 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing unsupervised learning to improve sward content prediction and herbage mass estimation
Apr 20, 2022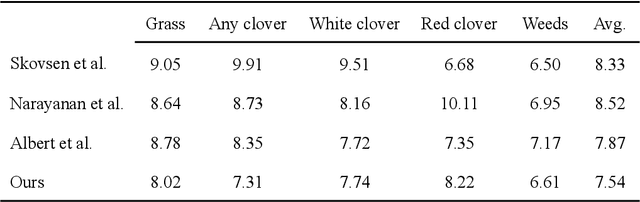
Sward species composition estimation is a tedious one. Herbage must be collected in the field, manually separated into components, dried and weighed to estimate species composition. Deep learning approaches using neural networks have been used in previous work to propose faster and more cost efficient alternatives to this process by estimating the biomass information from a picture of an area of pasture alone. Deep learning approaches have, however, struggled to generalize to distant geographical locations and necessitated further data collection to retrain and perform optimally in different climates. In this work, we enhance the deep learning solution by reducing the need for ground-truthed (GT) images when training the neural network. We demonstrate how unsupervised contrastive learning can be used in the sward composition prediction problem and compare with the state-of-the-art on the publicly available GrassClover dataset collected in Denmark as well as a more recent dataset from Ireland where we tackle herbage mass and height estimation.
Unsupervised domain adaptation and super resolution on drone images for autonomous dry herbage biomass estimation
Apr 18, 2022


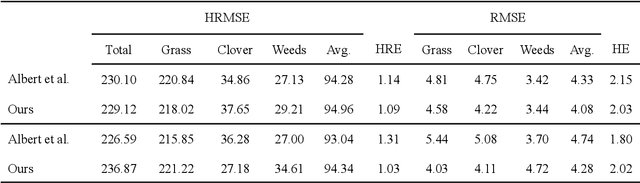
Herbage mass yield and composition estimation is an important tool for dairy farmers to ensure an adequate supply of high quality herbage for grazing and subsequently milk production. By accurately estimating herbage mass and composition, targeted nitrogen fertiliser application strategies can be deployed to improve localised regions in a herbage field, effectively reducing the negative impacts of over-fertilization on biodiversity and the environment. In this context, deep learning algorithms offer a tempting alternative to the usual means of sward composition estimation, which involves the destructive process of cutting a sample from the herbage field and sorting by hand all plant species in the herbage. The process is labour intensive and time consuming and so not utilised by farmers. Deep learning has been successfully applied in this context on images collected by high-resolution cameras on the ground. Moving the deep learning solution to drone imaging, however, has the potential to further improve the herbage mass yield and composition estimation task by extending the ground-level estimation to the large surfaces occupied by fields/paddocks. Drone images come at the cost of lower resolution views of the fields taken from a high altitude and requires further herbage ground-truth collection from the large surfaces covered by drone images. This paper proposes to transfer knowledge learned on ground-level images to raw drone images in an unsupervised manner. To do so, we use unpaired image style translation to enhance the resolution of drone images by a factor of eight and modify them to appear closer to their ground-level counterparts. We then ... ~\url{www.github.com/PaulAlbert31/Clover_SSL}.
Semi-supervised dry herbage mass estimation using automatic data and synthetic images
Oct 26, 2021



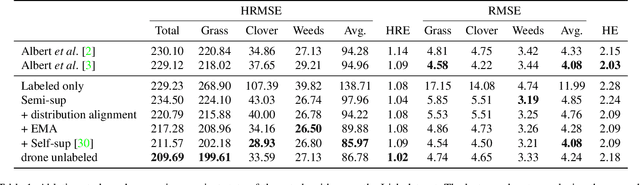
Monitoring species-specific dry herbage biomass is an important aspect of pasture-based milk production systems. Being aware of the herbage biomass in the field enables farmers to manage surpluses and deficits in herbage supply, as well as using targeted nitrogen fertilization when necessary. Deep learning for computer vision is a powerful tool in this context as it can accurately estimate the dry biomass of a herbage parcel using images of the grass canopy taken using a portable device. However, the performance of deep learning comes at the cost of an extensive, and in this case destructive, data gathering process. Since accurate species-specific biomass estimation is labor intensive and destructive for the herbage parcel, we propose in this paper to study low supervision approaches to dry biomass estimation using computer vision. Our contributions include: a synthetic data generation algorithm to generate data for a herbage height aware semantic segmentation task, an automatic process to label data using semantic segmentation maps, and a robust regression network trained to predict dry biomass using approximate biomass labels and a small trusted dataset with gold standard labels. We design our approach on a herbage mass estimation dataset collected in Ireland and also report state-of-the-art results on the publicly released Grass-Clover biomass estimation dataset from Denmark. Our code is available at https://git.io/J0L2a
Extracting Pasture Phenotype and Biomass Percentages using Weakly Supervised Multi-target Deep Learning on a Small Dataset
Jan 08, 2021


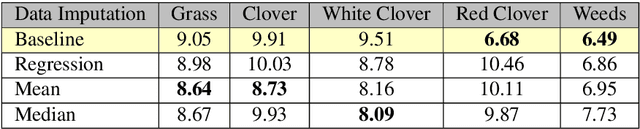
The dairy industry uses clover and grass as fodder for cows. Accurate estimation of grass and clover biomass yield enables smart decisions in optimizing fertilization and seeding density, resulting in increased productivity and positive environmental impact. Grass and clover are usually planted together, since clover is a nitrogen-fixing plant that brings nutrients to the soil. Adjusting the right percentages of clover and grass in a field reduces the need for external fertilization. Existing approaches for estimating the grass-clover composition of a field are expensive and time consuming - random samples of the pasture are clipped and then the components are physically separated to weigh and calculate percentages of dry grass, clover and weeds in each sample. There is growing interest in developing novel deep learning based approaches to non-destructively extract pasture phenotype indicators and biomass yield predictions of different plant species from agricultural imagery collected from the field. Providing these indicators and predictions from images alone remains a significant challenge. Heavy occlusions in the dense mixture of grass, clover and weeds make it difficult to estimate each component accurately. Moreover, although supervised deep learning models perform well with large datasets, it is tedious to acquire large and diverse collections of field images with precise ground truth for different biomass yields. In this paper, we demonstrate that applying data augmentation and transfer learning is effective in predicting multi-target biomass percentages of different plant species, even with a small training dataset. The scheme proposed in this paper used a training set of only 261 images and provided predictions of biomass percentages of grass, clover, white clover, red clover, and weeds with mean absolute error of 6.77%, 6.92%, 6.21%, 6.89%, and 4.80% respectively.
Machine Learning Prediction of Accurate Atomization Energies of Organic Molecules from Low-Fidelity Quantum Chemical Calculations
Jun 07, 2019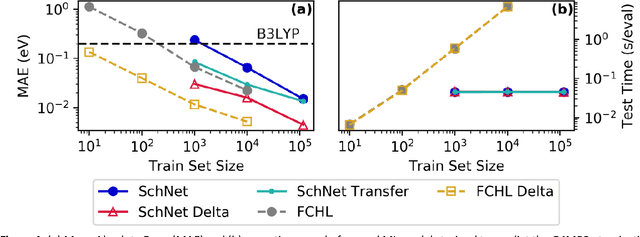
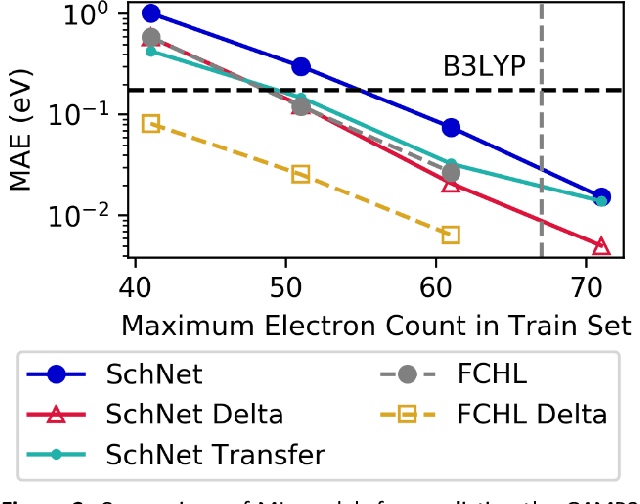
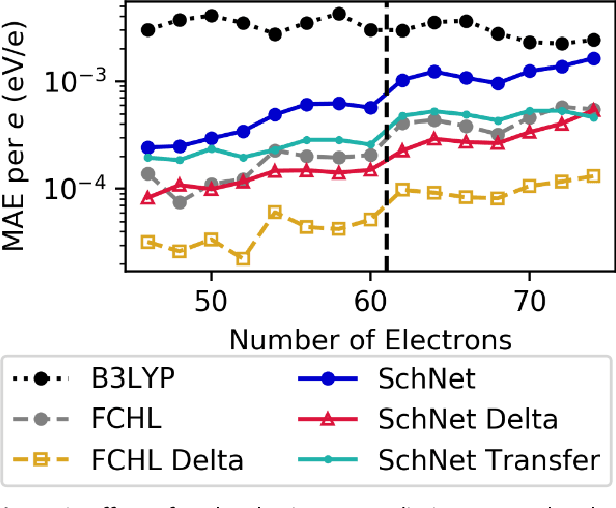
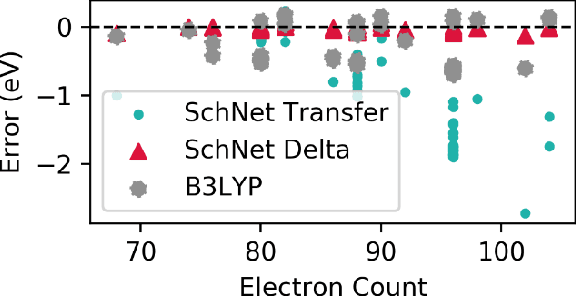
Recent studies illustrate how machine learning (ML) can be used to bypass a core challenge of molecular modeling: the tradeoff between accuracy and computational cost. Here, we assess multiple ML approaches for predicting the atomization energy of organic molecules. Our resulting models learn the difference between low-fidelity, B3LYP, and high-accuracy, G4MP2, atomization energies, and predict the G4MP2 atomization energy to 0.005 eV (mean absolute error) for molecules with less than 9 heavy atoms and 0.012 eV for a small set of molecules with between 10 and 14 heavy atoms. Our two best models, which have different accuracy/speed tradeoffs, enable the efficient prediction of G4MP2-level energies for large molecules and are available through a simple web interface.