- produces human-readable intermediate representations that support diagnostic analysis and improve transparency in the decision process. We validate the system on Oxford RobotCar and MSLS (Amman/San Francisco) benchmarks and demonstrate robust retrieval under severe appearance shifts, along with zero-shot operation using human textual queries. The results illustrate that semantic, graph-based reasoning is a viable and interpretable alternative for place recognition, particularly suited to safety-sensitive and resource-constrained settings.
A Triplet-loss Dilated Residual Network for High-Resolution Representation Learning in Image Retrieval
Mar 15, 2023Content-based image retrieval is the process of retrieving a subset of images from an extensive image gallery based on visual contents, such as color, shape or spatial relations, and texture. In some applications, such as localization, image retrieval is employed as the initial step. In such cases, the accuracy of the top-retrieved images significantly affects the overall system accuracy. The current paper introduces a simple yet efficient image retrieval system with a fewer trainable parameters, which offers acceptable accuracy in top-retrieved images. The proposed method benefits from a dilated residual convolutional neural network with triplet loss. Experimental evaluations show that this model can extract richer information (i.e., high-resolution representations) by enlarging the receptive field, thus improving image retrieval accuracy without increasing the depth or complexity of the model. To enhance the extracted representations' robustness, the current research obtains candidate regions of interest from each feature map and applies Generalized-Mean pooling to the regions. As the choice of triplets in a triplet-based network affects the model training, we employ a triplet online mining method. We test the performance of the proposed method under various configurations on two of the challenging image-retrieval datasets, namely Revisited Paris6k (RPar) and UKBench. The experimental results show an accuracy of 94.54 and 80.23 (mean precision at rank 10) in the RPar medium and hard modes and 3.86 (recall at rank 4) in the UKBench dataset, respectively.
Deep Learning Approaches on Image Captioning: A Review
Jan 31, 2022


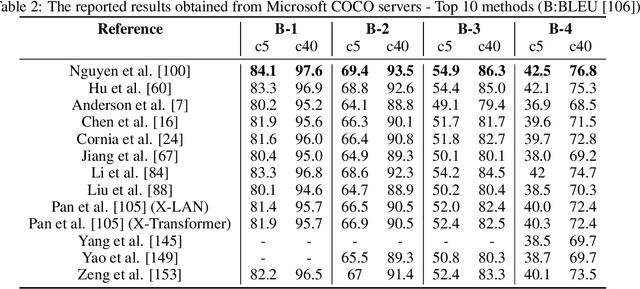
Automatic image captioning, which involves describing the contents of an image, is a challenging problem with many applications in various research fields. One notable example is designing assistants for the visually impaired. Recently, there have been significant advances in image captioning methods owing to the breakthroughs in deep learning. This survey paper aims to provide a structured review of recent image captioning techniques, and their performance, focusing mainly on deep learning methods. We also review widely-used datasets and performance metrics, in addition to the discussions on open problems and unsolved challenges in image captioning.
Multiple Sclerosis Lesions Segmentation using Attention-Based CNNs in FLAIR Images
Jan 05, 2022
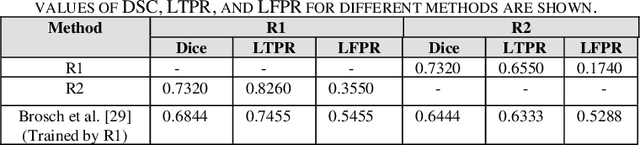

Objective: Multiple Sclerosis (MS) is an autoimmune, and demyelinating disease that leads to lesions in the central nervous system. This disease can be tracked and diagnosed using Magnetic Resonance Imaging (MRI). Up to now a multitude of multimodality automatic biomedical approaches is used to segment lesions which are not beneficial for patients in terms of cost, time, and usability. The authors of the present paper propose a method employing just one modality (FLAIR image) to segment MS lesions accurately. Methods: A patch-based Convolutional Neural Network (CNN) is designed, inspired by 3D-ResNet and spatial-channel attention module, to segment MS lesions. The proposed method consists of three stages: (1) the contrast-limited adaptive histogram equalization (CLAHE) is applied to the original images and concatenated to the extracted edges in order to create 4D images; (2) the patches of size 80 * 80 * 80 * 2 are randomly selected from the 4D images; and (3) the extracted patches are passed into an attention-based CNN which is used to segment the lesions. Finally, the proposed method was compared to previous studies of the same dataset. Results: The current study evaluates the model, with a test set of ISIB challenge data. Experimental results illustrate that the proposed approach significantly surpasses existing methods in terms of Dice similarity and Absolute Volume Difference while the proposed method use just one modality (FLAIR) to segment the lesions. Conclusions: The authors have introduced an automated approach to segment the lesions which is based on, at most, two modalities as an input. The proposed architecture is composed of convolution, deconvolution, and an SCA-VoxRes module as an attention module. The results show, the proposed method outperforms well compare to other methods.
Microaneurysm Detection in Fundus Images Using a Two-step Convolutional Neural Networks
Jul 08, 2018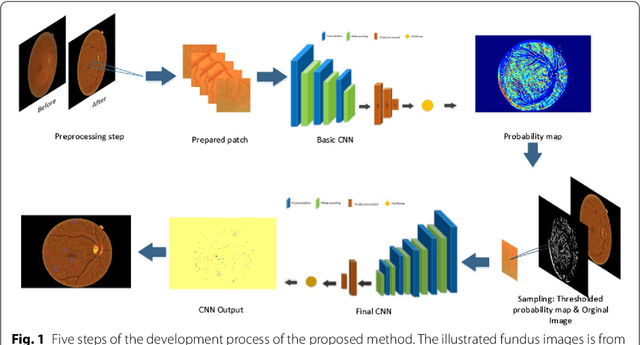
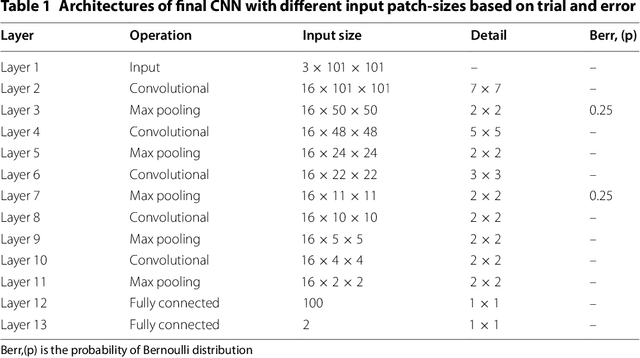
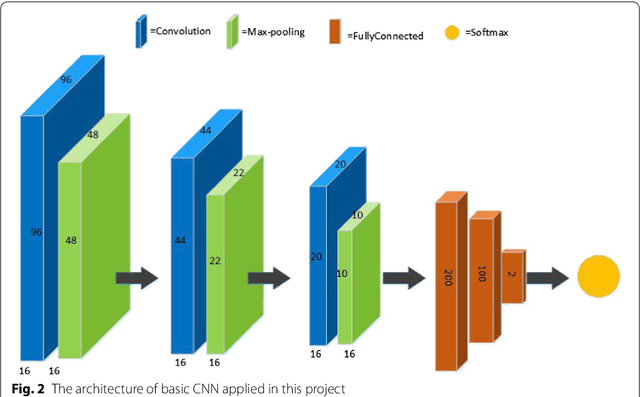
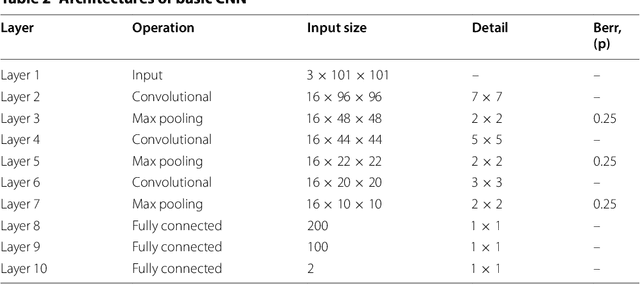
Diabetic Retinopathy (DR) is a prominent cause of blindness in the world. The early treatment of DR can be conducted from detection of microaneurysms (MAs) which appears as reddish spots in retinal images. An automated microaneurysm detection can be a helpful system for ophthalmologists. In this paper, deep learning, in particular convolutional neural network (CNN), is used as a powerful tool to efficiently detect MAs from fundus images. In our method a new technique is used to utilise a two-stage training process which results in an accurate detection, while decreasing computational complexity in comparison with previous works. To validate our proposed method, an experiment is conducted using Keras library to implement our proposed CNN on two standard publicly available datasets. Our results show a promising sensitivity value of about 0.8 at the average number of false positive per image greater than 6 which is a competitive value with the state-of-the-art approaches.
A dataset for Computer-Aided Detection of Pulmonary Embolism in CTA images
Jul 05, 2017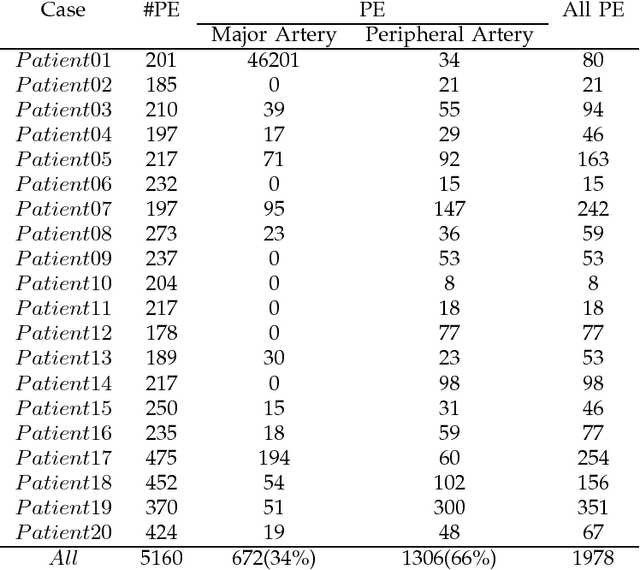
Todays, researchers in the field of Pulmonary Embolism (PE) analysis need to use a publicly available dataset to assess and compare their methods. Different systems have been designed for the detection of pulmonary embolism (PE), but none of them have used any public datasets. All papers have used their own private dataset. In order to fill this gap, we have collected 5160 slices of computed tomography angiography (CTA) images acquired from 20 patients, and after labeling the image by experts in this field, we provided a reliable dataset which is now publicly available. In some situation, PE detection can be difficult, for example when it occurs in the peripheral branches or when patients have pulmonary diseases (such as parenchymal disease). Therefore, the efficiency of CAD systems highly depends on the dataset. In the given dataset, 66% of PE are located in peripheral branches, and different pulmonary diseases are also included.
Towards the Application of Linear Programming Methods For Multi-Camera Pose Estimation
Dec 08, 2015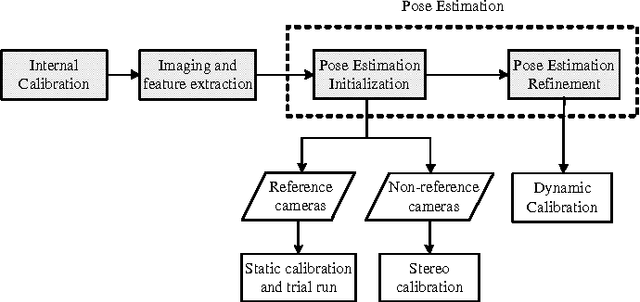
We presented a separation based optimization algorithm which, rather than optimization the entire variables altogether, This would allow us to employ: 1) a class of nonlinear functions with three variables and 2) a convex quadratic multivariable polynomial, for minimization of reprojection error. Neglecting the inversion required to minimize the nonlinear functions, in this paper we demonstrate how separation allows eradication of matrix inversion.