 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Objective Optimization through Machine Learning-Supported Multiphysics Simulation
Sep 22, 2023



Multiphysics simulations that involve multiple coupled physical phenomena quickly become computationally expensive. This imposes challenges for practitioners aiming to find optimal configurations for these problems satisfying multiple objectives, as optimization algorithms often require querying the simulation many times. This paper presents a methodological framework for training, self-optimizing, and self-organizing surrogate models to approximate and speed up Multiphysics simulations. We generate two real-world tabular datasets, which we make publicly available, and show that surrogate models can be trained on relatively small amounts of data to approximate the underlying simulations accurately. We conduct extensive experiments combining four machine learning and deep learning algorithms with two optimization algorithms and a comprehensive evaluation strategy. Finally, we evaluate the performance of our combined training and optimization pipeline by verifying the generated Pareto-optimal results using the ground truth simulations. We also employ explainable AI techniques to analyse our surrogates and conduct a preselection strategy to determine the most relevant features in our real-world examples. This approach lets us understand the underlying problem and identify critical partial dependencies.
Unraveling the Complexity of Splitting Sequential Data: Tackling Challenges in Video and Time Series Analysis
Jul 26, 2023
Splitting of sequential data, such as videos and time series, is an essential step in various data analysis tasks, including object tracking and anomaly detection. However, splitting sequential data presents a variety of challenges that can impact the accuracy and reliability of subsequent analyses. This concept article examines the challenges associated with splitting sequential data, including data acquisition, data representation, split ratio selection, setting up quality criteria, and choosing suitable selection strategies. We explore these challenges through two real-world examples: motor test benches and particle tracking in liquids.
Out-of-distribution Detection and Generation using Soft Brownian Offset Sampling and Autoencoders
May 04, 2021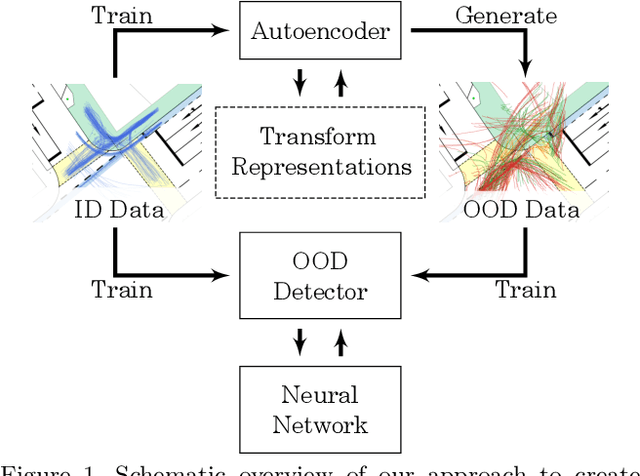
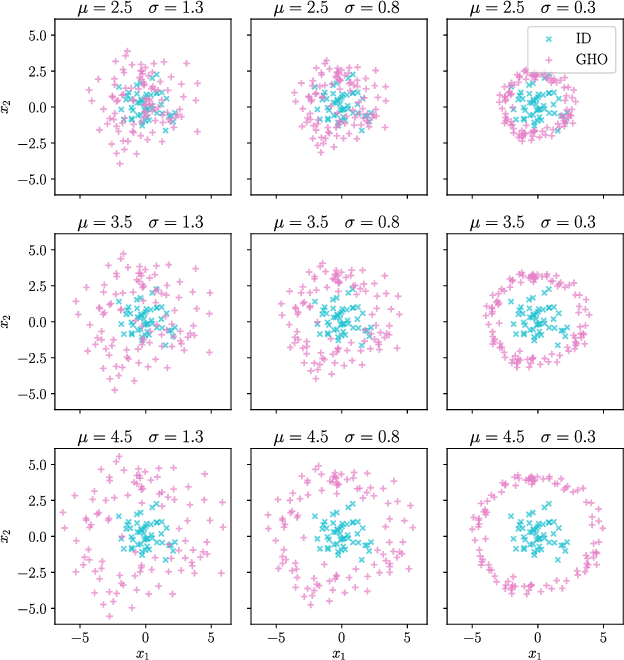
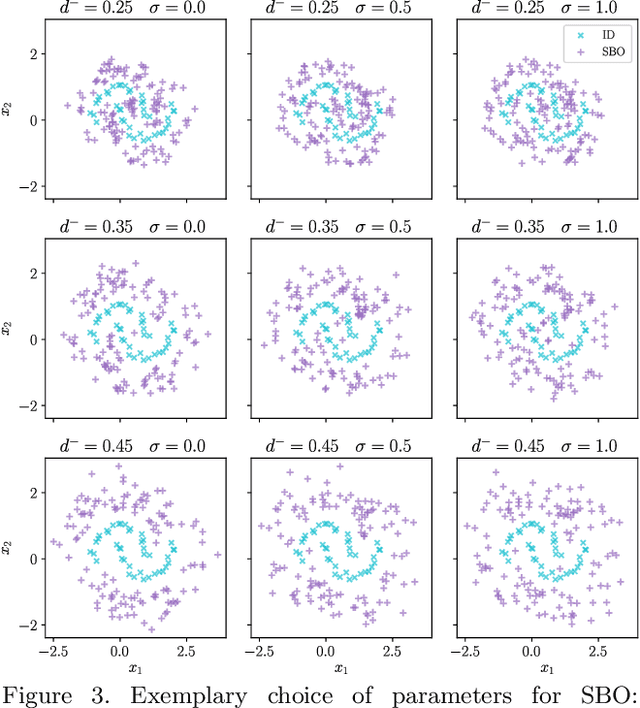
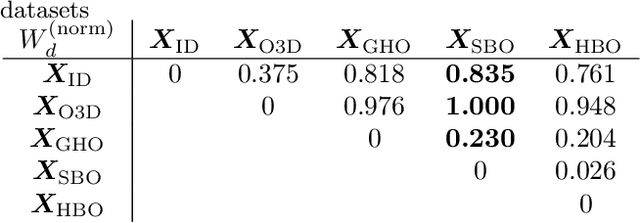
Deep neural networks often suffer from overconfidence which can be partly remedied by improved out-of-distribution detection. For this purpose, we propose a novel approach that allows for the generation of out-of-distribution datasets based on a given in-distribution dataset. This new dataset can then be used to improve out-of-distribution detection for the given dataset and machine learning task at hand. The samples in this dataset are with respect to the feature space close to the in-distribution dataset and therefore realistic and plausible. Hence, this dataset can also be used to safeguard neural networks, i.e., to validate the generalization performance. Our approach first generates suitable representations of an in-distribution dataset using an autoencoder and then transforms them using our novel proposed Soft Brownian Offset method. After transformation, the decoder part of the autoencoder allows for the generation of these implicit out-of-distribution samples. This newly generated dataset then allows for mixing with other datasets and thus improved training of an out-of-distribution classifier, increasing its performance. Experimentally, we show that our approach is promising for time series using synthetic data. Using our new method, we also show in a quantitative case study that we can improve the out-of-distribution detection for the MNIST dataset. Finally, we provide another case study on the synthetic generation of out-of-distribution trajectories, which can be used to validate trajectory prediction algorithms for automated driving.