 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCLEAN: byzantine defense by CLustering Errors of Activation maps in Non-IID federated learning environments
Jan 21, 2025Federated Learning (FL) enables clients to collaboratively train a global model using their local datasets while reinforcing data privacy. However, FL is susceptible to poisoning attacks. Existing defense mechanisms assume that clients' data are independent and identically distributed (IID), making them ineffective in real-world applications where data are non-IID. This paper presents FedCLEAN, the first defense capable of filtering attackers' model updates in a non-IID FL environment. The originality of FedCLEAN is twofold. First, it relies on a client confidence score derived from the reconstruction errors of each client's model activation maps for a given trigger set, with reconstruction errors obtained by means of a Conditional Variational Autoencoder trained according to a novel server-side strategy. Second, we propose an ad-hoc trust propagation algorithm based on client scores, which allows building a cluster of benign clients while flagging potential attackers. Experimental results on the datasets MNIST and FashionMNIST demonstrate the robustness of FedCLEAN against Byzantine attackers in non-IID scenarios and a close-to-zero benign client misclassification rate, even in the absence of an attack.
When Federated Learning meets Watermarking: A Comprehensive Overview of Techniques for Intellectual Property Protection
Aug 07, 2023
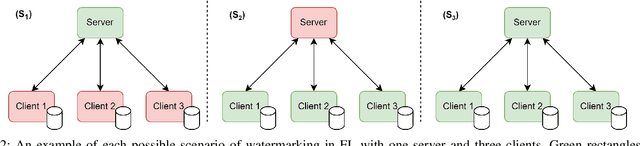
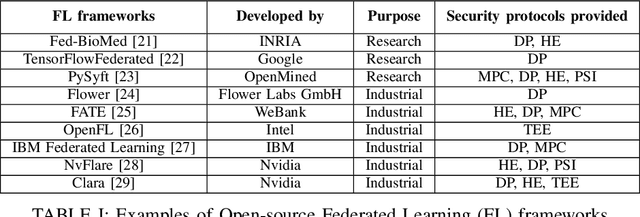

Federated Learning (FL) is a technique that allows multiple participants to collaboratively train a Deep Neural Network (DNN) without the need of centralizing their data. Among other advantages, it comes with privacy-preserving properties making it attractive for application in sensitive contexts, such as health care or the military. Although the data are not explicitly exchanged, the training procedure requires sharing information about participants' models. This makes the individual models vulnerable to theft or unauthorized distribution by malicious actors. To address the issue of ownership rights protection in the context of Machine Learning (ML), DNN Watermarking methods have been developed during the last five years. Most existing works have focused on watermarking in a centralized manner, but only a few methods have been designed for FL and its unique constraints. In this paper, we provide an overview of recent advancements in Federated Learning watermarking, shedding light on the new challenges and opportunities that arise in this field.
White-box Membership Attack Against Machine Learning Based Retinopathy Classification
May 30, 2022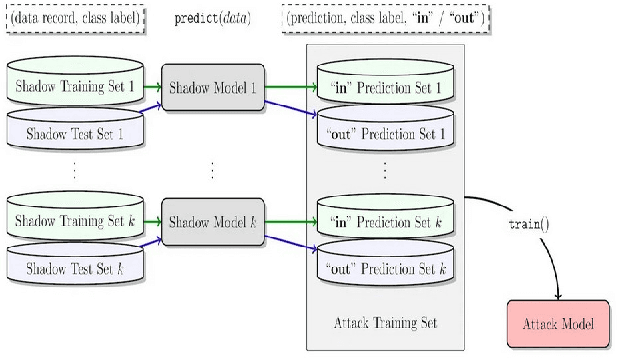
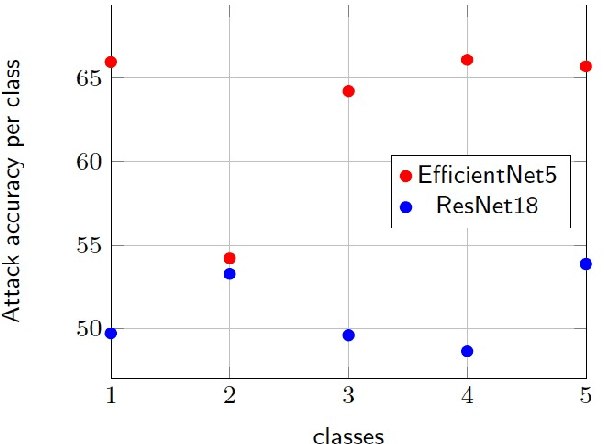
The advances in machine learning (ML) have greatly improved AI-based diagnosis aid systems in medical imaging. However, being based on collecting medical data specific to individuals induces several security issues, especially in terms of privacy. Even though the owner of the images like a hospital put in place strict privacy protection provisions at the level of its information system, the model trained over his images still holds disclosure potential. The trained model may be accessible to an attacker as: 1) White-box: accessing to the model architecture and parameters; 2) Black box: where he can only query the model with his own inputs through an appropriate interface. Existing attack methods include: feature estimation attacks (FEA), membership inference attack (MIA), model memorization attack (MMA) and identification attacks (IA). In this work we focus on MIA against a model that has been trained to detect diabetic retinopathy from retinal images. Diabetic retinopathy is a condition that can cause vision loss and blindness in the people who have diabetes. MIA is the process of determining whether a data sample comes from the training data set of a trained ML model or not. From a privacy perspective in our use case where a diabetic retinopathy classification model is given to partners that have at their disposal images along with patients' identifiers, inferring the membership status of a data sample can help to state if a patient has contributed or not to the training of the model.