 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing IoT Security via Automatic Network Traffic Analysis: The Transition from Machine Learning to Deep Learning
Nov 20, 2023



This work provides a comparative analysis illustrating how Deep Learning (DL) surpasses Machine Learning (ML) in addressing tasks within Internet of Things (IoT), such as attack classification and device-type identification. Our approach involves training and evaluating a DL model using a range of diverse IoT-related datasets, allowing us to gain valuable insights into how adaptable and practical these models can be when confronted with various IoT configurations. We initially convert the unstructured network traffic data from IoT networks, stored in PCAP files, into images by processing the packet data. This conversion process adapts the data to meet the criteria of DL classification methods. The experiments showcase the ability of DL to surpass the constraints tied to manually engineered features, achieving superior results in attack detection and maintaining comparable outcomes in device-type identification. Additionally, a notable feature extraction time difference becomes evident in the experiments: traditional methods require around 29 milliseconds per data packet, while DL accomplishes the same task in just 2.9 milliseconds. The significant time gap, DL's superior performance, and the recognized limitations of manually engineered features, presents a compelling call to action within the IoT community. This encourages us to shift from exploring new IoT features for each dataset to addressing the challenges of integrating DL into IoT, making it a more efficient solution for real-world IoT scenarios.
White-box Membership Attack Against Machine Learning Based Retinopathy Classification
May 30, 2022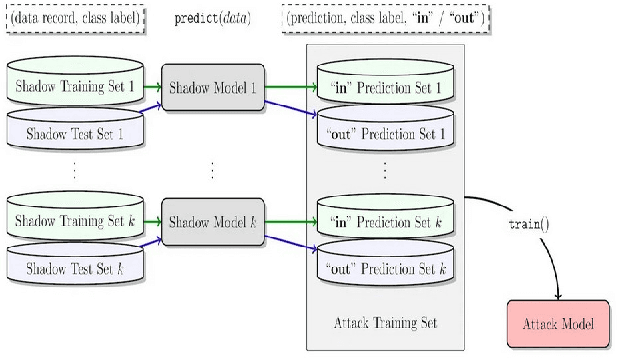
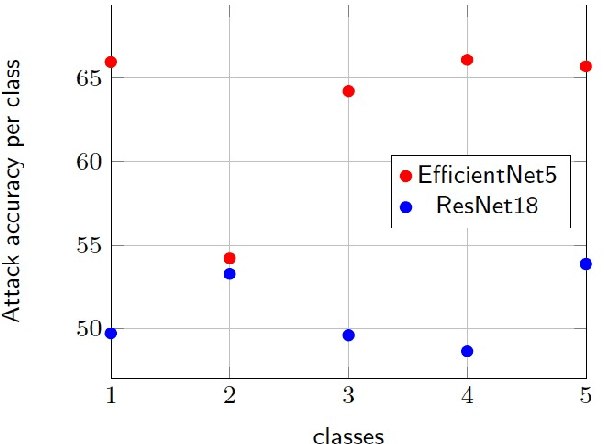
The advances in machine learning (ML) have greatly improved AI-based diagnosis aid systems in medical imaging. However, being based on collecting medical data specific to individuals induces several security issues, especially in terms of privacy. Even though the owner of the images like a hospital put in place strict privacy protection provisions at the level of its information system, the model trained over his images still holds disclosure potential. The trained model may be accessible to an attacker as: 1) White-box: accessing to the model architecture and parameters; 2) Black box: where he can only query the model with his own inputs through an appropriate interface. Existing attack methods include: feature estimation attacks (FEA), membership inference attack (MIA), model memorization attack (MMA) and identification attacks (IA). In this work we focus on MIA against a model that has been trained to detect diabetic retinopathy from retinal images. Diabetic retinopathy is a condition that can cause vision loss and blindness in the people who have diabetes. MIA is the process of determining whether a data sample comes from the training data set of a trained ML model or not. From a privacy perspective in our use case where a diabetic retinopathy classification model is given to partners that have at their disposal images along with patients' identifiers, inferring the membership status of a data sample can help to state if a patient has contributed or not to the training of the model.
Graphs as Tools to Improve Deep Learning Methods
Oct 08, 2021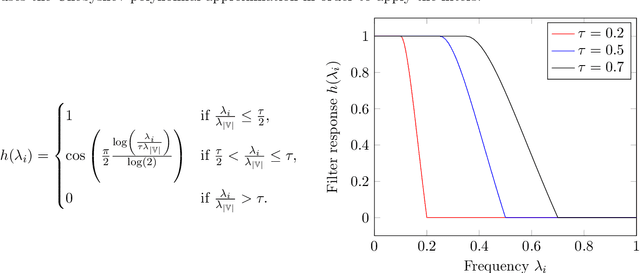
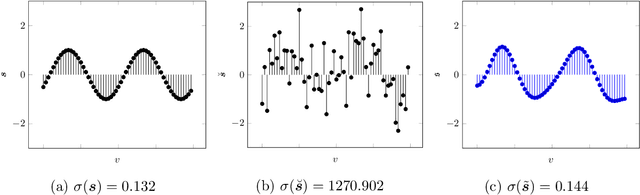

In recent years, deep neural networks (DNNs) have known an important rise in popularity. However, although they are state-of-the-art in many machine learning challenges, they still suffer from several limitations. For example, DNNs require a lot of training data, which might not be available in some practical applications. In addition, when small perturbations are added to the inputs, DNNs are prone to misclassification errors. DNNs are also viewed as black-boxes and as such their decisions are often criticized for their lack of interpretability. In this chapter, we review recent works that aim at using graphs as tools to improve deep learning methods. These graphs are defined considering a specific layer in a deep learning architecture. Their vertices represent distinct samples, and their edges depend on the similarity of the corresponding intermediate representations. These graphs can then be leveraged using various methodologies, many of which built on top of graph signal processing. This chapter is composed of four main parts: tools for visualizing intermediate layers in a DNN, denoising data representations, optimizing graph objective functions and regularizing the learning process.
Improving Classification Accuracy with Graph Filtering
Jan 25, 2021



In machine learning, classifiers are typically susceptible to noise in the training data. In this work, we aim at reducing intra-class noise with the help of graph filtering to improve the classification performance. Considered graphs are obtained by connecting samples of the training set that belong to a same class depending on the similarity of their representation in a latent space. We show that the proposed graph filtering methodology has the effect of asymptotically reducing intra-class variance, while maintaining the mean. While our approach applies to all classification problems in general, it is particularly useful in few-shot settings, where intra-class noise can have a huge impact due to the small sample selection. Using standardized benchmarks in the field of vision, we empirically demonstrate the ability of the proposed method to slightly improve state-of-the-art results in both cases of few-shot and standard classification.
Ranking Deep Learning Generalization using Label Variation in Latent Geometry Graphs
Nov 25, 2020

Measuring the generalization performance of a Deep Neural Network (DNN) without relying on a validation set is a difficult task. In this work, we propose exploiting Latent Geometry Graphs (LGGs) to represent the latent spaces of trained DNN architectures. Such graphs are obtained by connecting samples that yield similar latent representations at a given layer of the considered DNN. We then obtain a generalization score by looking at how strongly connected are samples of distinct classes in LGGs. This score allowed us to rank 3rd on the NeurIPS 2020 Predicting Generalization in Deep Learning (PGDL) competition.