 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical analysis on the reproducibility of visual quality assessment using deep features
Paper and Code
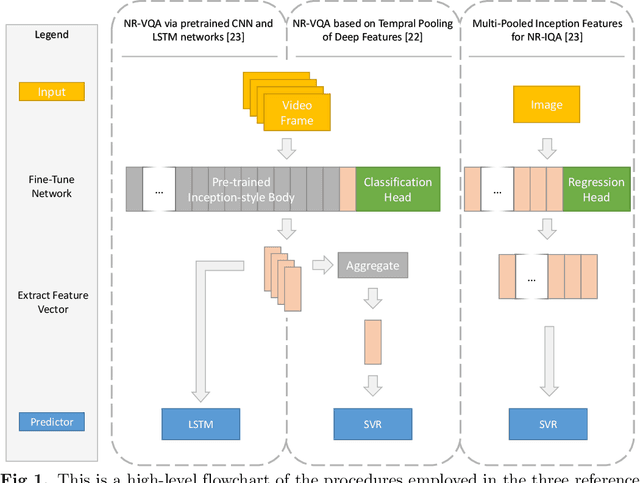
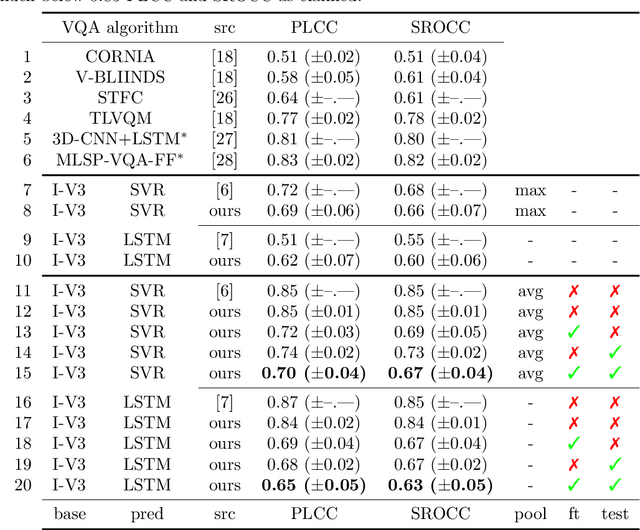
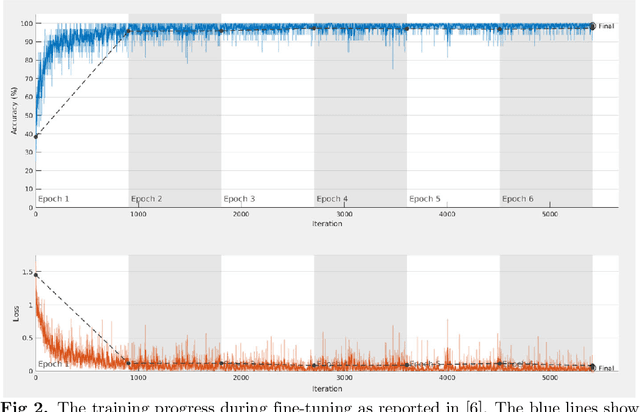
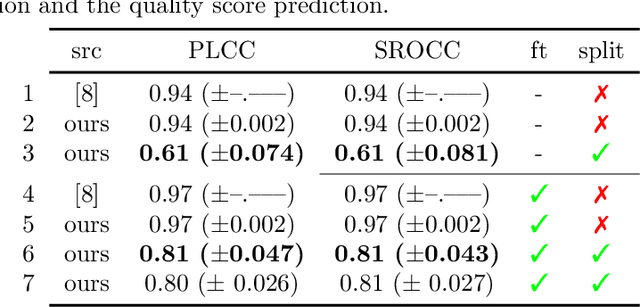
Data used to train supervised machine learning models are commonly split into independent training, validation, and test sets. In this paper we illustrate that intricate cases of data leakage have occurred in the no-reference video and image quality assessment literature. We show that the performance results of several recently published journal papers that are well above the best performances in related works, cannot be reached. Our analysis shows that information from the test set was inappropriately used in the training process in different ways. When correcting for the data leakage, the performances of the approaches drop below the state-of-the-art by a large margin. Additionally, we investigate end-to-end variations to the discussed approaches, which do not improve upon the original.