 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Objective Optimization through Machine Learning-Supported Multiphysics Simulation
Sep 22, 2023



Multiphysics simulations that involve multiple coupled physical phenomena quickly become computationally expensive. This imposes challenges for practitioners aiming to find optimal configurations for these problems satisfying multiple objectives, as optimization algorithms often require querying the simulation many times. This paper presents a methodological framework for training, self-optimizing, and self-organizing surrogate models to approximate and speed up Multiphysics simulations. We generate two real-world tabular datasets, which we make publicly available, and show that surrogate models can be trained on relatively small amounts of data to approximate the underlying simulations accurately. We conduct extensive experiments combining four machine learning and deep learning algorithms with two optimization algorithms and a comprehensive evaluation strategy. Finally, we evaluate the performance of our combined training and optimization pipeline by verifying the generated Pareto-optimal results using the ground truth simulations. We also employ explainable AI techniques to analyse our surrogates and conduct a preselection strategy to determine the most relevant features in our real-world examples. This approach lets us understand the underlying problem and identify critical partial dependencies.
Exploiting Transformer-based Multitask Learning for the Detection of Media Bias in News Articles
Nov 07, 2022Media has a substantial impact on the public perception of events. A one-sided or polarizing perspective on any topic is usually described as media bias. One of the ways how bias in news articles can be introduced is by altering word choice. Biased word choices are not always obvious, nor do they exhibit high context-dependency. Hence, detecting bias is often difficult. We propose a Transformer-based deep learning architecture trained via Multi-Task Learning using six bias-related data sets to tackle the media bias detection problem. Our best-performing implementation achieves a macro $F_{1}$ of 0.776, a performance boost of 3\% compared to our baseline, outperforming existing methods. Our results indicate Multi-Task Learning as a promising alternative to improve existing baseline models in identifying slanted reporting.
Critical analysis on the reproducibility of visual quality assessment using deep features
Sep 10, 2020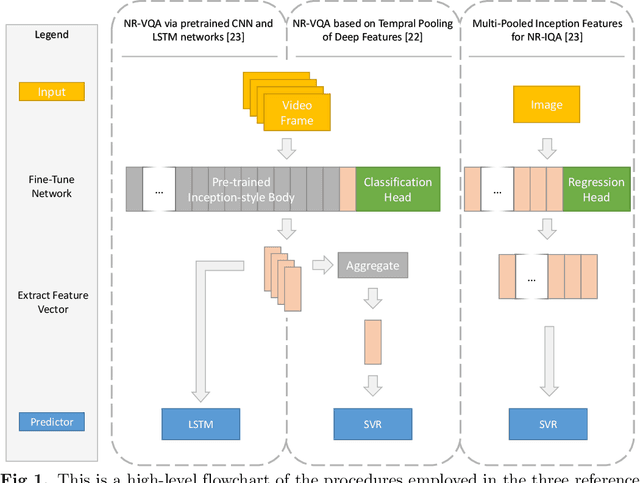
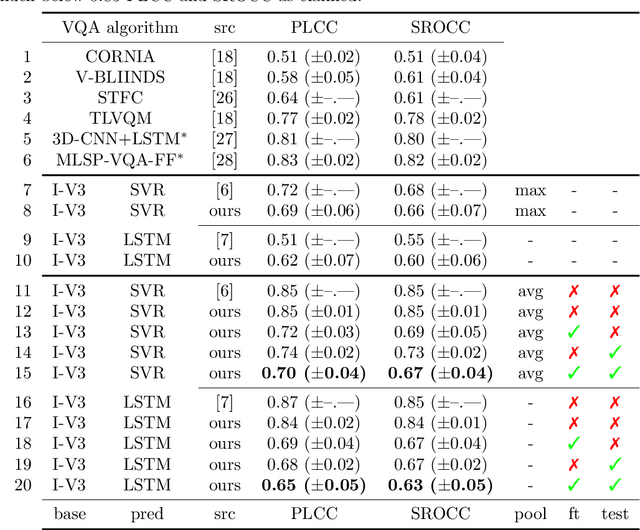
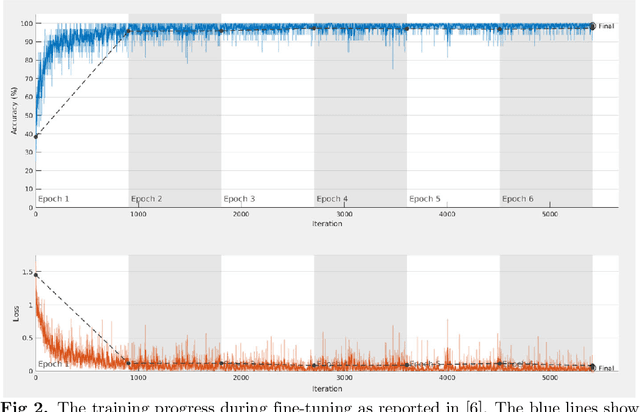
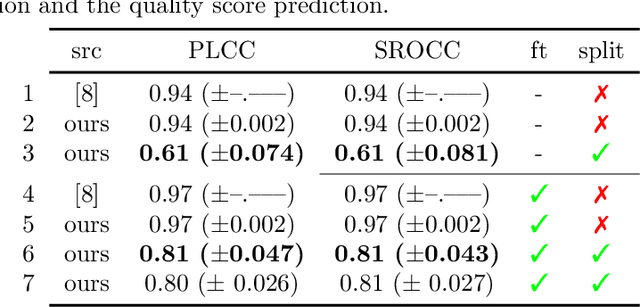
Data used to train supervised machine learning models are commonly split into independent training, validation, and test sets. In this paper we illustrate that intricate cases of data leakage have occurred in the no-reference video and image quality assessment literature. We show that the performance results of several recently published journal papers that are well above the best performances in related works, cannot be reached. Our analysis shows that information from the test set was inappropriately used in the training process in different ways. When correcting for the data leakage, the performances of the approaches drop below the state-of-the-art by a large margin. Additionally, we investigate end-to-end variations to the discussed approaches, which do not improve upon the original.
Comment on "No-Reference Video Quality Assessment Based on the Temporal Pooling of Deep Features"
May 09, 2020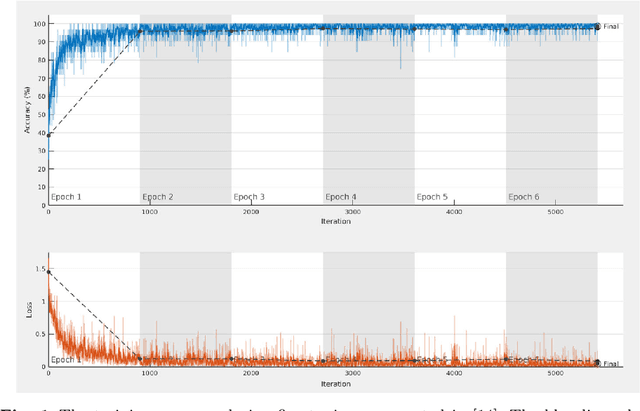
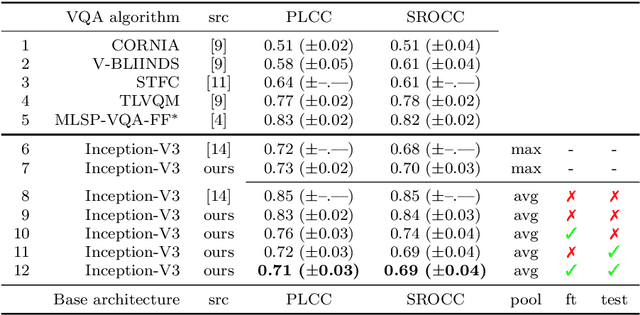

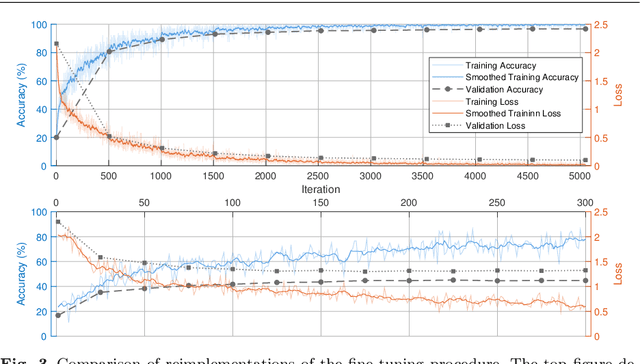
In Neural Processing Letters 50,3 (2019) a machine learning approach to blind video quality assessment was proposed. It is based on temporal pooling of features of video frames, taken from the last pooling layer of deep convolutional neural networks. The method was validated on two established benchmark datasets and gave results far better than the previous state-of-the-art. In this letter we report the results from our careful reimplementations. The performance results, claimed in the paper, cannot be reached, and are even below the state-of-the-art by a large margin. We show that the originally reported wrong performance results are a consequence of two cases of data leakage. Information from outside the training dataset was used in the fine-tuning stage and in the model evaluation.
No-Reference Video Quality Assessment using Multi-Level Spatially Pooled Features
Dec 17, 2019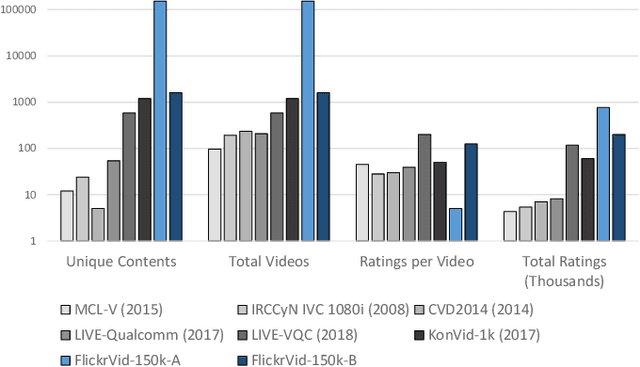


Video Quality Assessment (VQA) methods have been designed with a focus on particular degradation types, usually artificially induced on a small set of reference videos. Hence, most traditional VQA methods under-perform in-the-wild. Deep learning approaches have had limited success due to the small size and diversity of existing VQA datasets, either artificial or authentically distorted. We introduce a new in-the-wild VQA dataset that is substantially larger and diverse: FlickrVid-150k. It consists of a coarsely annotated set of 153,841 videos having 5 quality ratings each, and 1600 videos with a minimum of 89 ratings each. Additionally, we propose new efficient VQA approaches (MLSP-VQA) relying on multi-level spatially pooled deep features (MLSP). They are extremely well suited for training at scale, compared to deep transfer learning approaches. Our best method MLSP-VQA-FF improves the Spearman Rank-order Correlation Coefficient (SRCC) performance metric on the standard KonVid-1k in-the-wild benchmark dataset to 0.83 surpassing the best existing deep-learning model (0.8 SRCC) and hand-crafted feature-based method (0.78 SRCC). We further investigate how alternative approaches perform under different levels of label noise, and dataset size, showing that MLSP-VQA-FF is the overall best method. Finally, we show that MLSP-VQA-FF trained on FlickrVid-150k sets the new state-of-the-art for cross-test performance on KonVid-1k and LIVE-Qualcomm with a 0.79 and 0.58 SRCC, respectively, showing excellent generalization.