 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Consumption Analysis of pruned Semantic Segmentation Networks on an Embedded GPU
Jun 13, 2022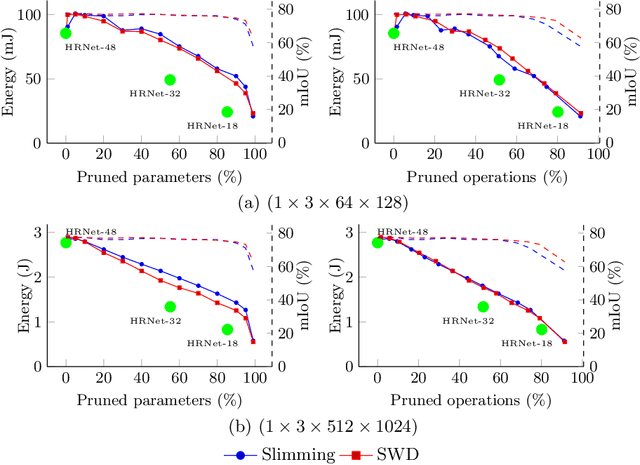
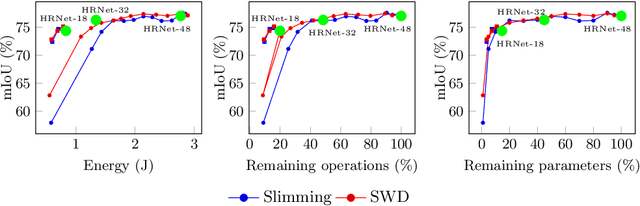
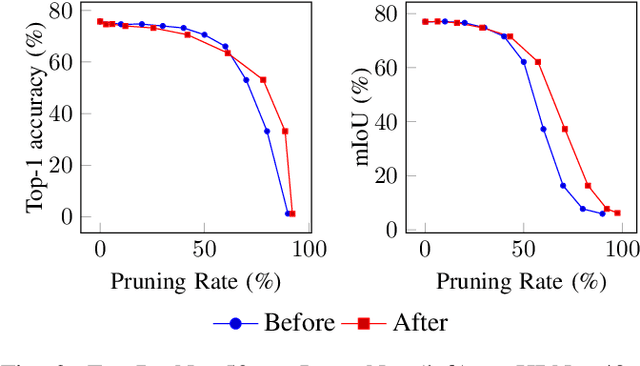
Deep neural networks are the state of the art in many computer vision tasks. Their deployment in the context of autonomous vehicles is of particular interest, since their limitations in terms of energy consumption prohibit the use of very large networks, that typically reach the best performance. A common method to reduce the complexity of these architectures, without sacrificing accuracy, is to rely on pruning, in which the least important portions are eliminated. There is a large literature on the subject, but interestingly few works have measured the actual impact of pruning on energy. In this work, we are interested in measuring it in the specific context of semantic segmentation for autonomous driving, using the Cityscapes dataset. To this end, we analyze the impact of recently proposed structured pruning methods when trained architectures are deployed on a Jetson Xavier embedded GPU.
Leveraging Structured Pruning of Convolutional Neural Networks
Jun 13, 2022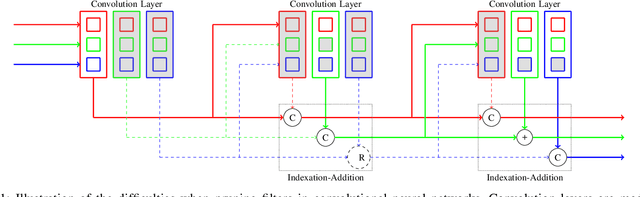
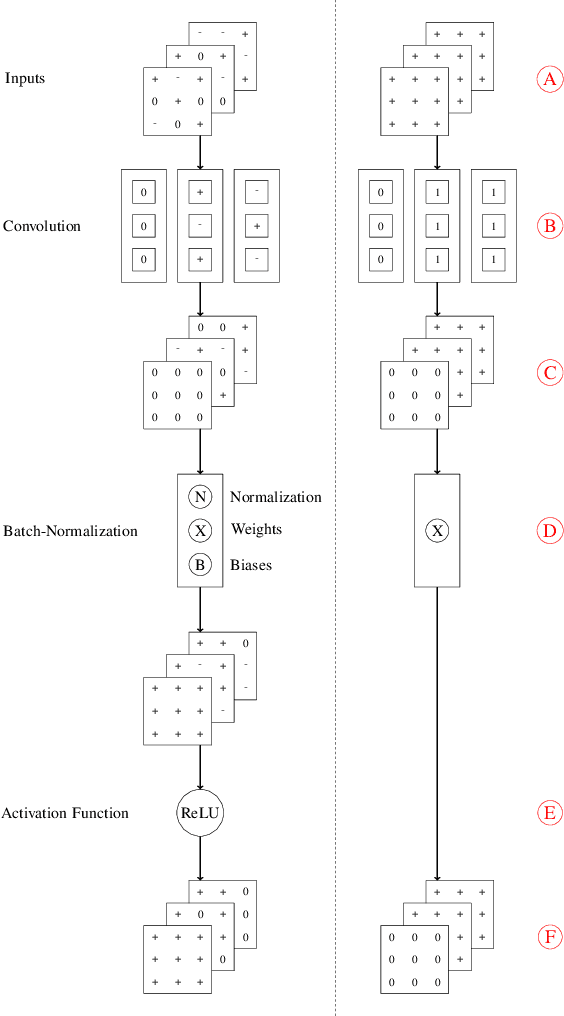
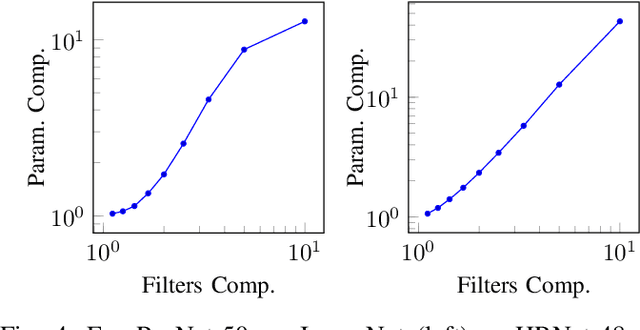
Structured pruning is a popular method to reduce the cost of convolutional neural networks, that are the state of the art in many computer vision tasks. However, depending on the architecture, pruning introduces dimensional discrepancies which prevent the actual reduction of pruned networks. To tackle this problem, we propose a method that is able to take any structured pruning mask and generate a network that does not encounter any of these problems and can be leveraged efficiently. We provide an accurate description of our solution and show results of gains, in energy consumption and inference time on embedded hardware, of pruned convolutional neural networks.
Continuous Pruning of Deep Convolutional Networks Using Selective Weight Decay
Dec 22, 2020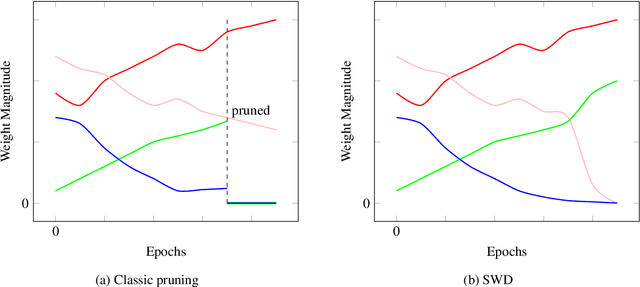
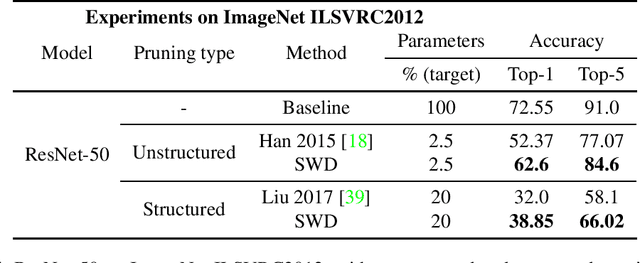
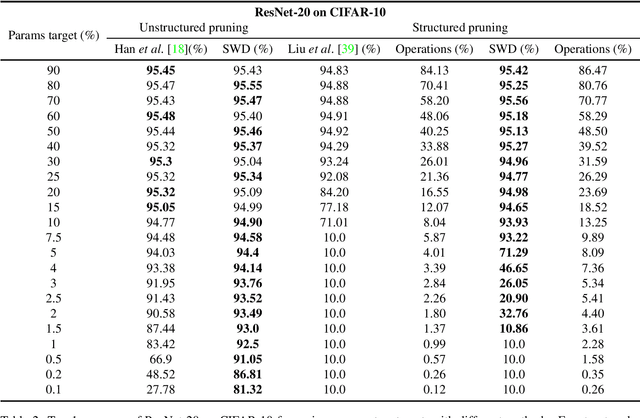
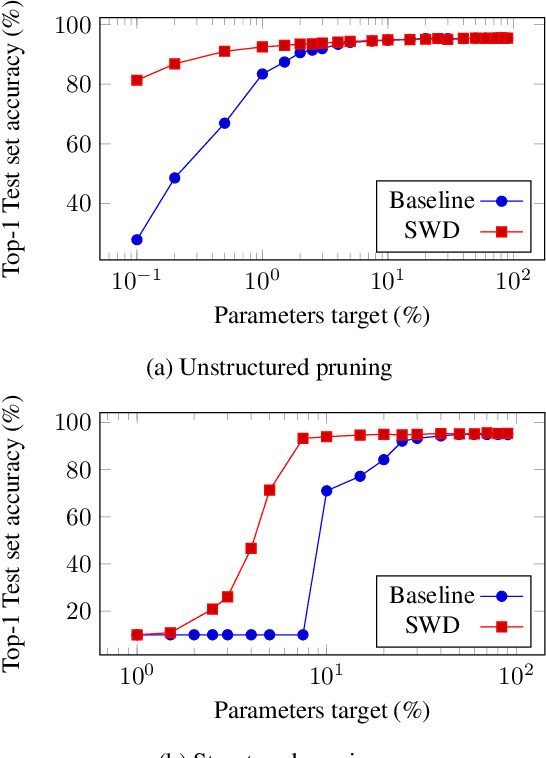
During the last decade, deep convolutional networks have become the reference for many machine learning tasks, especially in computer vision. However, large computational needs make them hard to deploy on resource-constrained hardware. Pruning has emerged as a standard way to compress such large networks. Yet, the severe perturbation caused by most pruning approaches is thought to hinder their efficacy. Drawing inspiration from Lagrangian Smoothing, we introduce a new technique, Selective Weight Decay (SWD), which achieves continuous pruning throughout training. Our theoretically-grounded approach is versatile and can be applied to any problem, network or pruning structure. We show that SWD compares favorably to other approaches in terms of performance/parameters ratio on the CIFAR-10 and ImageNet ILSVRC2012 datasets. On CIFAR-10 and unstructured pruning, for a target rate of 0.1% unpruned parameters, SWD attains a Top-1 accuracy of 81.32% while the reference method only reaches 27.78%. On CIFAR-10 and structured pruning, for a target rate of 2.5% unpruned parameters, the reference technique drops at 10% (random guess) while SWD maintains the Top-1 accuracy at 93.22%. On the ImageNet ILSVRC2012 dataset with unstructured pruning and the same target rate of 2.5%, SWD attains 84.6% Top-5 accuracy instead of the 77.07% reached by the reference.