 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjusting Decision Boundary for Class Imbalanced Learning
Paper and Code
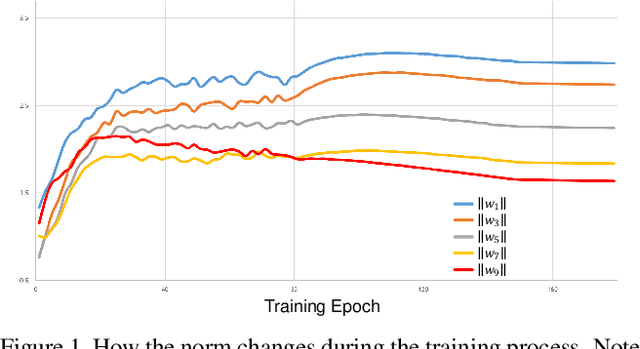
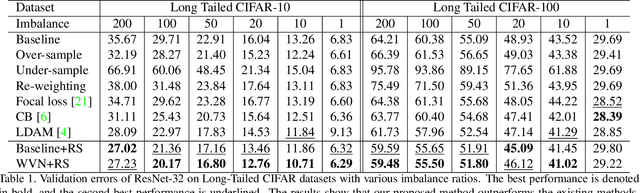
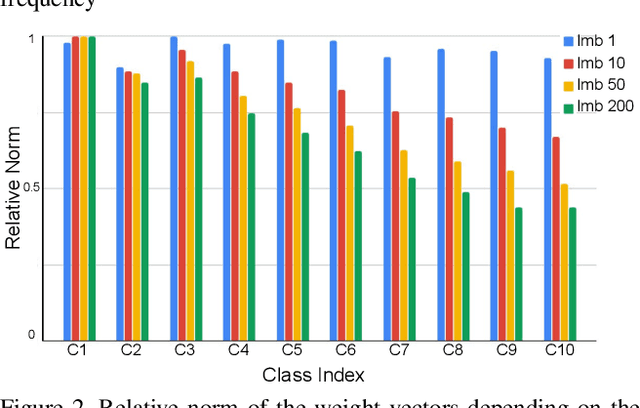
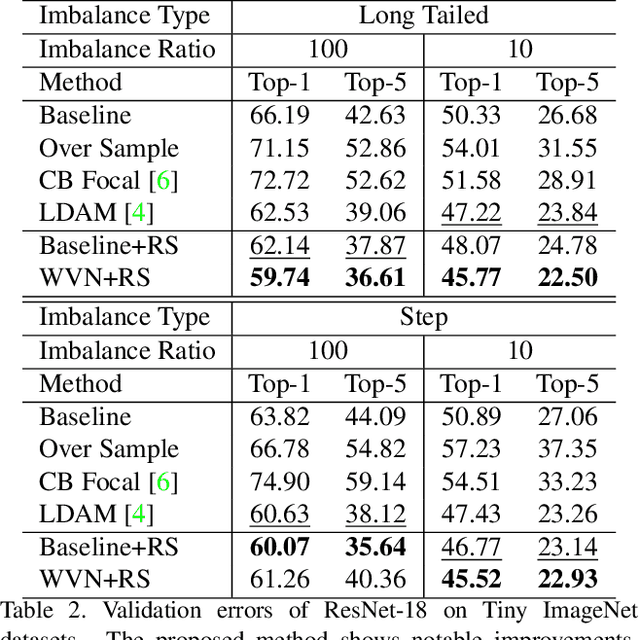
Training of deep neural networks heavily depends on the data distribution. In particular, the networks easily suffer from class imbalance. The trained networks would recognize the frequent classes better than the infrequent classes. To resolve this problem, existing approaches typically propose novel loss functions to obtain better feature embedding. In this paper, we argue that drawing a better decision boundary is as important as learning better features. Inspired by observations, we investigate how the class imbalance affects the decision boundary and deteriorates the performance. We also investigate the feature distributional discrepancy between training and test time. As a result, we propose a novel, yet simple method for class imbalanced learning. Despite its simplicity, our method shows outstanding performance. In particular, the experimental results show that we can significantly improve the network by scaling the weight vectors, even without additional training process.