 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Bias Detection in College Student Newspapers
Sep 11, 2023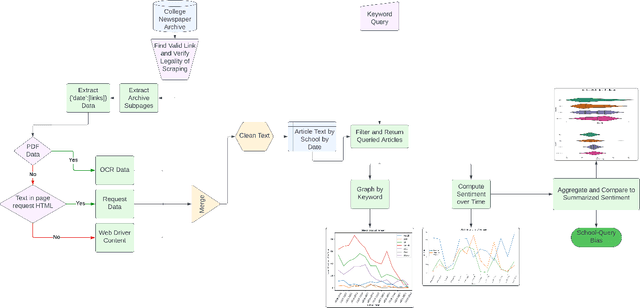
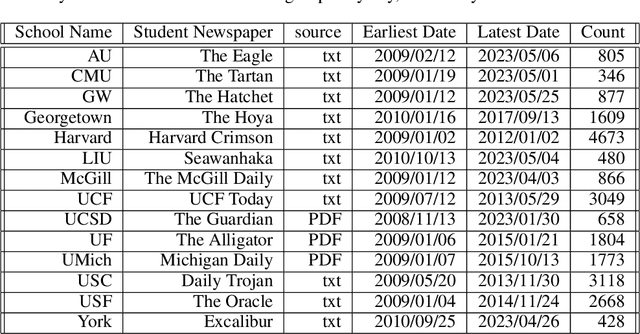
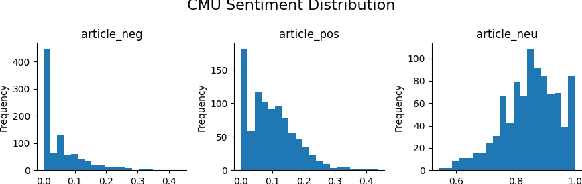
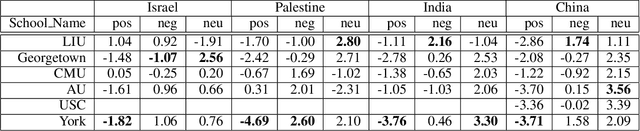
This paper presents a pipeline with minimal human influence for scraping and detecting bias on college newspaper archives. This paper introduces a framework for scraping complex archive sites that automated tools fail to grab data from, and subsequently generates a dataset of 14 student papers with 23,154 entries. This data can also then be queried by keyword to calculate bias by comparing the sentiment of a large language model summary to the original article. The advantages of this approach are that it is less comparative than reconstruction bias and requires less labelled data than generating keyword sentiment. Results are calculated on politically charged words as well as control words to show how conclusions can be drawn. The complete method facilitates the extraction of nuanced insights with minimal assumptions and categorizations, paving the way for a more objective understanding of bias within student newspaper sources.