 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLP Data Pipeline: Lightweight, Purpose-driven Data Pipeline for Large Language Models
Nov 18, 2024Creating high-quality, large-scale datasets for large language models (LLMs) often relies on resource-intensive, GPU-accelerated models for quality filtering, making the process time-consuming and costly. This dependence on GPUs limits accessibility for organizations lacking significant computational infrastructure. To address this issue, we introduce the Lightweight, Purpose-driven (LP) Data Pipeline, a framework that operates entirely on CPUs to streamline the processes of dataset extraction, filtering, and curation. Based on our four core principles, the LP Data Pipeline significantly reduces preparation time and cost while maintaining high data quality. Importantly, our pipeline enables the creation of purpose-driven datasets tailored to specific domains and languages, enhancing the applicability of LLMs in specialized contexts. We anticipate that our pipeline will lower the barriers to LLM development, enabling a wide range of organizations to access LLMs more easily.
1 Trillion Token (1TT) Platform: A Novel Framework for Efficient Data Sharing and Compensation in Large Language Models
Sep 30, 2024

In this paper, we propose the 1 Trillion Token Platform (1TT Platform), a novel framework designed to facilitate efficient data sharing with a transparent and equitable profit-sharing mechanism. The platform fosters collaboration between data contributors, who provide otherwise non-disclosed datasets, and a data consumer, who utilizes these datasets to enhance their own services. Data contributors are compensated in monetary terms, receiving a share of the revenue generated by the services of the data consumer. The data consumer is committed to sharing a portion of the revenue with contributors, according to predefined profit-sharing arrangements. By incorporating a transparent profit-sharing paradigm to incentivize large-scale data sharing, the 1TT Platform creates a collaborative environment to drive the advancement of NLP and LLM technologies.
Rethinking KenLM: Good and Bad Model Ensembles for Efficient Text Quality Filtering in Large Web Corpora
Sep 15, 2024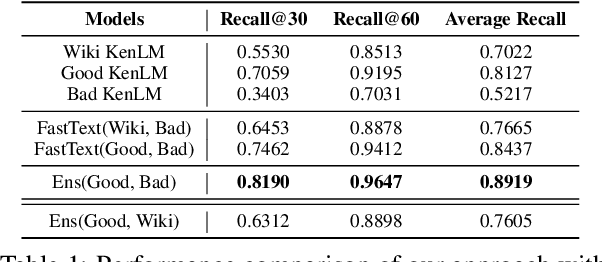
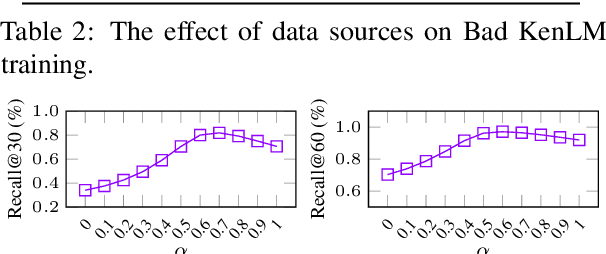
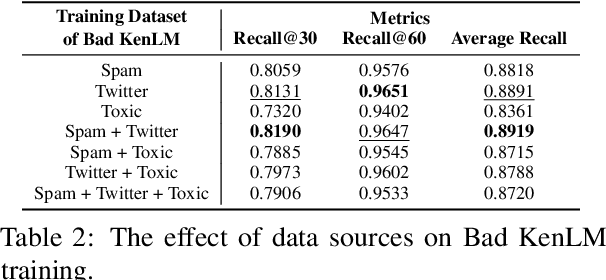

With the increasing demand for substantial amounts of high-quality data to train large language models (LLMs), efficiently filtering large web corpora has become a critical challenge. For this purpose, KenLM, a lightweight n-gram-based language model that operates on CPUs, is widely used. However, the traditional method of training KenLM utilizes only high-quality data and, consequently, does not explicitly learn the linguistic patterns of low-quality data. To address this issue, we propose an ensemble approach that leverages two contrasting KenLMs: (i) Good KenLM, trained on high-quality data; and (ii) Bad KenLM, trained on low-quality data. Experimental results demonstrate that our approach significantly reduces noisy content while preserving high-quality content compared to the traditional KenLM training method. This indicates that our method can be a practical solution with minimal computational overhead for resource-constrained environments.