 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT: Molecularly Informed Training with Spatial Transcriptomics Supervision for Pathology Foundation Models
Mar 09, 2026Pathology foundation models learn morphological representations through self-supervised pretraining on large-scale whole-slide images, yet they do not explicitly capture the underlying molecular state of the tissue. Spatial transcriptomics technologies bridge this gap by measuring gene expression in situ, offering a natural cross-modal supervisory signal. We propose MINT (Molecularly Informed Training), a fine-tuning framework that incorporates spatial transcriptomics supervision into pretrained pathology Vision Transformers. MINT appends a learnable ST token to the ViT input to encode transcriptomic information separately from the morphological CLS token, preventing catastrophic forgetting through DINO self-distillation and explicit feature anchoring to the frozen pretrained encoder. Gene expression regression at both spot-level (Visium) and patch-level (Xenium) resolutions provides complementary supervision across spatial scales. Trained on 577 publicly available HEST samples, MINT achieves the best overall performance on both HEST-Bench for gene expression prediction (mean Pearson r = 0.440) and EVA for general pathology tasks (0.803), demonstrating that spatial transcriptomics supervision complements morphology-centric self-supervised pretraining.
EXAONE Path 2.5: Pathology Foundation Model with Multi-Omics Alignment
Dec 16, 2025Cancer progression arises from interactions across multiple biological layers, especially beyond morphological and across molecular layers that remain invisible to image-only models. To capture this broader biological landscape, we present EXAONE Path 2.5, a pathology foundation model that jointly models histologic, genomic, epigenetic and transcriptomic modalities, producing an integrated patient representation that reflects tumor biology more comprehensively. Our approach incorporates three key components: (1) multimodal SigLIP loss enabling all-pairwise contrastive learning across heterogeneous modalities, (2) a fragment-aware rotary positional encoding (F-RoPE) module that preserves spatial structure and tissue-fragment topology in WSI, and (3) domain-specialized internal foundation models for both WSI and RNA-seq to provide biologically grounded embeddings for robust multimodal alignment. We evaluate EXAONE Path 2.5 against six leading pathology foundation models across two complementary benchmarks: an internal real-world clinical dataset and the Patho-Bench benchmark covering 80 tasks. Our framework demonstrates high data and parameter efficiency, achieving on-par performance with state-of-the-art foundation models on Patho-Bench while exhibiting the highest adaptability in the internal clinical setting. These results highlight the value of biologically informed multimodal design and underscore the potential of integrated genotype-to-phenotype modeling for next-generation precision oncology.
EXAONE Path 2.0: Pathology Foundation Model with End-to-End Supervision
Jul 09, 2025In digital pathology, whole-slide images (WSIs) are often difficult to handle due to their gigapixel scale, so most approaches train patch encoders via self-supervised learning (SSL) and then aggregate the patch-level embeddings via multiple instance learning (MIL) or slide encoders for downstream tasks. However, patch-level SSL may overlook complex domain-specific features that are essential for biomarker prediction, such as mutation status and molecular characteristics, as SSL methods rely only on basic augmentations selected for natural image domains on small patch-level area. Moreover, SSL methods remain less data efficient than fully supervised approaches, requiring extensive computational resources and datasets to achieve competitive performance. To address these limitations, we present EXAONE Path 2.0, a pathology foundation model that learns patch-level representations under direct slide-level supervision. Using only 37k WSIs for training, EXAONE Path 2.0 achieves state-of-the-art average performance across 10 biomarker prediction tasks, demonstrating remarkable data efficiency.
Enhancing Whole Slide Pathology Foundation Models through Stain Normalization
Aug 05, 2024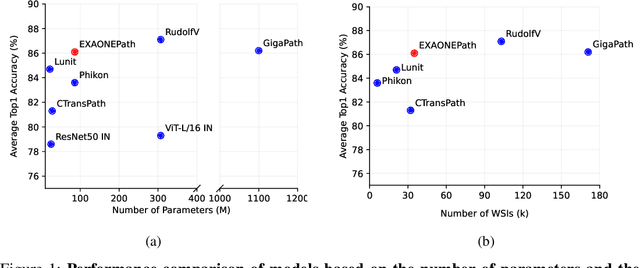
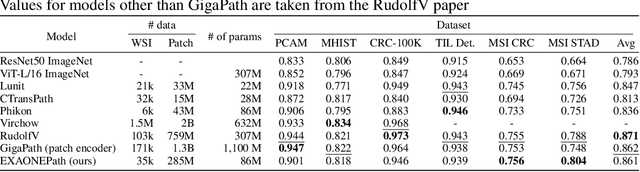
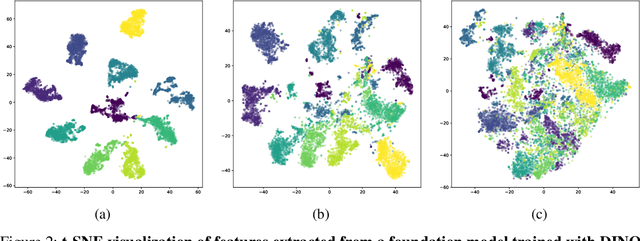
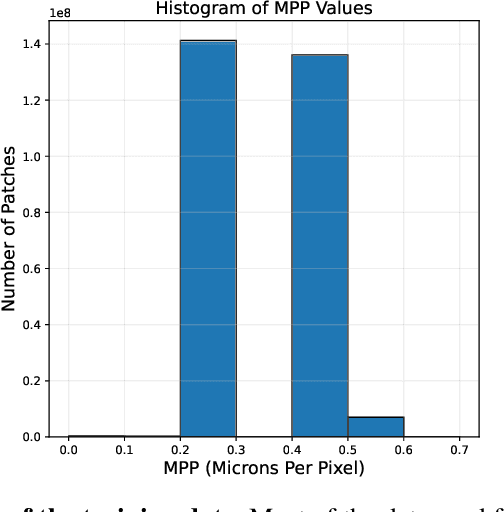
Recent advancements in digital pathology have led to the development of numerous foundational models that utilize self-supervised learning on patches extracted from gigapixel whole slide images (WSIs). While this approach leverages vast amounts of unlabeled data, we have discovered a significant issue: features extracted from these self-supervised models tend to cluster by individual WSIs, a phenomenon we term WSI-specific feature collapse. This problem can potentially limit the model's generalization ability and performance on various downstream tasks. To address this issue, we introduce Stain Normalized Pathology Foundational Model, a novel foundational model trained on patches that have undergone stain normalization. Stain normalization helps reduce color variability arising from different laboratories and scanners, enabling the model to learn more consistent features. Stain Normalized Pathology Foundational Model is trained using 285,153,903 patches extracted from a total of 34,795 WSIs, combining data from The Cancer Genome Atlas (TCGA) and the Genotype-Tissue Expression (GTEx) project. Our experiments demonstrate that Stain Normalized Pathology Foundational Model significantly mitigates the feature collapse problem, indicating that the model has learned more generalized features rather than overfitting to individual WSI characteristics. We compared Stain Normalized Pathology Foundational Model with state-of-the-art models across six downstream task datasets, and our results show that Stain Normalized Pathology Foundational Model achieves excellent performance relative to the number of WSIs used and the model's parameter count. This suggests that the application of stain normalization has substantially improved the model's efficiency and generalization capabilities.
Joint Negative and Positive Learning for Noisy Labels
Apr 14, 2021
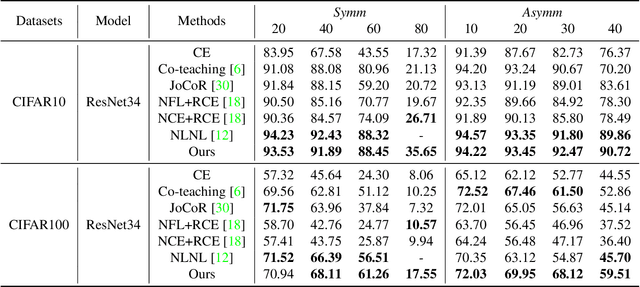
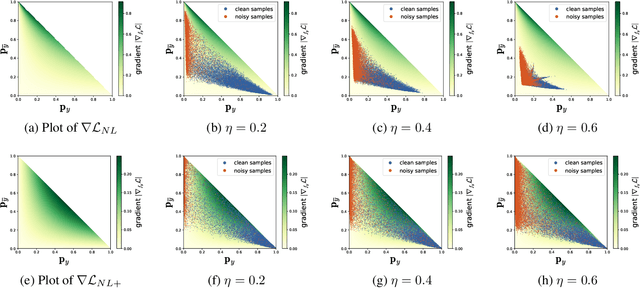
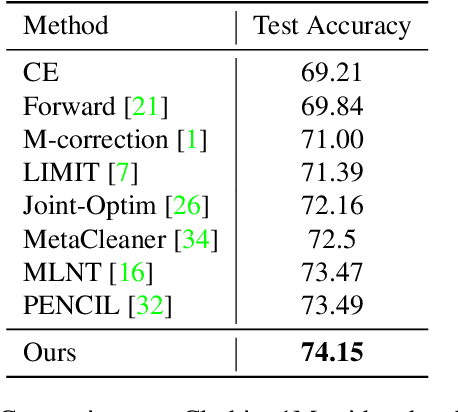
Training of Convolutional Neural Networks (CNNs) with data with noisy labels is known to be a challenge. Based on the fact that directly providing the label to the data (Positive Learning; PL) has a risk of allowing CNNs to memorize the contaminated labels for the case of noisy data, the indirect learning approach that uses complementary labels (Negative Learning for Noisy Labels; NLNL) has proven to be highly effective in preventing overfitting to noisy data as it reduces the risk of providing faulty target. NLNL further employs a three-stage pipeline to improve convergence. As a result, filtering noisy data through the NLNL pipeline is cumbersome, increasing the training cost. In this study, we propose a novel improvement of NLNL, named Joint Negative and Positive Learning (JNPL), that unifies the filtering pipeline into a single stage. JNPL trains CNN via two losses, NL+ and PL+, which are improved upon NL and PL loss functions, respectively. We analyze the fundamental issue of NL loss function and develop new NL+ loss function producing gradient that enhances the convergence of noisy data. Furthermore, PL+ loss function is designed to enable faster convergence to expected-to-be-clean data. We show that the NL+ and PL+ train CNN simultaneously, significantly simplifying the pipeline, allowing greater ease of practical use compared to NLNL. With a simple semi-supervised training technique, our method achieves state-of-the-art accuracy for noisy data classification based on the superior filtering ability.
NLNL: Negative Learning for Noisy Labels
Aug 19, 2019

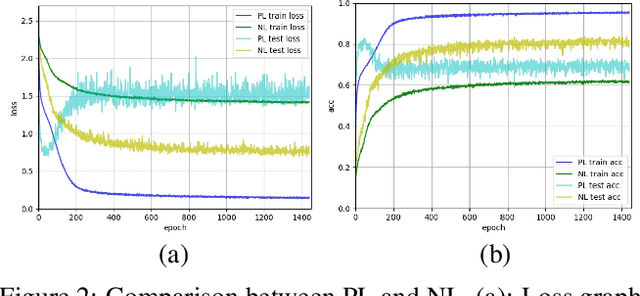
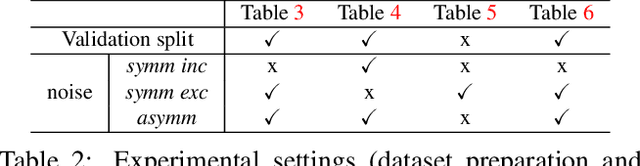
Convolutional Neural Networks (CNNs) provide excellent performance when used for image classification. The classical method of training CNNs is by labeling images in a supervised manner as in "input image belongs to this label" (Positive Learning; PL), which is a fast and accurate method if the labels are assigned correctly to all images. However, if inaccurate labels, or noisy labels, exist, training with PL will provide wrong information, thus severely degrading performance. To address this issue, we start with an indirect learning method called Negative Learning (NL), in which the CNNs are trained using a complementary label as in "input image does not belong to this complementary label." Because the chances of selecting a true label as a complementary label are low, NL decreases the risk of providing incorrect information. Furthermore, to improve convergence, we extend our method by adopting PL selectively, termed as Selective Negative Learning and Positive Learning (SelNLPL). PL is used selectively to train upon expected-to-be-clean data, whose choices become possible as NL progresses, thus resulting in superior performance of filtering out noisy data. With simple semi-supervised training technique, our method achieves state-of-the-art accuracy for noisy data classification, proving the superiority of SelNLPL's noisy data filtering ability.