 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSpector: Towards Universal Open-set Defect Recognition via Spectral-Contrastive Visual Prompting
Apr 03, 2026Although industrial inspection systems should be capable of recognizing unprecedented defects, most existing approaches operate under a closed-set assumption, which prevents them from detecting novel anomalies. While visual prompting offers a scalable alternative for industrial inspection, existing methods often suffer from prompt embedding collapse due to high intra-class variance and subtle inter-class differences. To resolve this, we propose UniSpector, which shifts the focus from naive prompt-to-region matching to the principled design of a semantically structured and transferable prompt topology. UniSpector employs the Spatial-Spectral Prompt Encoder to extract orientation-invariant, fine-grained representations; these serve as a solid basis for the Contrastive Prompt Encoder to explicitly regularize the prompt space into a semantically organized angular manifold. Additionally, Prompt-guided Query Selection generates adaptive object queries aligned with the prompt. We introduce Inspect Anything, the first benchmark for visual-prompt-based open-set defect localization, where UniSpector significantly outperforms baselines by at least 19.7% and 15.8% in AP50b and AP50m, respectively. These results show that our method enable a scalable, retraining-free inspection paradigm for continuously evolving industrial environments, while offering critical insights into the design of generic visual prompting.
Confidence Score for Source-Free Unsupervised Domain Adaptation
Jun 14, 2022
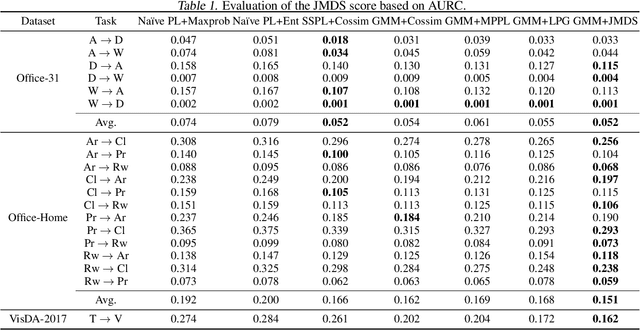
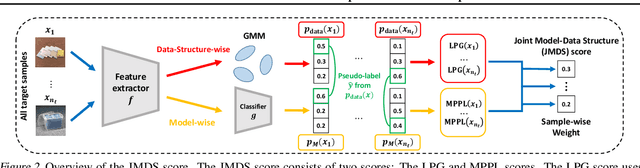
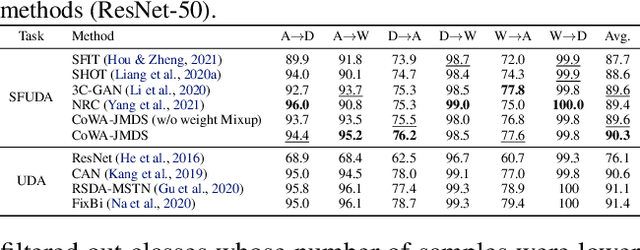
Source-free unsupervised domain adaptation (SFUDA) aims to obtain high performance in the unlabeled target domain using the pre-trained source model, not the source data. Existing SFUDA methods assign the same importance to all target samples, which is vulnerable to incorrect pseudo-labels. To differentiate between sample importance, in this study, we propose a novel sample-wise confidence score, the Joint Model-Data Structure (JMDS) score for SFUDA. Unlike existing confidence scores that use only one of the source or target domain knowledge, the JMDS score uses both knowledge. We then propose a Confidence score Weighting Adaptation using the JMDS (CoWA-JMDS) framework for SFUDA. CoWA-JMDS consists of the JMDS scores as sample weights and weight Mixup that is our proposed variant of Mixup. Weight Mixup promotes the model make more use of the target domain knowledge. The experimental results show that the JMDS score outperforms the existing confidence scores. Moreover, CoWA-JMDS achieves state-of-the-art performance on various SFUDA scenarios: closed, open, and partial-set scenarios.
Hyperparameter Optimization with Neural Network Pruning
May 18, 2022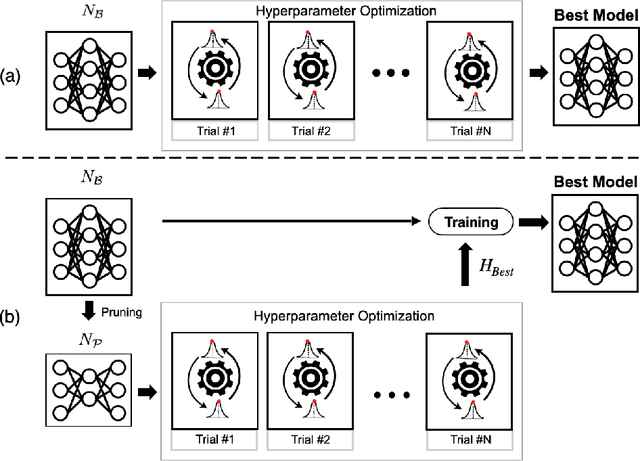
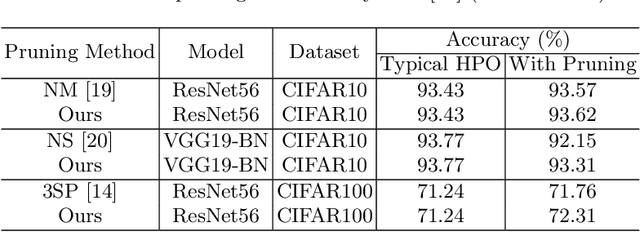

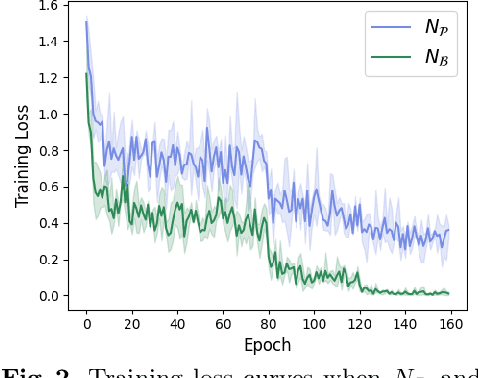
Since the deep learning model is highly dependent on hyperparameters, hyperparameter optimization is essential in developing deep learning model-based applications, even if it takes a long time. As service development using deep learning models has gradually become competitive, many developers highly demand rapid hyperparameter optimization algorithms. In order to keep pace with the needs of faster hyperparameter optimization algorithms, researchers are focusing on improving the speed of hyperparameter optimization algorithm. However, the huge time consumption of hyperparameter optimization due to the high computational cost of the deep learning model itself has not been dealt with in-depth. Like using surrogate model in Bayesian optimization, to solve this problem, it is necessary to consider proxy model for a neural network (N_B) to be used for hyperparameter optimization. Inspired by the main goal of neural network pruning, i.e., high computational cost reduction and performance preservation, we presumed that the neural network (N_P) obtained through neural network pruning would be a good proxy model of N_B. In order to verify our idea, we performed extensive experiments by using CIFAR10, CFIAR100, and TinyImageNet datasets and three generally-used neural networks and three representative hyperparameter optmization methods. Through these experiments, we verified that N_P can be a good proxy model of N_B for rapid hyperparameter optimization. The proposed hyperparameter optimization framework can reduce the amount of time up to 37%.
Highway Driving Dataset for Semantic Video Segmentation
Nov 02, 2020
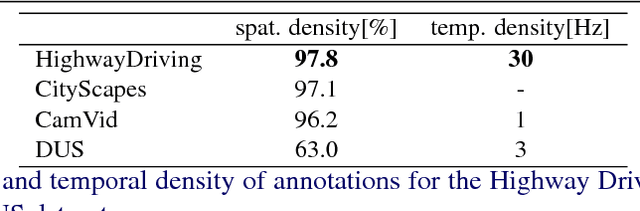
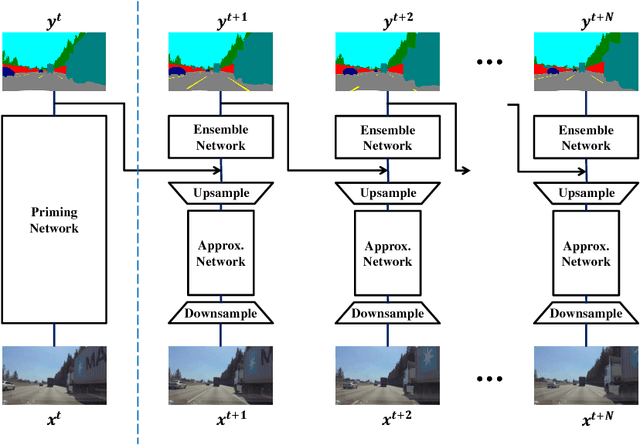
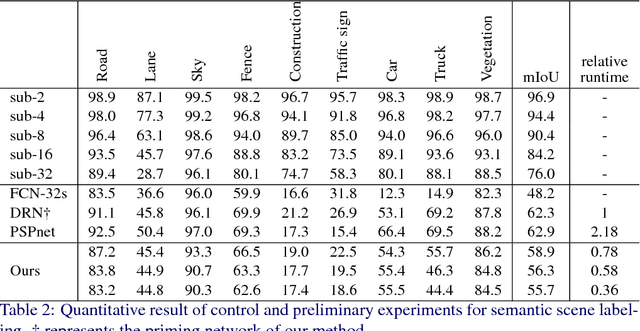
Scene understanding is an essential technique in semantic segmentation. Although there exist several datasets that can be used for semantic segmentation, they are mainly focused on semantic image segmentation with large deep neural networks. Therefore, these networks are not useful for real time applications, especially in autonomous driving systems. In order to solve this problem, we make two contributions to semantic segmentation task. The first contribution is that we introduce the semantic video dataset, the Highway Driving dataset, which is a densely annotated benchmark for a semantic video segmentation task. The Highway Driving dataset consists of 20 video sequences having a 30Hz frame rate, and every frame is densely annotated. Secondly, we propose a baseline algorithm that utilizes a temporal correlation. Together with our attempt to analyze the temporal correlation, we expect the Highway Driving dataset to encourage research on semantic video segmentation.
NLNL: Negative Learning for Noisy Labels
Aug 19, 2019

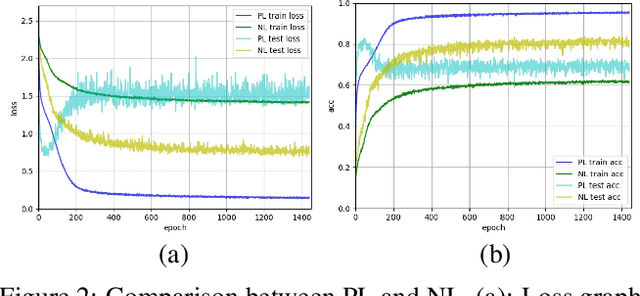
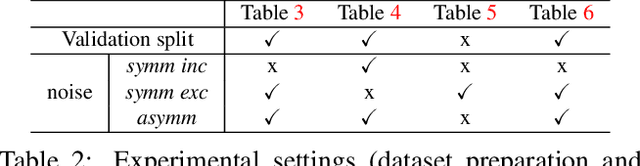
Convolutional Neural Networks (CNNs) provide excellent performance when used for image classification. The classical method of training CNNs is by labeling images in a supervised manner as in "input image belongs to this label" (Positive Learning; PL), which is a fast and accurate method if the labels are assigned correctly to all images. However, if inaccurate labels, or noisy labels, exist, training with PL will provide wrong information, thus severely degrading performance. To address this issue, we start with an indirect learning method called Negative Learning (NL), in which the CNNs are trained using a complementary label as in "input image does not belong to this complementary label." Because the chances of selecting a true label as a complementary label are low, NL decreases the risk of providing incorrect information. Furthermore, to improve convergence, we extend our method by adopting PL selectively, termed as Selective Negative Learning and Positive Learning (SelNLPL). PL is used selectively to train upon expected-to-be-clean data, whose choices become possible as NL progresses, thus resulting in superior performance of filtering out noisy data. With simple semi-supervised training technique, our method achieves state-of-the-art accuracy for noisy data classification, proving the superiority of SelNLPL's noisy data filtering ability.