 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Computing Wasserstein Barycenters through Gradient Flows
Oct 06, 2025Wasserstein barycenters provide a powerful tool for aggregating probability measures, while leveraging the geometry of their ambient space. Existing discrete methods suffer from poor scalability, as they require access to the complete set of samples from input measures. We address this issue by recasting the original barycenter problem as a gradient flow in the Wasserstein space. Our approach offers two advantages. First, we achieve scalability by sampling mini-batches from the input measures. Second, we incorporate functionals over probability measures, which regularize the barycenter problem through internal, potential, and interaction energies. We present two algorithms for empirical and Gaussian mixture measures, providing convergence guarantees under the Polyak-{\L}ojasiewicz inequality. Experimental validation on toy datasets and domain adaptation benchmarks show that our methods outperform previous discrete and neural net-based methods for computing Wasserstein barycenters.
ProKeR: A Kernel Perspective on Few-Shot Adaptation of Large Vision-Language Models
Jan 19, 2025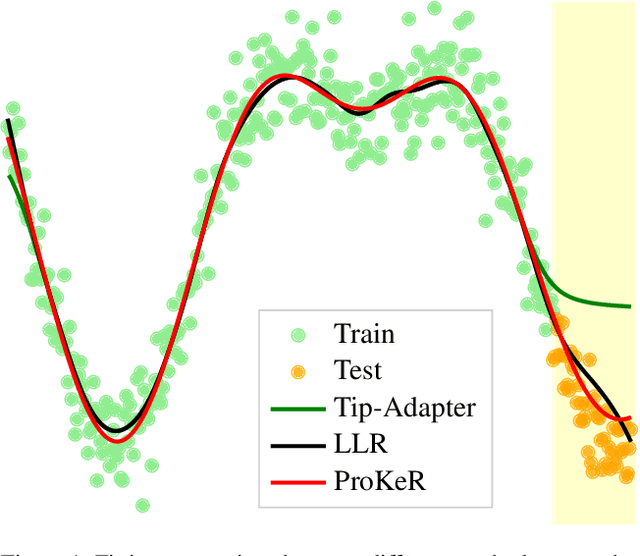
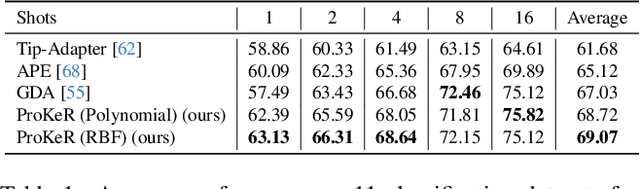
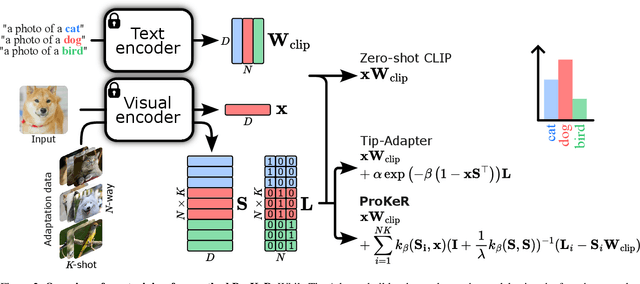
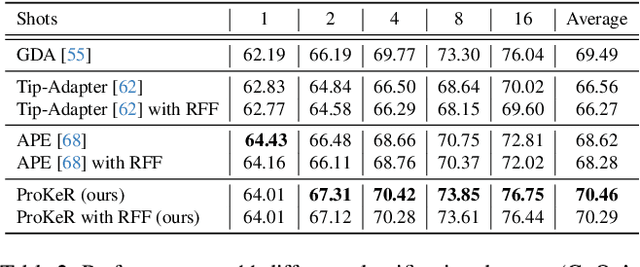
The growing popularity of Contrastive Language-Image Pretraining (CLIP) has led to its widespread application in various visual downstream tasks. To enhance CLIP's effectiveness and versatility, efficient few-shot adaptation techniques have been widely adopted. Among these approaches, training-free methods, particularly caching methods exemplified by Tip-Adapter, have gained attention for their lightweight adaptation without the need for additional fine-tuning. In this paper, we revisit Tip-Adapter from a kernel perspective, showing that caching methods function as local adapters and are connected to a well-established kernel literature. Drawing on this insight, we offer a theoretical understanding of how these methods operate and suggest multiple avenues for enhancing the Tip-Adapter baseline. Notably, our analysis shows the importance of incorporating global information in local adapters. Therefore, we subsequently propose a global method that learns a proximal regularizer in a reproducing kernel Hilbert space (RKHS) using CLIP as a base learner. Our method, which we call ProKeR (Proximal Kernel ridge Regression), has a closed form solution and achieves state-of-the-art performances across 11 datasets in the standard few-shot adaptation benchmark.
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Apr 02, 2024We consider the problem of zero-shot one-class visual classification. In this setting, only the label of the target class is available, and the goal is to discriminate between positive and negative query samples without requiring any validation example from the target task. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. Our work shows that it is possible to discriminate between a single category and other semantically related ones using only its label
Few and Fewer: Learning Better from Few Examples Using Fewer Base Classes
Jan 29, 2024When training data is scarce, it is common to make use of a feature extractor that has been pre-trained on a large base dataset, either by fine-tuning its parameters on the ``target'' dataset or by directly adopting its representation as features for a simple classifier. Fine-tuning is ineffective for few-shot learning, since the target dataset contains only a handful of examples. However, directly adopting the features without fine-tuning relies on the base and target distributions being similar enough that these features achieve separability and generalization. This paper investigates whether better features for the target dataset can be obtained by training on fewer base classes, seeking to identify a more useful base dataset for a given task.We consider cross-domain few-shot image classification in eight different domains from Meta-Dataset and entertain multiple real-world settings (domain-informed, task-informed and uninformed) where progressively less detail is known about the target task. To our knowledge, this is the first demonstration that fine-tuning on a subset of carefully selected base classes can significantly improve few-shot learning. Our contributions are simple and intuitive methods that can be implemented in any few-shot solution. We also give insights into the conditions in which these solutions are likely to provide a boost in accuracy. We release the code to reproduce all experiments from this paper on GitHub. https://github.com/RafLaf/Few-and-Fewer.git
Inferring Latent Class Statistics from Text for Robust Visual Few-Shot Learning
Nov 24, 2023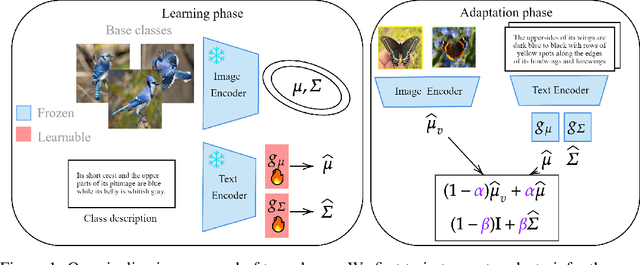

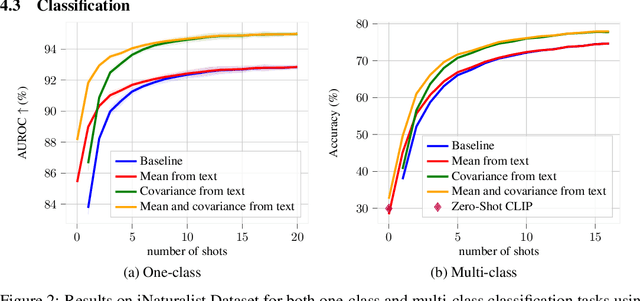

In the realm of few-shot learning, foundation models like CLIP have proven effective but exhibit limitations in cross-domain robustness especially in few-shot settings. Recent works add text as an extra modality to enhance the performance of these models. Most of these approaches treat text as an auxiliary modality without fully exploring its potential to elucidate the underlying class visual features distribution. In this paper, we present a novel approach that leverages text-derived statistics to predict the mean and covariance of the visual feature distribution for each class. This predictive framework enriches the latent space, yielding more robust and generalizable few-shot learning models. We demonstrate the efficacy of incorporating both mean and covariance statistics in improving few-shot classification performance across various datasets. Our method shows that we can use text to predict the mean and covariance of the distribution offering promising improvements in few-shot learning scenarios.
Disambiguation of One-Shot Visual Classification Tasks: A Simplex-Based Approach
Jan 16, 2023
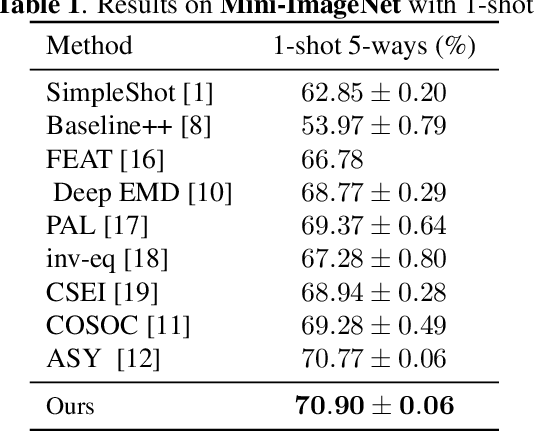
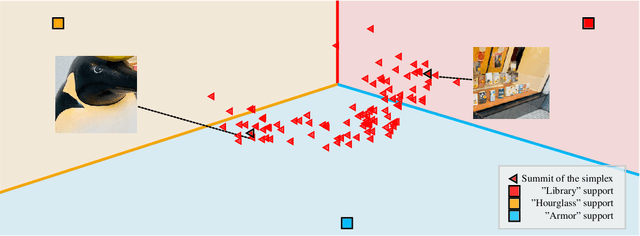

The field of visual few-shot classification aims at transferring the state-of-the-art performance of deep learning visual systems onto tasks where only a very limited number of training samples are available. The main solution consists in training a feature extractor using a large and diverse dataset to be applied to the considered few-shot task. Thanks to the encoded priors in the feature extractors, classification tasks with as little as one example (or "shot'') for each class can be solved with high accuracy, even when the shots display individual features not representative of their classes. Yet, the problem becomes more complicated when some of the given shots display multiple objects. In this paper, we present a strategy which aims at detecting the presence of multiple and previously unseen objects in a given shot. This methodology is based on identifying the corners of a simplex in a high dimensional space. We introduce an optimization routine and showcase its ability to successfully detect multiple (previously unseen) objects in raw images. Then, we introduce a downstream classifier meant to exploit the presence of multiple objects to improve the performance of few-shot classification, in the case of extreme settings where only one shot is given for its class. Using standard benchmarks of the field, we show the ability of the proposed method to slightly, yet statistically significantly, improve accuracy in these settings.
A Statistical Model for Predicting Generalization in Few-Shot Classification
Dec 13, 2022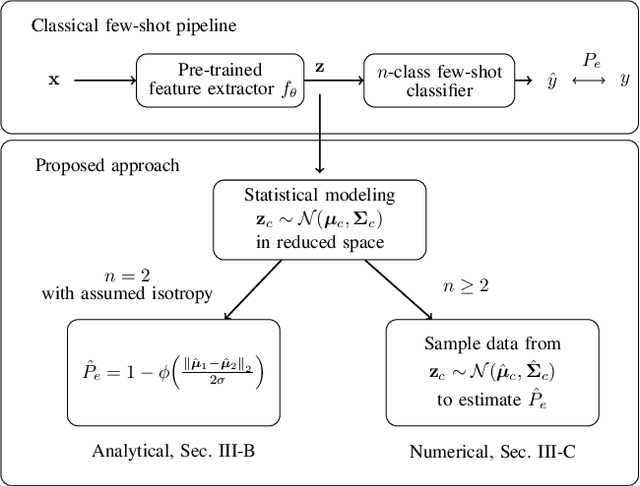
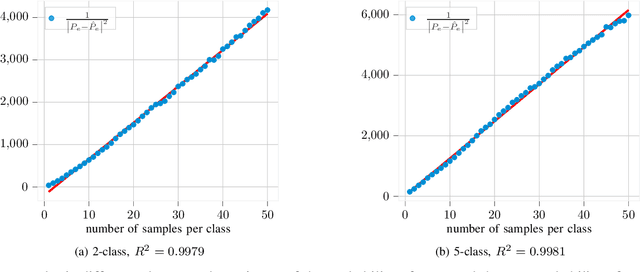


The estimation of the generalization error of classifiers often relies on a validation set. Such a set is hardly available in few-shot learning scenarios, a highly disregarded shortcoming in the field. In these scenarios, it is common to rely on features extracted from pre-trained neural networks combined with distance-based classifiers such as nearest class mean. In this work, we introduce a Gaussian model of the feature distribution. By estimating the parameters of this model, we are able to predict the generalization error on new classification tasks with few samples. We observe that accurate distance estimates between class-conditional densities are the key to accurate estimates of the generalization performance. Therefore, we propose an unbiased estimator for these distances and integrate it in our numerical analysis. We show that our approach outperforms alternatives such as the leave-one-out cross-validation strategy in few-shot settings.
EASY: Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
Feb 07, 2022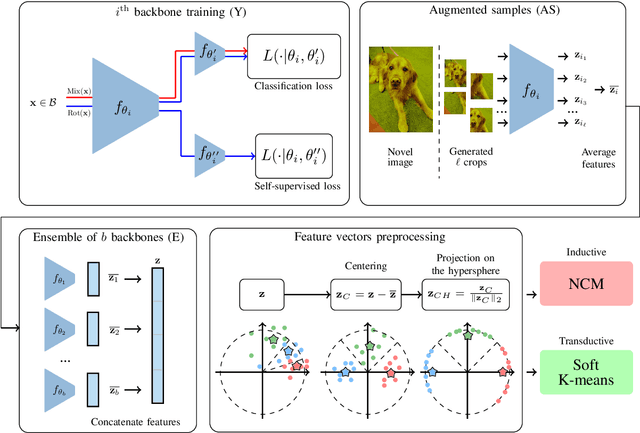
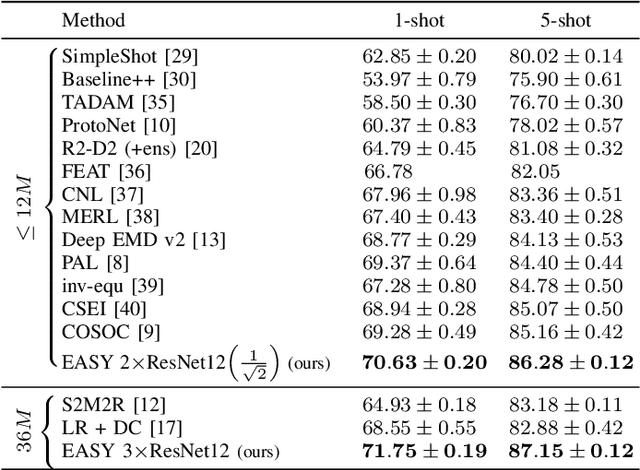
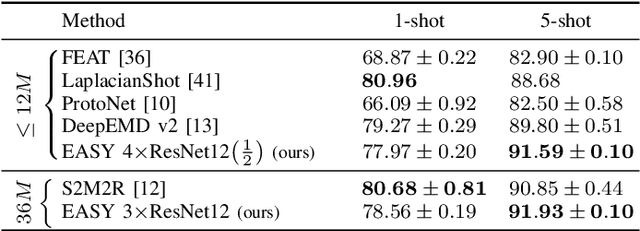

Few-shot learning aims at leveraging knowledge learned by one or more deep learning models, in order to obtain good classification performance on new problems, where only a few labeled samples per class are available. Recent years have seen a fair number of works in the field, introducing methods with numerous ingredients. A frequent problem, though, is the use of suboptimally trained models to extract knowledge, leading to interrogations on whether proposed approaches bring gains compared to using better initial models without the introduced ingredients. In this work, we propose a simple methodology, that reaches or even beats state of the art performance on multiple standardized benchmarks of the field, while adding almost no hyperparameters or parameters to those used for training the initial deep learning models on the generic dataset. This methodology offers a new baseline on which to propose (and fairly compare) new techniques or adapt existing ones.