Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Step Towards Mixture of Grader: Statistical Analysis of Existing Automatic Evaluation Metrics
Oct 13, 2024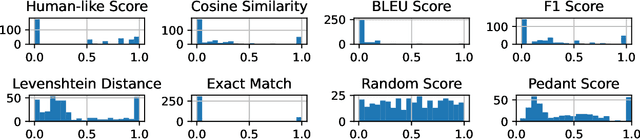
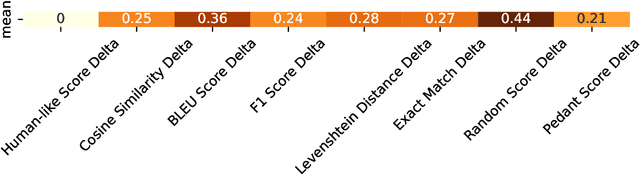
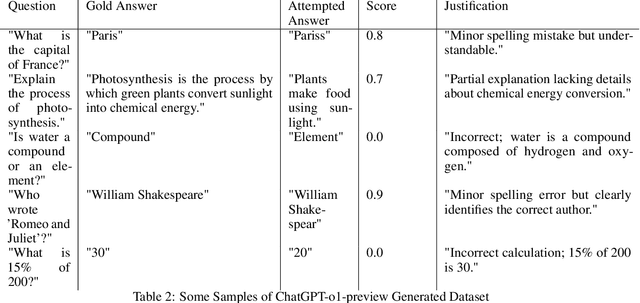
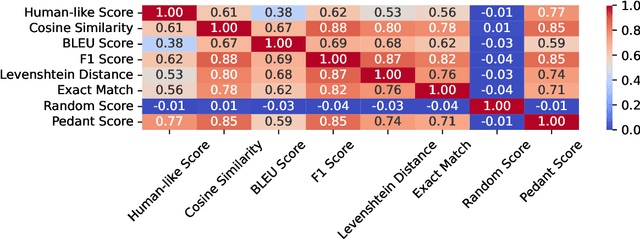
The explosion of open-sourced models and Question-Answering (QA) datasets emphasizes the importance of automated QA evaluation. We studied the statistics of the existing evaluation metrics for a better understanding of their limitations. By measuring the correlation coefficients of each evaluation metric concerning human-like evaluation score, we observed the following: (1) existing metrics have a high correlation among them concerning the question type (e.g., single word, single phrase, etc.), (2) no single metric can adequately estimate the human-like evaluation. As a potential solution, we discuss how a Mixture Of Grader could potentially improve the auto QA evaluator quality.
Via