 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the Robustness of Classification Models by the Structure of the Learned Feature-Space
Jun 23, 2021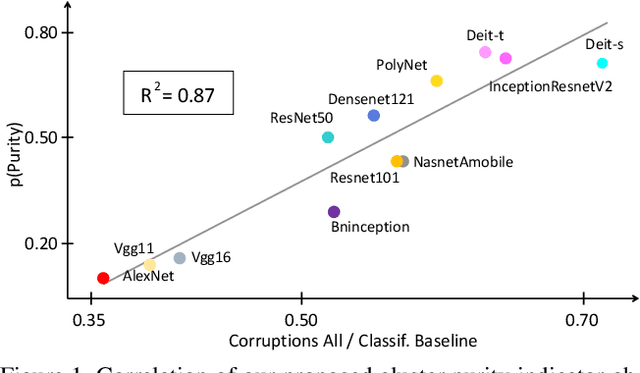
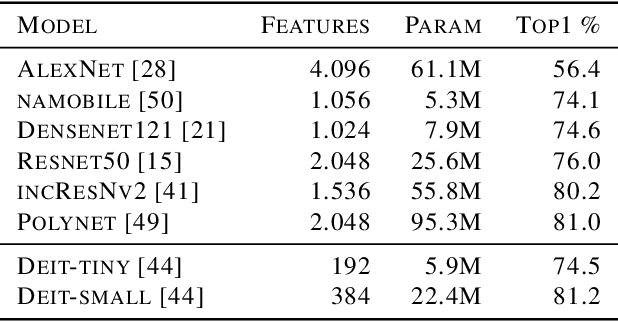
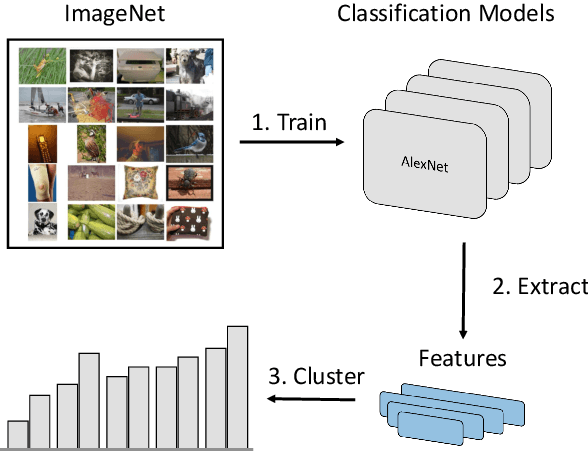
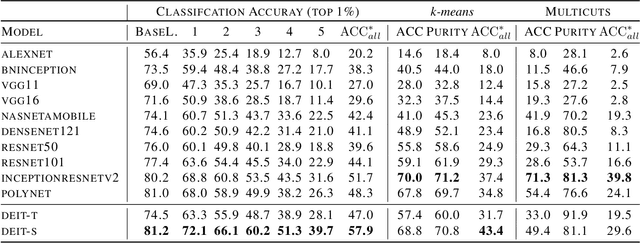
Over the last decade, the development of deep image classification networks has mostly been driven by the search for the best performance in terms of classification accuracy on standardized benchmarks like ImageNet. More recently, this focus has been expanded by the notion of model robustness, i.e. the generalization abilities of models towards previously unseen changes in the data distribution. While new benchmarks, like ImageNet-C, have been introduced to measure robustness properties, we argue that fixed testsets are only able to capture a small portion of possible data variations and are thus limited and prone to generate new overfitted solutions. To overcome these drawbacks, we suggest to estimate the robustness of a model directly from the structure of its learned feature-space. We introduce robustness indicators which are obtained via unsupervised clustering of latent representations inside a trained classifier and show very high correlations to the model performance on corrupted test data.
Latent Space Conditioning on Generative Adversarial Networks
Dec 16, 2020
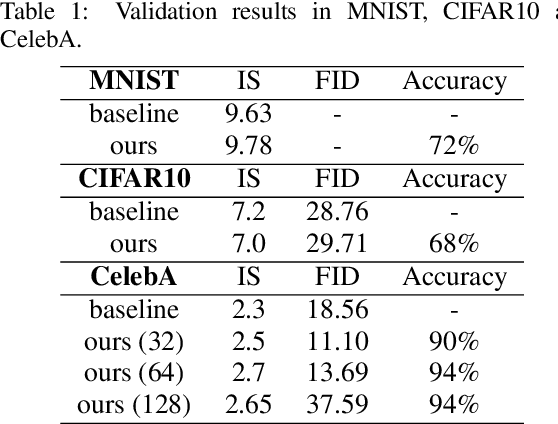

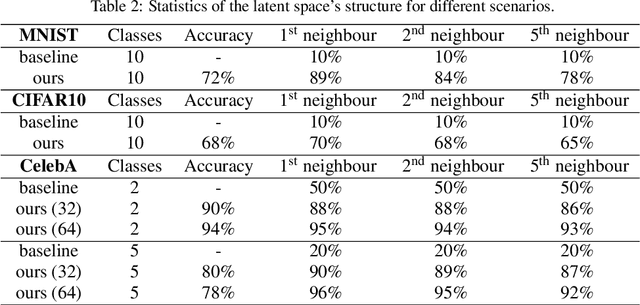
Generative adversarial networks are the state of the art approach towards learned synthetic image generation. Although early successes were mostly unsupervised, bit by bit, this trend has been superseded by approaches based on labelled data. These supervised methods allow a much finer-grained control of the output image, offering more flexibility and stability. Nevertheless, the main drawback of such models is the necessity of annotated data. In this work, we introduce an novel framework that benefits from two popular learning techniques, adversarial training and representation learning, and takes a step towards unsupervised conditional GANs. In particular, our approach exploits the structure of a latent space (learned by the representation learning) and employs it to condition the generative model. In this way, we break the traditional dependency between condition and label, substituting the latter by unsupervised features coming from the latent space. Finally, we show that this new technique is able to produce samples on demand keeping the quality of its supervised counterpart.
Self-supervised Sparse to Dense Motion Segmentation
Aug 18, 2020



Observable motion in videos can give rise to the definition of objects moving with respect to the scene. The task of segmenting such moving objects is referred to as motion segmentation and is usually tackled either by aggregating motion information in long, sparse point trajectories, or by directly producing per frame dense segmentations relying on large amounts of training data. In this paper, we propose a self supervised method to learn the densification of sparse motion segmentations from single video frames. While previous approaches towards motion segmentation build upon pre-training on large surrogate datasets and use dense motion information as an essential cue for the pixelwise segmentation, our model does not require pre-training and operates at test time on single frames. It can be trained in a sequence specific way to produce high quality dense segmentations from sparse and noisy input. We evaluate our method on the well-known motion segmentation datasets FBMS59 and DAVIS16.
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Jul 06, 2020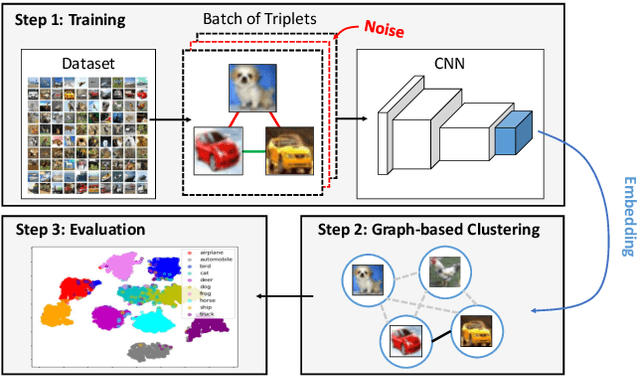
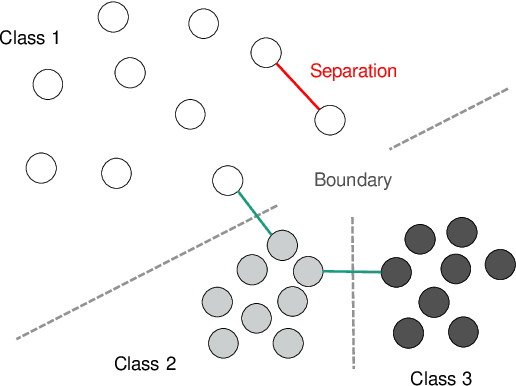
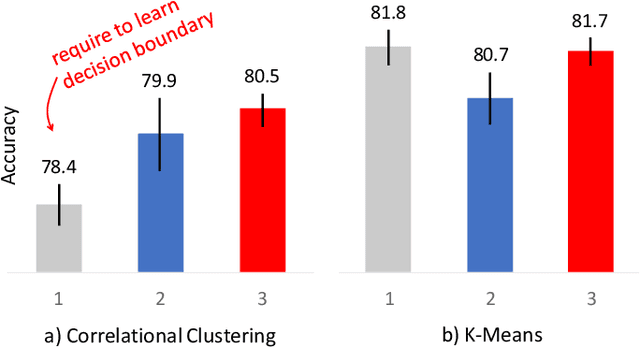
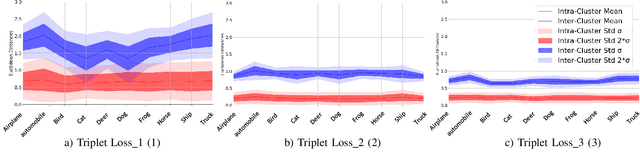
In this work, we evaluate two different image clustering objectives, k-means clustering and correlation clustering, in the context of Triplet Loss induced feature space embeddings. Specifically, we train a convolutional neural network to learn discriminative features by optimizing two popular versions of the Triplet Loss in order to study their clustering properties under the assumption of noisy labels. Additionally, we propose a new, simple Triplet Loss formulation, which shows desirable properties with respect to formal clustering objectives and outperforms the existing methods. We evaluate all three Triplet loss formulations for K-means and correlation clustering on the CIFAR-10 image classification dataset.
Unsupervised Multiple Person Tracking using AutoEncoder-Based Lifted Multicuts
Feb 04, 2020
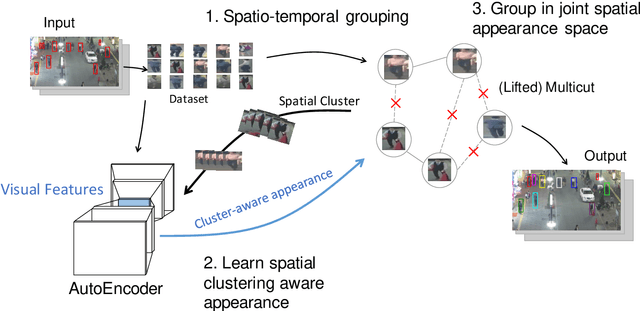


Multiple Object Tracking (MOT) is a long-standing task in computer vision. Current approaches based on the tracking by detection paradigm either require some sort of domain knowledge or supervision to associate data correctly into tracks. In this work, we present an unsupervised multiple object tracking approach based on visual features and minimum cost lifted multicuts. Our method is based on straight-forward spatio-temporal cues that can be extracted from neighboring frames in an image sequences without superivison. Clustering based on these cues enables us to learn the required appearance invariances for the tracking task at hand and train an autoencoder to generate suitable latent representation. Thus, the resulting latent representations can serve as robust appearance cues for tracking even over large temporal distances where no reliable spatio-temporal features could be extracted. We show that, despite being trained without using the provided annotations, our model provides competitive results on the challenging MOT Benchmark for pedestrian tracking.