 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Classification of Accelerometer Data for Industrial Package Monitoring with Embedded Deep Learning
Jun 05, 2025Package monitoring is an important topic in industrial applications, with significant implications for operational efficiency and ecological sustainability. In this study, we propose an approach that employs an embedded system, placed on reusable packages, to detect their state (on a Forklift, in a Truck, or in an undetermined location). We aim to design a system with a lifespan of several years, corresponding to the lifespan of reusable packages. Our analysis demonstrates that maximizing device lifespan requires minimizing wake time. We propose a pipeline that includes data processing, training, and evaluation of the deep learning model designed for imbalanced, multiclass time series data collected from an embedded sensor. The method uses a one-dimensional Convolutional Neural Network architecture to classify accelerometer data from the IoT device. Before training, two data augmentation techniques are tested to solve the imbalance problem of the dataset: the Synthetic Minority Oversampling TEchnique and the ADAptive SYNthetic sampling approach. After training, compression techniques are implemented to have a small model size. On the considered twoclass problem, the methodology yields a precision of 94.54% for the first class and 95.83% for the second class, while compression techniques reduce the model size by a factor of four. The trained model is deployed on the IoT device, where it operates with a power consumption of 316 mW during inference.
ThinResNet: A New Baseline for Structured Convolutional Networks Pruning
Sep 22, 2023



Pruning is a compression method which aims to improve the efficiency of neural networks by reducing their number of parameters while maintaining a good performance, thus enhancing the performance-to-cost ratio in nontrivial ways. Of particular interest are structured pruning techniques, in which whole portions of parameters are removed altogether, resulting in easier to leverage shrunk architectures. Since its growth in popularity in the recent years, pruning gave birth to countless papers and contributions, resulting first in critical inconsistencies in the way results are compared, and then to a collective effort to establish standardized benchmarks. However, said benchmarks are based on training practices that date from several years ago and do not align with current practices. In this work, we verify how results in the recent literature of pruning hold up against networks that underwent both state-of-the-art training methods and trivial model scaling. We find that the latter clearly and utterly outperform all the literature we compared to, proving that updating standard pruning benchmarks and re-evaluating classical methods in their light is an absolute necessity. We thus introduce a new challenging baseline to compare structured pruning to: ThinResNet.
Energy Consumption Analysis of pruned Semantic Segmentation Networks on an Embedded GPU
Jun 13, 2022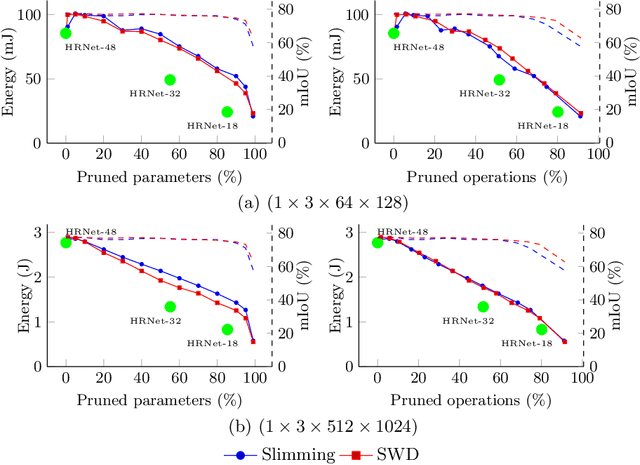
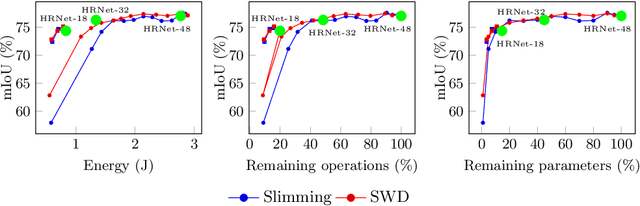
Deep neural networks are the state of the art in many computer vision tasks. Their deployment in the context of autonomous vehicles is of particular interest, since their limitations in terms of energy consumption prohibit the use of very large networks, that typically reach the best performance. A common method to reduce the complexity of these architectures, without sacrificing accuracy, is to rely on pruning, in which the least important portions are eliminated. There is a large literature on the subject, but interestingly few works have measured the actual impact of pruning on energy. In this work, we are interested in measuring it in the specific context of semantic segmentation for autonomous driving, using the Cityscapes dataset. To this end, we analyze the impact of recently proposed structured pruning methods when trained architectures are deployed on a Jetson Xavier embedded GPU.
Leveraging Structured Pruning of Convolutional Neural Networks
Jun 13, 2022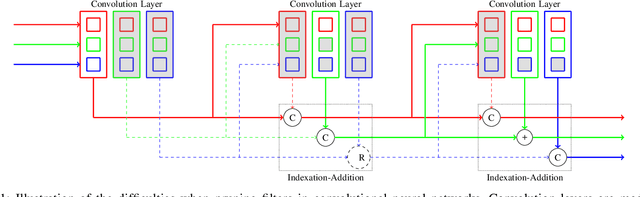
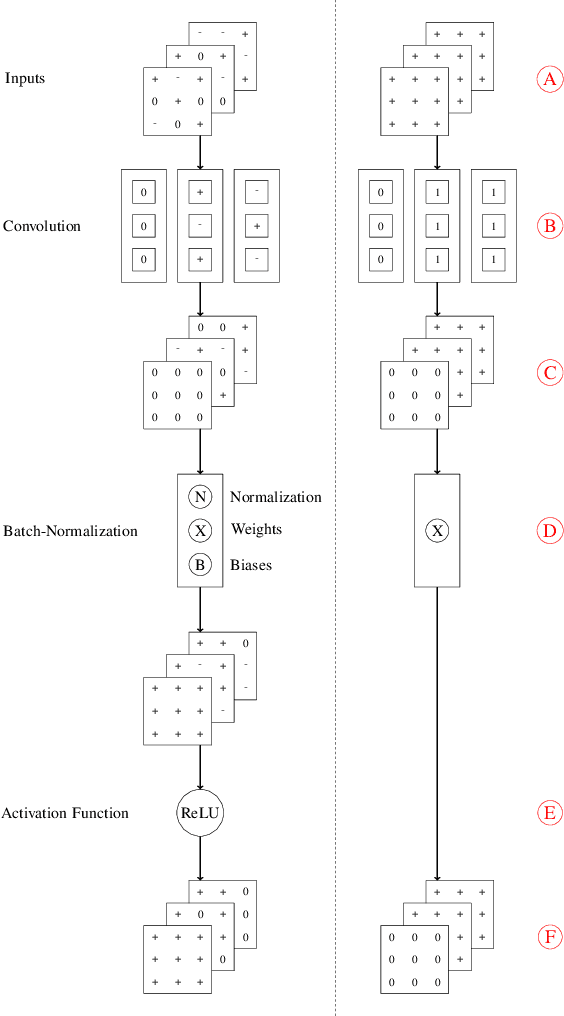
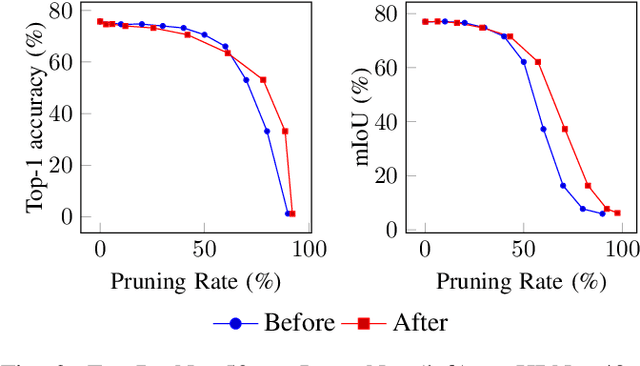
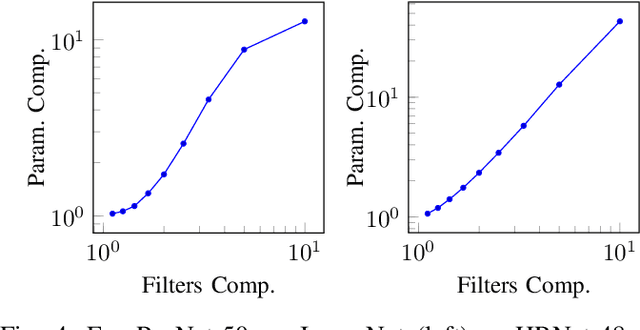
Structured pruning is a popular method to reduce the cost of convolutional neural networks, that are the state of the art in many computer vision tasks. However, depending on the architecture, pruning introduces dimensional discrepancies which prevent the actual reduction of pruned networks. To tackle this problem, we propose a method that is able to take any structured pruning mask and generate a network that does not encounter any of these problems and can be leveraged efficiently. We provide an accurate description of our solution and show results of gains, in energy consumption and inference time on embedded hardware, of pruned convolutional neural networks.
Pruning Graph Convolutional Networks to select meaningful graph frequencies for fMRI decoding
Mar 09, 2022
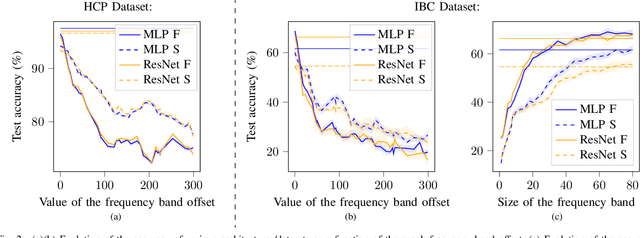
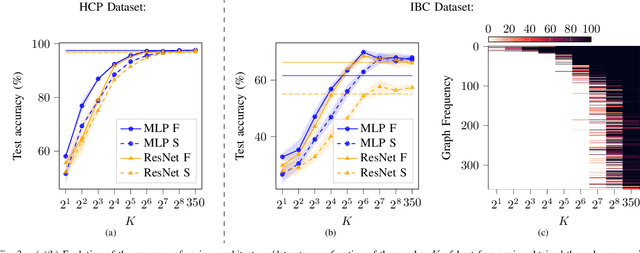
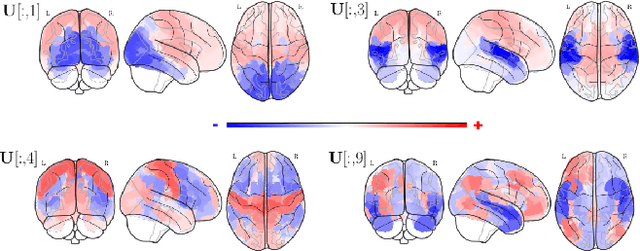
Graph Signal Processing is a promising framework to manipulate brain signals as it allows to encompass the spatial dependencies between the activity in regions of interest in the brain. In this work, we are interested in better understanding what are the graph frequencies that are the most useful to decode fMRI signals. To this end, we introduce a deep learning architecture and adapt a pruning methodology to automatically identify such frequencies. We experiment with various datasets, architectures and graphs, and show that low graph frequencies are consistently identified as the most important for fMRI decoding, with a stronger contribution for the functional graph over the structural one. We believe that this work provides novel insights on how graph-based methods can be deployed to increase fMRI decoding accuracy and interpretability.
Continuous Pruning of Deep Convolutional Networks Using Selective Weight Decay
Dec 22, 2020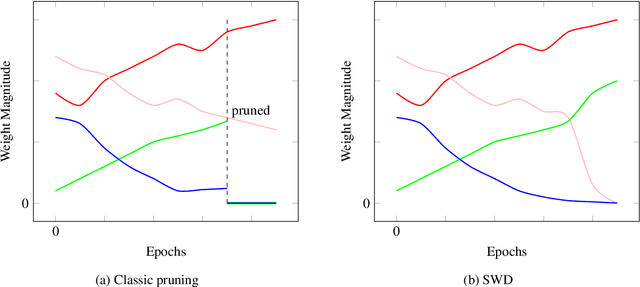
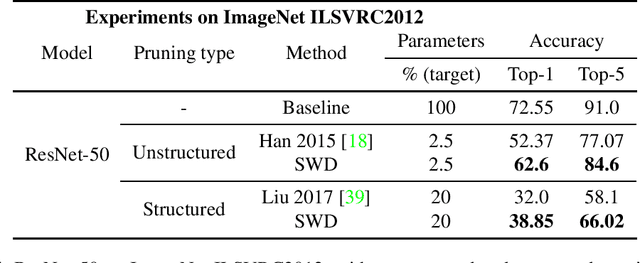
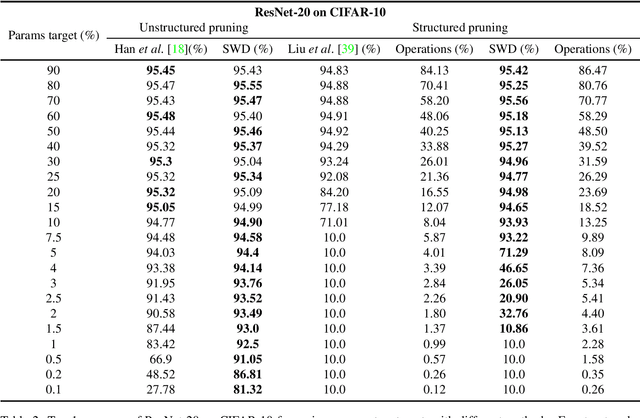
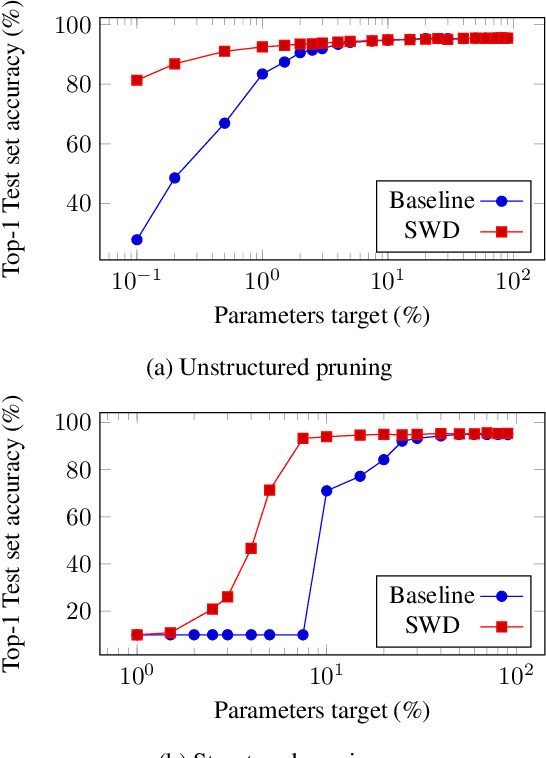
During the last decade, deep convolutional networks have become the reference for many machine learning tasks, especially in computer vision. However, large computational needs make them hard to deploy on resource-constrained hardware. Pruning has emerged as a standard way to compress such large networks. Yet, the severe perturbation caused by most pruning approaches is thought to hinder their efficacy. Drawing inspiration from Lagrangian Smoothing, we introduce a new technique, Selective Weight Decay (SWD), which achieves continuous pruning throughout training. Our theoretically-grounded approach is versatile and can be applied to any problem, network or pruning structure. We show that SWD compares favorably to other approaches in terms of performance/parameters ratio on the CIFAR-10 and ImageNet ILSVRC2012 datasets. On CIFAR-10 and unstructured pruning, for a target rate of 0.1% unpruned parameters, SWD attains a Top-1 accuracy of 81.32% while the reference method only reaches 27.78%. On CIFAR-10 and structured pruning, for a target rate of 2.5% unpruned parameters, the reference technique drops at 10% (random guess) while SWD maintains the Top-1 accuracy at 93.22%. On the ImageNet ILSVRC2012 dataset with unstructured pruning and the same target rate of 2.5%, SWD attains 84.6% Top-5 accuracy instead of the 77.07% reached by the reference.