 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Class Text Classification with Matching
Paper and Code
May 23, 2022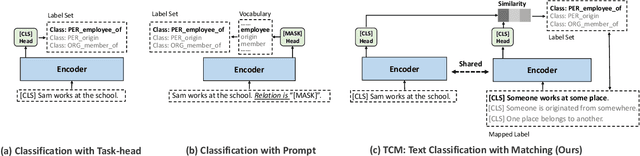


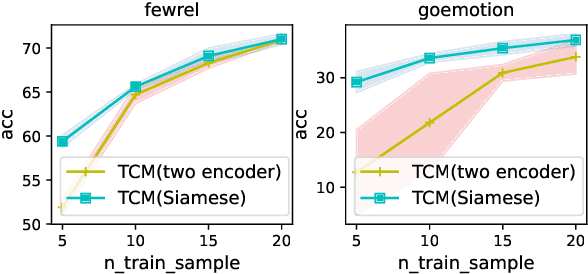
In this work, we formulate \textbf{T}ext \textbf{C}lassification as a \textbf{M}atching problem between the text and the labels, and propose a simple yet effective framework named TCM. Compared with previous text classification approaches, TCM takes advantage of the fine-grained semantic information of the classification labels, which helps distinguish each class better when the class number is large, especially in low-resource scenarios. TCM is also easy to implement and is compatible with various large pretrained language models. We evaluate TCM on 4 text classification datasets (each with 20+ labels) in both few-shot and full-data settings, and this model demonstrates significant improvements over other text classification paradigms. We also conduct extensive experiments with different variants of TCM and discuss the underlying factors of its success. Our method and analyses offer a new perspective on text classification.