 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEASY: Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
Paper and Code
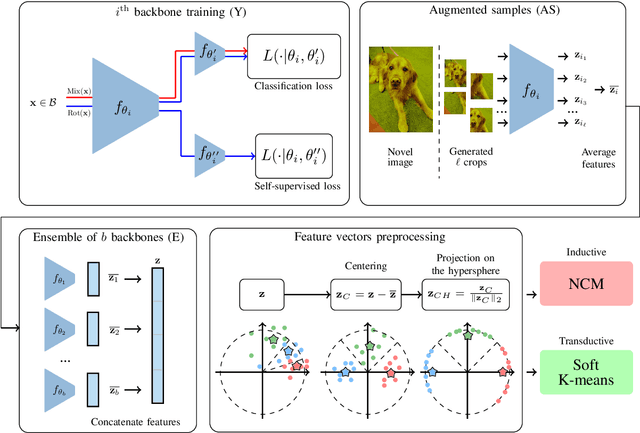
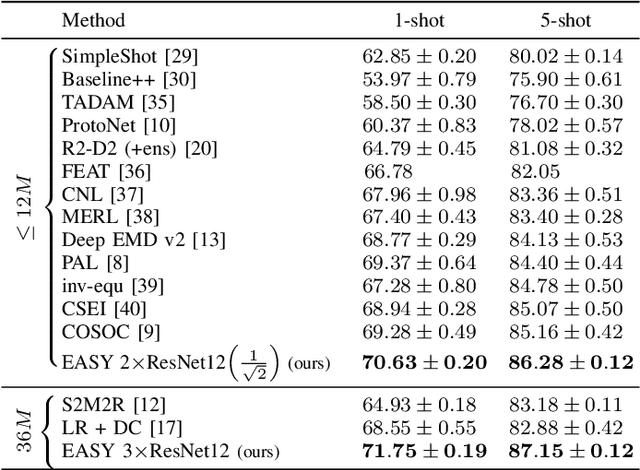
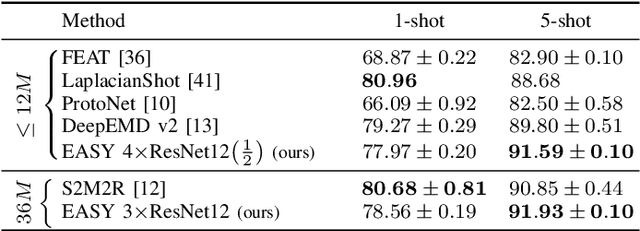

Few-shot learning aims at leveraging knowledge learned by one or more deep learning models, in order to obtain good classification performance on new problems, where only a few labeled samples per class are available. Recent years have seen a fair number of works in the field, introducing methods with numerous ingredients. A frequent problem, though, is the use of suboptimally trained models to extract knowledge, leading to interrogations on whether proposed approaches bring gains compared to using better initial models without the introduced ingredients. In this work, we propose a simple methodology, that reaches or even beats state of the art performance on multiple standardized benchmarks of the field, while adding almost no hyperparameters or parameters to those used for training the initial deep learning models on the generic dataset. This methodology offers a new baseline on which to propose (and fairly compare) new techniques or adapt existing ones.