 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeningioma Analysis and Diagnosis using Limited Labeled Samples
Feb 11, 2026The biological behavior and treatment response of meningiomas depend on their grade, making an accurate diagnosis essential for treatment planning and prognosis assessment. We observed that the weighted fusion of spatial-frequency domain features significantly influences meningioma classification performance. Notably, the contribution of specific frequency bands obtained by discrete wavelet transform varies considerably across different images. A feature fusion architecture with adaptive weights of different frequency band information and spatial domain information is proposed for few-shot meningioma learning. To verify the effectiveness of the proposed method, a new MRI dataset of meningiomas is introduced. The experimental results demonstrate the superiority of the proposed method compared with existing state-of-the-art methods in three datasets. The code will be available at: https://github.com/ICL-SUST/AMSF-Net
Distributionally Robust Contract Theory for Edge AIGC Services in Teleoperation
May 10, 2025Advanced AI-Generated Content (AIGC) technologies have injected new impetus into teleoperation, further enhancing its security and efficiency. Edge AIGC networks have been introduced to meet the stringent low-latency requirements of teleoperation. However, the inherent uncertainty of AIGC service quality and the need to incentivize AIGC service providers (ASPs) make the design of a robust incentive mechanism essential. This design is particularly challenging due to both uncertainty and information asymmetry, as teleoperators have limited knowledge of the remaining resource capacities of ASPs. To this end, we propose a distributionally robust optimization (DRO)-based contract theory to design robust reward schemes for AIGC task offloading. Notably, our work extends the contract theory by integrating DRO, addressing the fundamental challenge of contract design under uncertainty. In this paper, contract theory is employed to model the information asymmetry, while DRO is utilized to capture the uncertainty in AIGC service quality. Given the inherent complexity of the original DRO-based contract theory problem, we reformulate it into an equivalent, tractable bi-level optimization problem. To efficiently solve this problem, we develop a Block Coordinate Descent (BCD)-based algorithm to derive robust reward schemes. Simulation results on our unity-based teleoperation platform demonstrate that the proposed method improves teleoperator utility by 2.7\% to 10.74\% under varying degrees of AIGC service quality shifts and increases ASP utility by 60.02\% compared to the SOTA method, i.e., Deep Reinforcement Learning (DRL)-based contract theory. The code and data are publicly available at https://github.com/Zijun0819/DRO-Contract-Theory.
Adaptive Dimension Reduction and Variational Inference for Transductive Few-Shot Classification
Sep 18, 2022

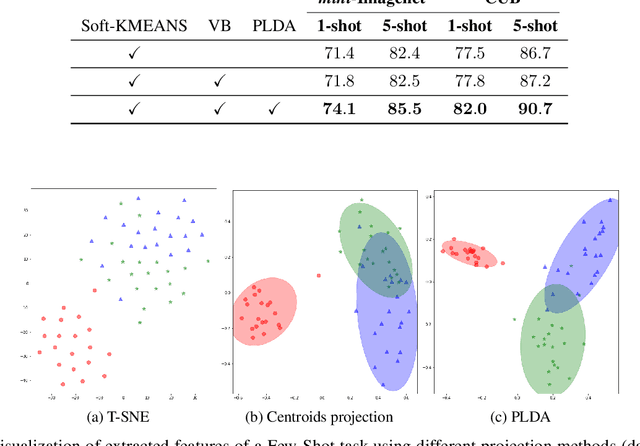
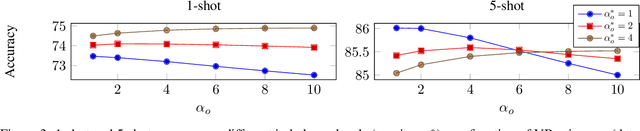
Transductive Few-Shot learning has gained increased attention nowadays considering the cost of data annotations along with the increased accuracy provided by unlabelled samples in the domain of few shot. Especially in Few-Shot Classification (FSC), recent works explore the feature distributions aiming at maximizing likelihoods or posteriors with respect to the unknown parameters. Following this vein, and considering the parallel between FSC and clustering, we seek for better taking into account the uncertainty in estimation due to lack of data, as well as better statistical properties of the clusters associated with each class. Therefore in this paper we propose a new clustering method based on Variational Bayesian inference, further improved by Adaptive Dimension Reduction based on Probabilistic Linear Discriminant Analysis. Our proposed method significantly improves accuracy in the realistic unbalanced transductive setting on various Few-Shot benchmarks when applied to features used in previous studies, with a gain of up to $6\%$ in accuracy. In addition, when applied to balanced setting, we obtain very competitive results without making use of the class-balance artefact which is disputable for practical use cases. We also provide the performance of our method on a high performing pretrained backbone, with the reported results further surpassing the current state-of-the-art accuracy, suggesting the genericity of the proposed method.
EASY: Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
Feb 07, 2022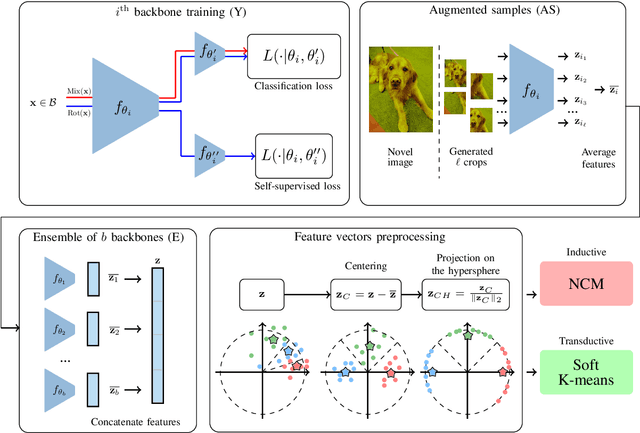
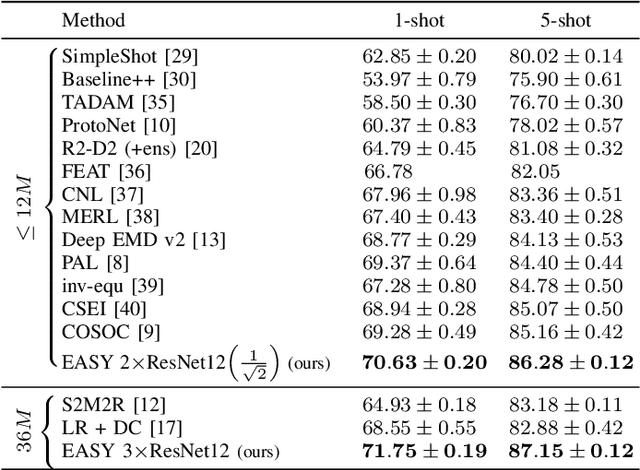
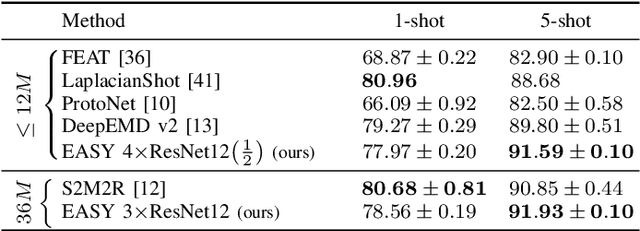

Few-shot learning aims at leveraging knowledge learned by one or more deep learning models, in order to obtain good classification performance on new problems, where only a few labeled samples per class are available. Recent years have seen a fair number of works in the field, introducing methods with numerous ingredients. A frequent problem, though, is the use of suboptimally trained models to extract knowledge, leading to interrogations on whether proposed approaches bring gains compared to using better initial models without the introduced ingredients. In this work, we propose a simple methodology, that reaches or even beats state of the art performance on multiple standardized benchmarks of the field, while adding almost no hyperparameters or parameters to those used for training the initial deep learning models on the generic dataset. This methodology offers a new baseline on which to propose (and fairly compare) new techniques or adapt existing ones.
Squeezing Backbone Feature Distributions to the Max for Efficient Few-Shot Learning
Oct 18, 2021
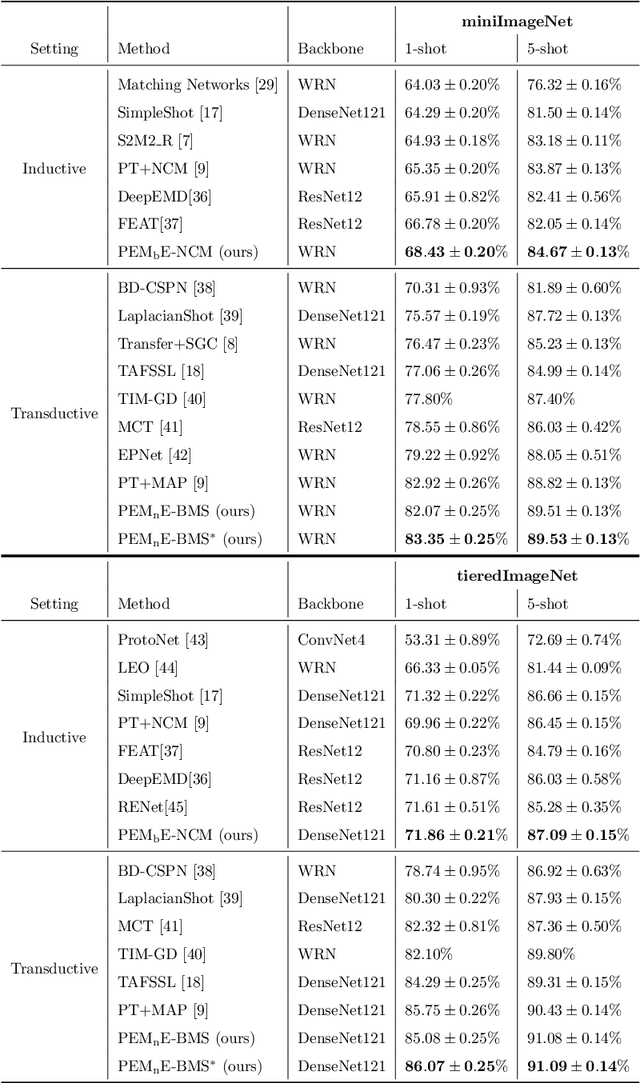
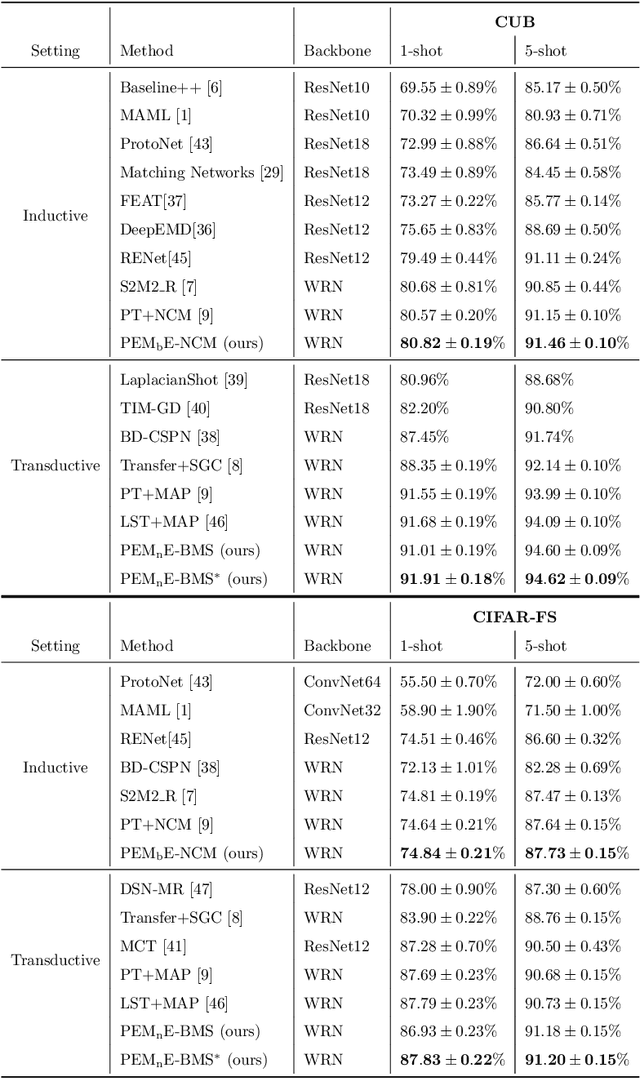

Few-shot classification is a challenging problem due to the uncertainty caused by using few labelled samples. In the past few years, many methods have been proposed with the common aim of transferring knowledge acquired on a previously solved task, what is often achieved by using a pretrained feature extractor. Following this vein, in this paper we propose a novel transfer-based method which aims at processing the feature vectors so that they become closer to Gaussian-like distributions, resulting in increased accuracy. In the case of transductive few-shot learning where unlabelled test samples are available during training, we also introduce an optimal-transport inspired algorithm to boost even further the achieved performance. Using standardized vision benchmarks, we show the ability of the proposed methodology to achieve state-of-the-art accuracy with various datasets, backbone architectures and few-shot settings.
Times Series Forecasting for Urban Building Energy Consumption Based on Graph Convolutional Network
May 27, 2021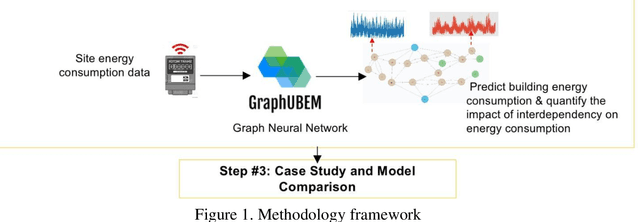



The world is increasingly urbanizing and the building industry accounts for more than 40% of energy consumption in the United States. To improve urban sustainability, many cities adopt ambitious energy-saving strategies through retrofitting existing buildings and constructing new communities. In this situation, an accurate urban building energy model (UBEM) is the foundation to support the design of energy-efficient communities. However, current UBEM are limited in their abilities to capture the inter-building interdependency due to their dynamic and non-linear characteristics. Those models either ignored or oversimplified these building interdependencies, which can substantially affect the accuracy of urban energy modeling. To fill the research gap, this study proposes a novel data-driven UBEM synthesizing the solar-based building interdependency and spatial-temporal graph convolutional network (ST-GCN) algorithm. Especially, we took a university campus located in downtown Atlanta as an example to predict the hourly energy consumption. Furthermore, we tested the feasibility of the proposed model by comparing the performance of the ST-GCN model with other common time-series machine learning models. The results indicate that the ST-GCN model overall outperforms all others. In addition, the physical knowledge embedded in the model is well interpreted. After discussion, it is found that data-driven models integrated engineering or physical knowledge can significantly improve the urban building energy simulation.
Improving Classification Accuracy with Graph Filtering
Jan 25, 2021



In machine learning, classifiers are typically susceptible to noise in the training data. In this work, we aim at reducing intra-class noise with the help of graph filtering to improve the classification performance. Considered graphs are obtained by connecting samples of the training set that belong to a same class depending on the similarity of their representation in a latent space. We show that the proposed graph filtering methodology has the effect of asymptotically reducing intra-class variance, while maintaining the mean. While our approach applies to all classification problems in general, it is particularly useful in few-shot settings, where intra-class noise can have a huge impact due to the small sample selection. Using standardized benchmarks in the field of vision, we empirically demonstrate the ability of the proposed method to slightly improve state-of-the-art results in both cases of few-shot and standard classification.
Leveraging the Feature Distribution in Transfer-based Few-Shot Learning
Jun 06, 2020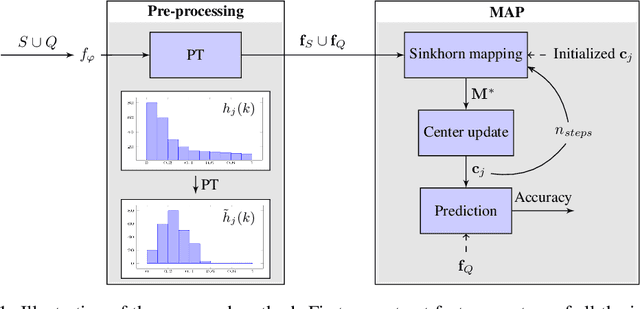
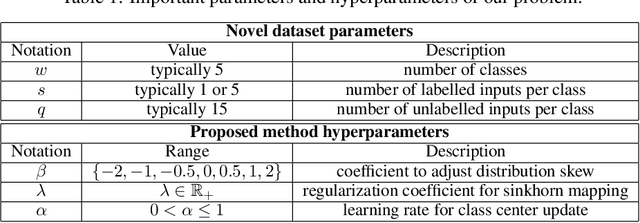


Few-shot classification is a challenging problem due to the uncertainty caused by using few labelled samples. In the past few years, transfer-based methods have proved to achieve the best performance, thanks to well-thought-out backbone architectures combined with efficient postprocessing steps. Following this vein, in this paper we propose a transfer-based novel method that builds on two steps: 1) preprocessing the feature vectors so that they become closer to Gaussian-like distributions, and 2) leveraging this preprocessing using an optimal-transport inspired algorithm. Using standardized vision benchmarks, we prove the ability of the proposed methodology to achieve state-of-the-art accuracy with various datasets, backbone architectures and few-shot settings.
Exploiting Unsupervised Inputs for Accurate Few-Shot Classification
Feb 26, 2020


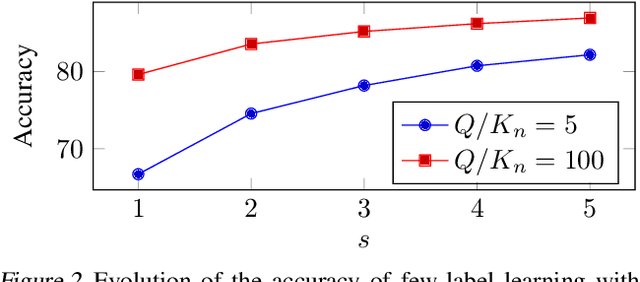
In few-shot classification, the aim is to learn models able to discriminate classes with only a small number of labelled examples. Most of the literature considers the problem of labelling a single unknown input at a time. Instead, it can be beneficial to consider a setting where a batch of unlabelled inputs are treated conjointly and non-independently. In this vein, we propose a method able to exploit three levels of information: a) feature extractors pretrained on generic datasets, b) few labelled examples of classes to discriminate and c) other available unlabelled inputs. If for a), we use state-of-the-art approaches, we introduce the use of simplified graph convolutions to perform b) and c) together. Our proposed model reaches state-of-the-art accuracy with a $6-11\%$ increase compared to available alternatives on standard few-shot vision classification datasets.