 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComment on "No-Reference Video Quality Assessment Based on the Temporal Pooling of Deep Features"
Paper and Code
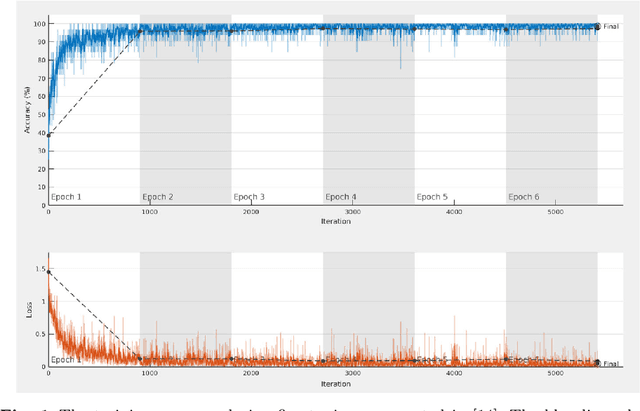
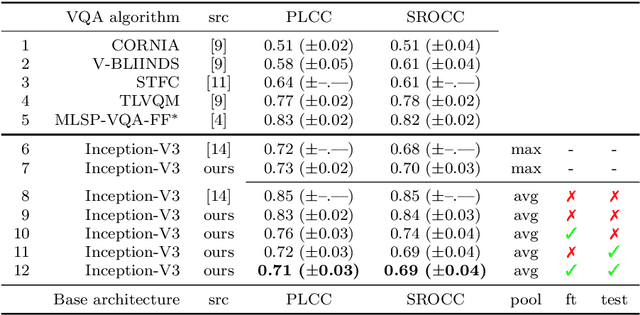

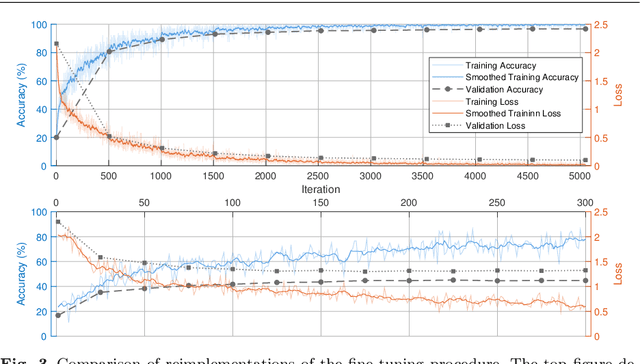
In Neural Processing Letters 50,3 (2019) a machine learning approach to blind video quality assessment was proposed. It is based on temporal pooling of features of video frames, taken from the last pooling layer of deep convolutional neural networks. The method was validated on two established benchmark datasets and gave results far better than the previous state-of-the-art. In this letter we report the results from our careful reimplementations. The performance results, claimed in the paper, cannot be reached, and are even below the state-of-the-art by a large margin. We show that the originally reported wrong performance results are a consequence of two cases of data leakage. Information from outside the training dataset was used in the fine-tuning stage and in the model evaluation.