 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Transformer: Modelling Ambiguities and Distributions for RNA Folding and Molecule Design
Paper and Code

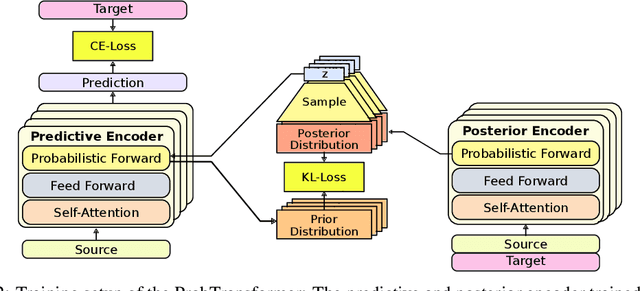
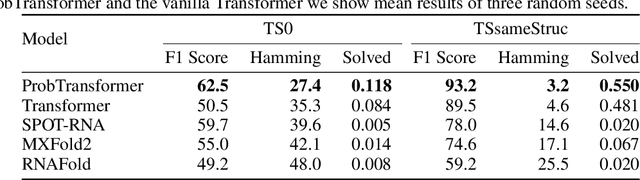
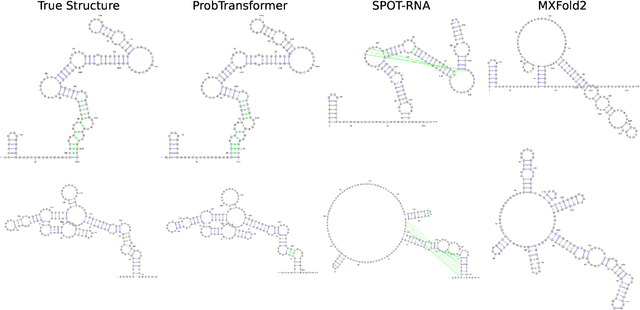
Our world is ambiguous and this is reflected in the data we use to train our algorithms. This is especially true when we try to model natural processes where collected data is affected by noisy measurements and differences in measurement techniques. Sometimes, the process itself can be ambiguous, such as in the case of RNA folding, where a single nucleotide sequence can fold into multiple structures. This ambiguity suggests that a predictive model should have similar probabilistic characteristics to match the data it models. Therefore, we propose a hierarchical latent distribution to enhance one of the most successful deep learning models, the Transformer, to accommodate ambiguities and data distributions. We show the benefits of our approach on a synthetic task, with state-of-the-art results in RNA folding, and demonstrate its generative capabilities on property-based molecule design, outperforming existing work.