 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Edge Detection for Image Segmentation with Multicut Penalties
Dec 10, 2021
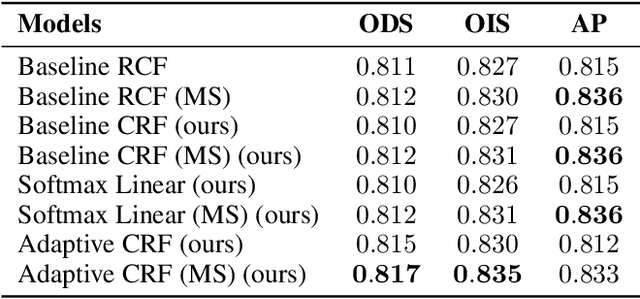
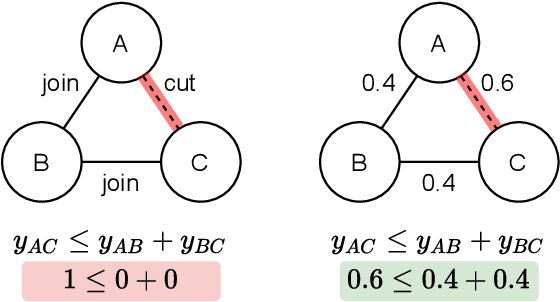

The Minimum Cost Multicut Problem (MP) is a popular way for obtaining a graph decomposition by optimizing binary edge labels over edge costs. While the formulation of a MP from independently estimated costs per edge is highly flexible and intuitive, solving the MP is NP-hard and time-expensive. As a remedy, recent work proposed to predict edge probabilities with awareness to potential conflicts by incorporating cycle constraints in the prediction process. We argue that such formulation, while providing a first step towards end-to-end learnable edge weights, is suboptimal, since it is built upon a loose relaxation of the MP. We therefore propose an adaptive CRF that allows to progressively consider more violated constraints and, in consequence, to issue solutions with higher validity. Experiments on the BSDS500 benchmark for natural image segmentation as well as on electron microscopic recordings show that our approach yields more precise edge detection and image segmentation.
Uncertainty in Minimum Cost Multicuts for Image and Motion Segmentation
May 16, 2021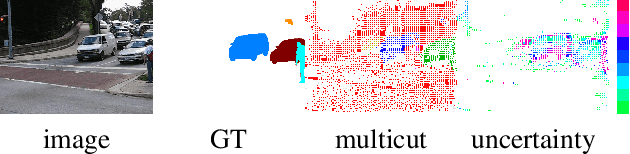


The minimum cost lifted multicut approach has proven practically good performance in a wide range of applications such as image decomposition, mesh segmentation, multiple object tracking, and motion segmentation. It addresses such problems in a graph-based model, where real-valued costs are assigned to the edges between entities such that the minimum cut decomposes the graph into an optimal number of segments. Driven by a probabilistic formulation of minimum cost multicuts, we provide a measure for the uncertainties of the decisions made during the optimization. We argue that access to such uncertainties is crucial for many practical applications and conduct an evaluation by means of sparsifications on three different, widely used datasets in the context of image decomposition (BSDS-500) and motion segmentation (DAVIS2016 and FBMS59) in terms of variation of information (VI) and Rand index (RI).
Self-supervised Sparse to Dense Motion Segmentation
Aug 18, 2020



Observable motion in videos can give rise to the definition of objects moving with respect to the scene. The task of segmenting such moving objects is referred to as motion segmentation and is usually tackled either by aggregating motion information in long, sparse point trajectories, or by directly producing per frame dense segmentations relying on large amounts of training data. In this paper, we propose a self supervised method to learn the densification of sparse motion segmentations from single video frames. While previous approaches towards motion segmentation build upon pre-training on large surrogate datasets and use dense motion information as an essential cue for the pixelwise segmentation, our model does not require pre-training and operates at test time on single frames. It can be trained in a sequence specific way to produce high quality dense segmentations from sparse and noisy input. We evaluate our method on the well-known motion segmentation datasets FBMS59 and DAVIS16.
Object Segmentation Tracking from Generic Video Cues
Oct 05, 2019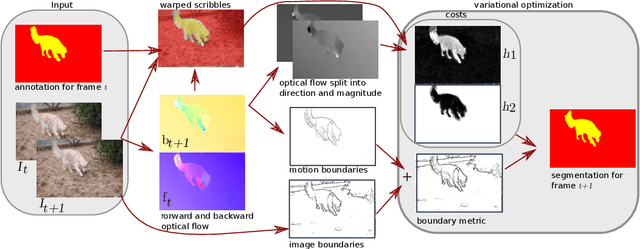
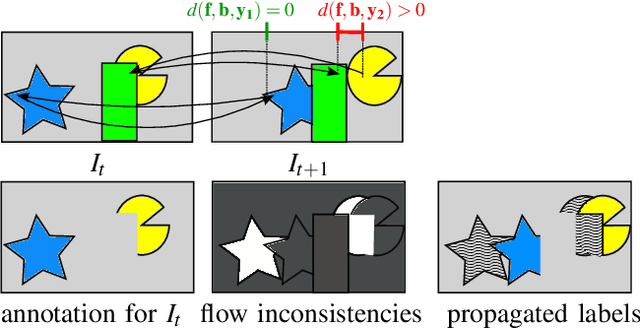
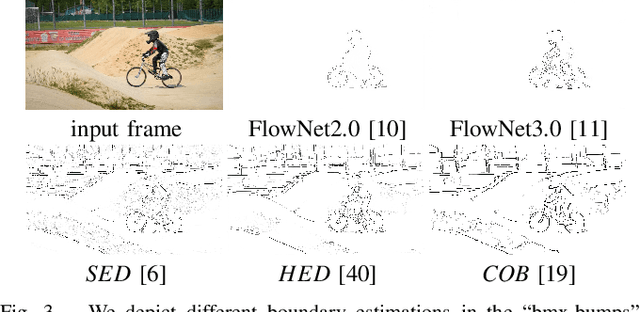

We propose a light-weight variational framework for online tracking of object segmentations in videos based on optical flow and image boundaries. While high-end computer vision methods on this task rely on sequence specific training of dedicated CNN architectures, we show the potential of a variational model, based on generic video information from motion and color. Such cues are usually required for tasks such as robot navigation or grasp estimation. We leverage them directly for video object segmentation and thus provide accurate segmentations at potentially very low extra cost. Furthermore, we show that our approach can be combined with state-of-the-art CNN-based segmentations in order to improve over their respective results. We evaluate our method on the datasets DAVIS16,17 and SegTrack v2.