 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Bias Detection in College Student Newspapers
Sep 11, 2023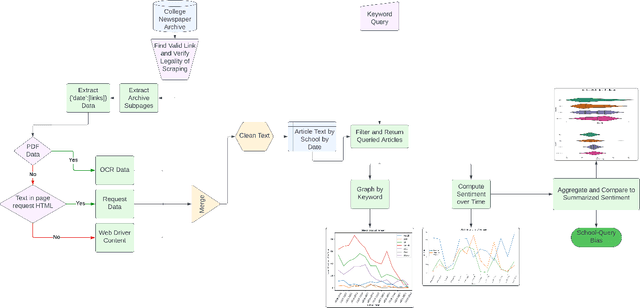
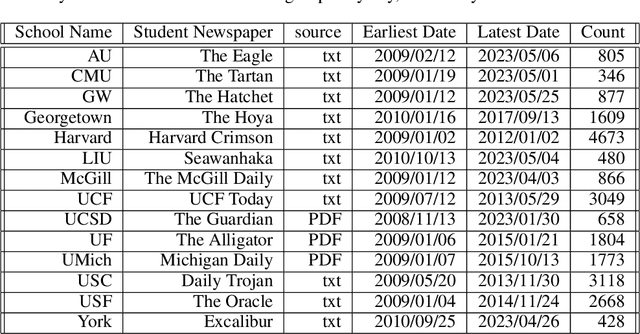
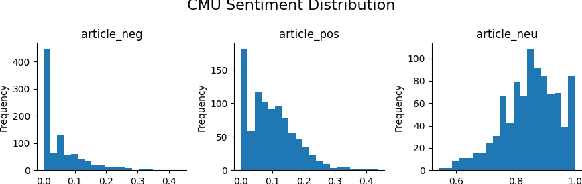
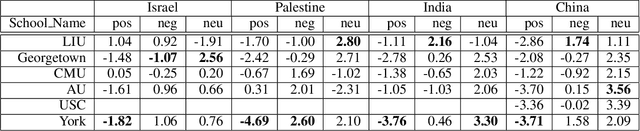
This paper presents a pipeline with minimal human influence for scraping and detecting bias on college newspaper archives. This paper introduces a framework for scraping complex archive sites that automated tools fail to grab data from, and subsequently generates a dataset of 14 student papers with 23,154 entries. This data can also then be queried by keyword to calculate bias by comparing the sentiment of a large language model summary to the original article. The advantages of this approach are that it is less comparative than reconstruction bias and requires less labelled data than generating keyword sentiment. Results are calculated on politically charged words as well as control words to show how conclusions can be drawn. The complete method facilitates the extraction of nuanced insights with minimal assumptions and categorizations, paving the way for a more objective understanding of bias within student newspaper sources.
RamseyRL: A Framework for Intelligent Ramsey Number Counterexample Searching
Aug 23, 2023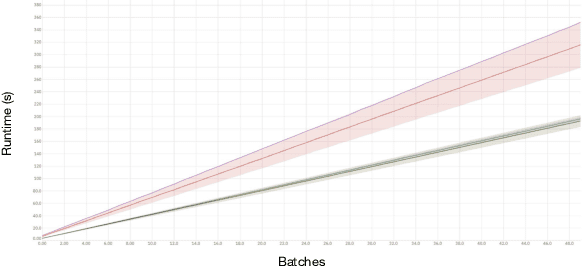
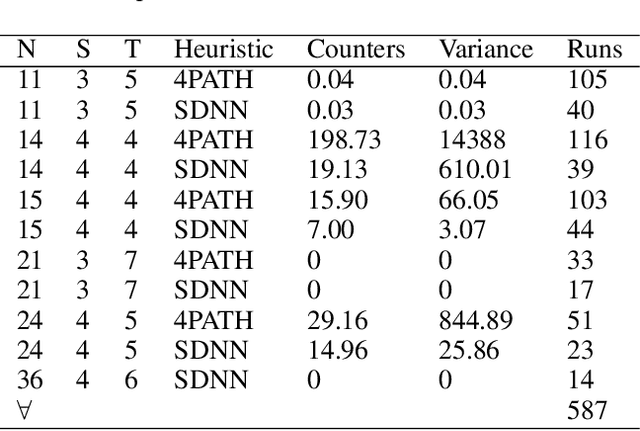
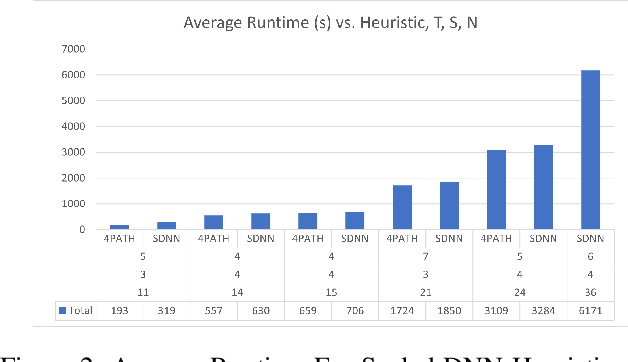
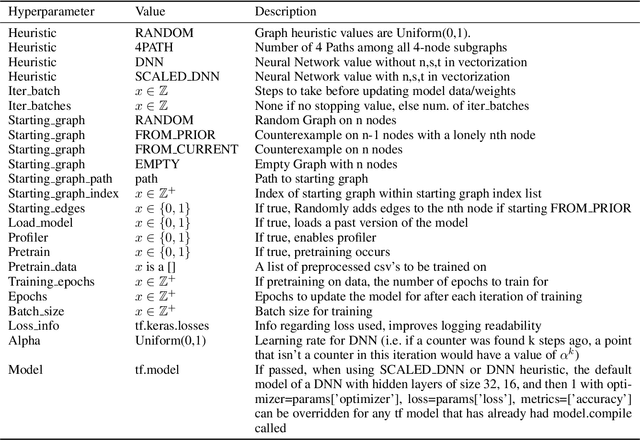
The Ramsey number is the minimum number of nodes, $n = R(s, t)$, such that all undirected simple graphs of order $n$, contain a clique of order $s$, or an independent set of order $t$. This paper explores the application of a best first search algorithm and reinforcement learning (RL) techniques to find counterexamples to specific Ramsey numbers. We incrementally improve over prior search methods such as random search by introducing a graph vectorization and deep neural network (DNN)-based heuristic, which gauge the likelihood of a graph being a counterexample. The paper also proposes algorithmic optimizations to confine a polynomial search runtime. This paper does not aim to present new counterexamples but rather introduces and evaluates a framework supporting Ramsey counterexample exploration using other heuristics. Code and methods are made available through a PyPI package and GitHub repository.
Feature Reduction Method Comparison Towards Explainability and Efficiency in Cybersecurity Intrusion Detection Systems
Mar 22, 2023In the realm of cybersecurity, intrusion detection systems (IDS) detect and prevent attacks based on collected computer and network data. In recent research, IDS models have been constructed using machine learning (ML) and deep learning (DL) methods such as Random Forest (RF) and deep neural networks (DNN). Feature selection (FS) can be used to construct faster, more interpretable, and more accurate models. We look at three different FS techniques; RF information gain (RF-IG), correlation feature selection using the Bat Algorithm (CFS-BA), and CFS using the Aquila Optimizer (CFS-AO). Our results show CFS-BA to be the most efficient of the FS methods, building in 55% of the time of the best RF-IG model while achieving 99.99% of its accuracy. This reinforces prior contributions attesting to CFS-BA's accuracy while building upon the relationship between subset size, CFS score, and RF-IG score in final results.
* Published in 2022 21st IEEE International Conference on Machine Learning and Applications. 8 pages. 5 figures