 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo-Reference Video Quality Assessment using Multi-Level Spatially Pooled Features
Paper and Code
Dec 17, 2019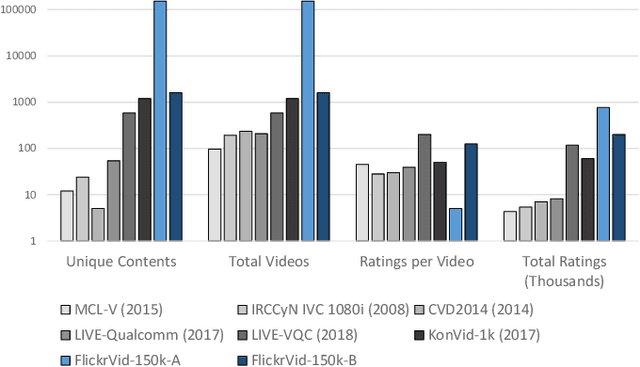
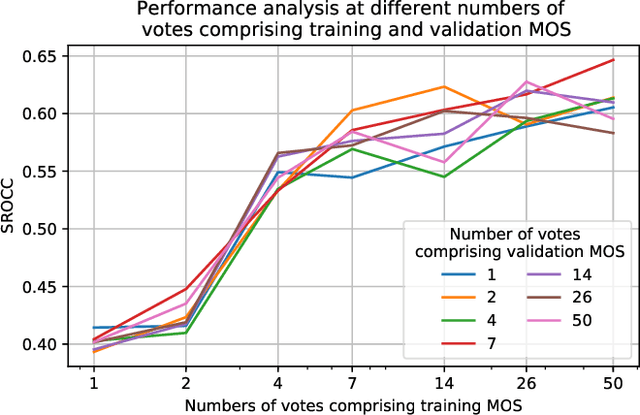


Video Quality Assessment (VQA) methods have been designed with a focus on particular degradation types, usually artificially induced on a small set of reference videos. Hence, most traditional VQA methods under-perform in-the-wild. Deep learning approaches have had limited success due to the small size and diversity of existing VQA datasets, either artificial or authentically distorted. We introduce a new in-the-wild VQA dataset that is substantially larger and diverse: FlickrVid-150k. It consists of a coarsely annotated set of 153,841 videos having 5 quality ratings each, and 1600 videos with a minimum of 89 ratings each. Additionally, we propose new efficient VQA approaches (MLSP-VQA) relying on multi-level spatially pooled deep features (MLSP). They are extremely well suited for training at scale, compared to deep transfer learning approaches. Our best method MLSP-VQA-FF improves the Spearman Rank-order Correlation Coefficient (SRCC) performance metric on the standard KonVid-1k in-the-wild benchmark dataset to 0.83 surpassing the best existing deep-learning model (0.8 SRCC) and hand-crafted feature-based method (0.78 SRCC). We further investigate how alternative approaches perform under different levels of label noise, and dataset size, showing that MLSP-VQA-FF is the overall best method. Finally, we show that MLSP-VQA-FF trained on FlickrVid-150k sets the new state-of-the-art for cross-test performance on KonVid-1k and LIVE-Qualcomm with a 0.79 and 0.58 SRCC, respectively, showing excellent generalization.