 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOSC: A toolbox for aerial imagery mapping
Jun 09, 2024



Accurate and efficient label of aerial images is essential for informed decision-making and resource allocation, whether in identifying crop types or delineating land-use patterns. The development of a comprehensive toolbox for manipulating and annotating aerial imagery represents a significant leap forward in remote sensing and spatial analysis. In this report, we introduce BOSC, a toolbox that enables researchers and practitioners to extract actionable insights with unprecedented accuracy and efficiency, addressing a critical need in today's abundance of drone and satellite resources. For more information or to explore BOSC, please visit our repository.
Adversarial Examples are Misaligned in Diffusion Model Manifolds
Jan 17, 2024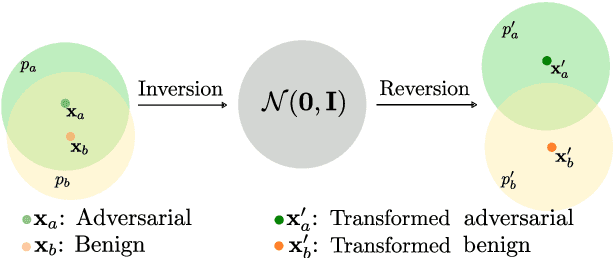
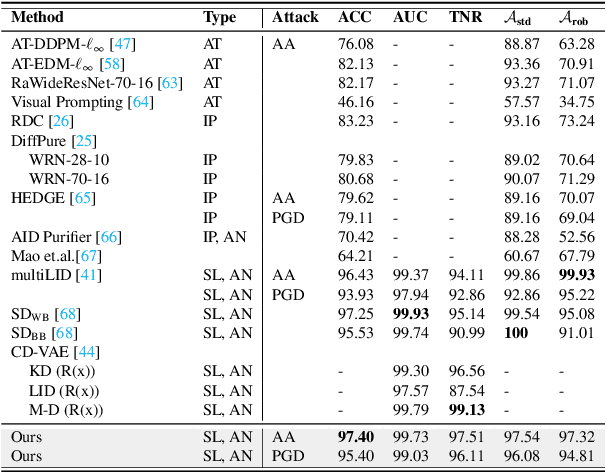
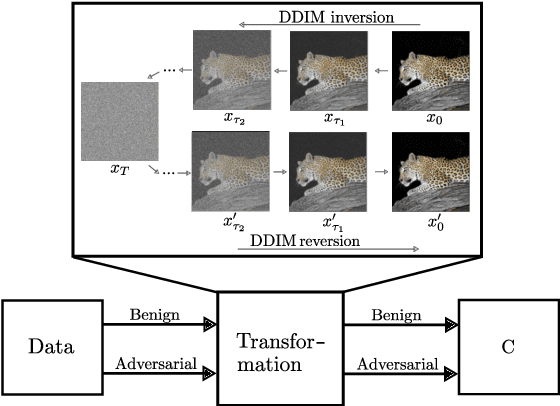
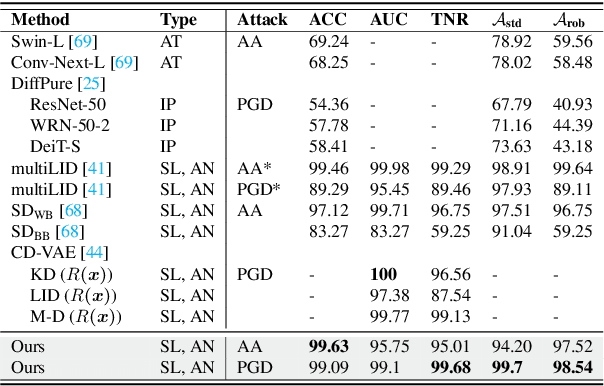
In recent years, diffusion models (DMs) have drawn significant attention for their success in approximating data distributions, yielding state-of-the-art generative results. Nevertheless, the versatility of these models extends beyond their generative capabilities to encompass various vision applications, such as image inpainting, segmentation, adversarial robustness, among others. This study is dedicated to the investigation of adversarial attacks through the lens of diffusion models. However, our objective does not involve enhancing the adversarial robustness of image classifiers. Instead, our focus lies in utilizing the diffusion model to detect and analyze the anomalies introduced by these attacks on images. To that end, we systematically examine the alignment of the distributions of adversarial examples when subjected to the process of transformation using diffusion models. The efficacy of this approach is assessed across CIFAR-10 and ImageNet datasets, including varying image sizes in the latter. The results demonstrate a notable capacity to discriminate effectively between benign and attacked images, providing compelling evidence that adversarial instances do not align with the learned manifold of the DMs.
Detecting Images Generated by Deep Diffusion Models using their Local Intrinsic Dimensionality
Jul 20, 2023



Diffusion models recently have been successfully applied for the visual synthesis of strikingly realistic appearing images. This raises strong concerns about their potential for malicious purposes. In this paper, we propose using the lightweight multi Local Intrinsic Dimensionality (multiLID), which has been originally developed in context of the detection of adversarial examples, for the automatic detection of synthetic images and the identification of the according generator networks. In contrast to many existing detection approaches, which often only work for GAN-generated images, the proposed method provides close to perfect detection results in many realistic use cases. Extensive experiments on known and newly created datasets demonstrate that the proposed multiLID approach exhibits superiority in diffusion detection and model identification. Since the empirical evaluations of recent publications on the detection of generated images are often mainly focused on the "LSUN-Bedroom" dataset, we further establish a comprehensive benchmark for the detection of diffusion-generated images, including samples from several diffusion models with different image sizes.
Deep Diffusion Models for Seismic Processing
Jul 21, 2022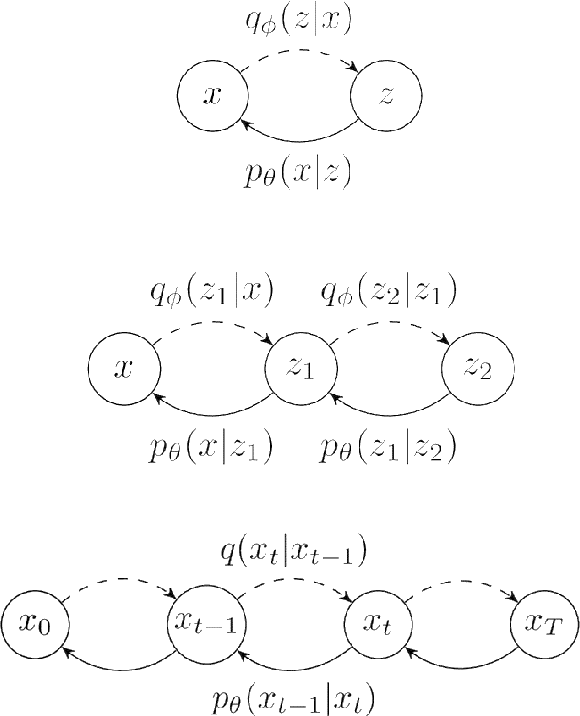
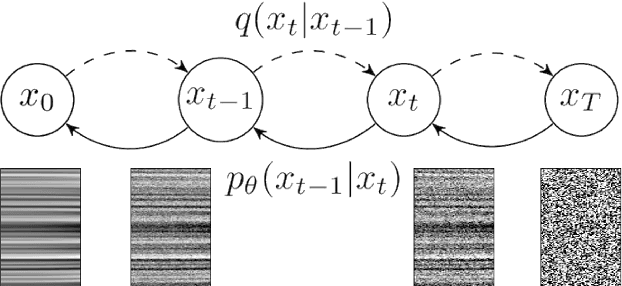
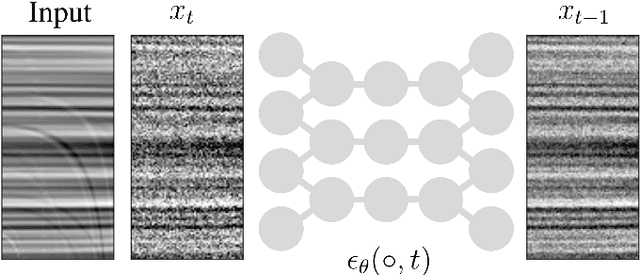
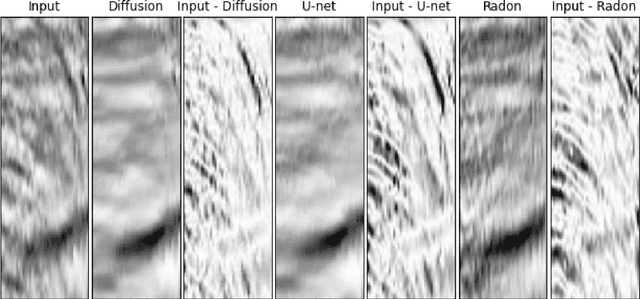
Seismic data processing involves techniques to deal with undesired effects that occur during acquisition and pre-processing. These effects mainly comprise coherent artefacts such as multiples, non-coherent signals such as electrical noise, and loss of signal information at the receivers that leads to incomplete traces. In the past years, there has been a remarkable increase of machine-learning-based solutions that have addressed the aforementioned issues. In particular, deep-learning practitioners have usually relied on heavily fine-tuned, customized discriminative algorithms. Although, these methods can provide solid results, they seem to lack semantic understanding of the provided data. Motivated by this limitation, in this work, we employ a generative solution, as it can explicitly model complex data distributions and hence, yield to a better decision-making process. In particular, we introduce diffusion models for three seismic applications: demultiple, denoising and interpolation. To that end, we run experiments on synthetic and on real data, and we compare the diffusion performance with standardized algorithms. We believe that our pioneer study not only demonstrates the capability of diffusion models, but also opens the door to future research to integrate generative models in seismic workflows.
Dissecting U-net for Seismic Application: An In-Depth Study on Deep Learning Multiple Removal
Jun 24, 2022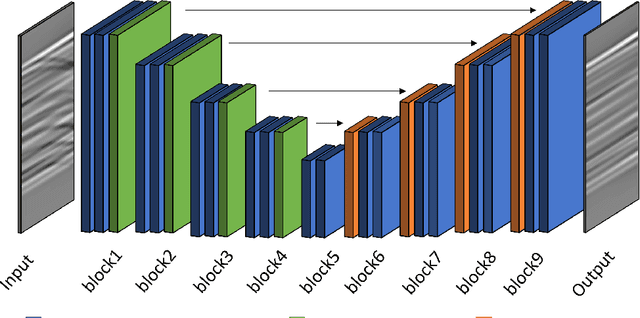
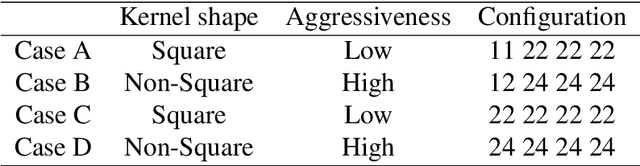


Seismic processing often requires suppressing multiples that appear when collecting data. To tackle these artifacts, practitioners usually rely on Radon transform-based algorithms as post-migration gather conditioning. However, such traditional approaches are both time-consuming and parameter-dependent, making them fairly complex. In this work, we present a deep learning-based alternative that provides competitive results, while reducing its usage's complexity, and hence democratizing its applicability. We observe an excellent performance of our network when inferring complex field data, despite the fact of being solely trained on synthetics. Furthermore, extensive experiments show that our proposal can preserve the inherent characteristics of the data, avoiding undesired over-smoothed results, while removing the multiples. Finally, we conduct an in-depth analysis of the model, where we pinpoint the effects of the main hyperparameters with physical events. To the best of our knowledge, this study pioneers the unboxing of neural networks for the demultiple process, helping the user to gain insights into the inside running of the network.
Investigating Shifts in GAN Output-Distributions
Dec 28, 2021


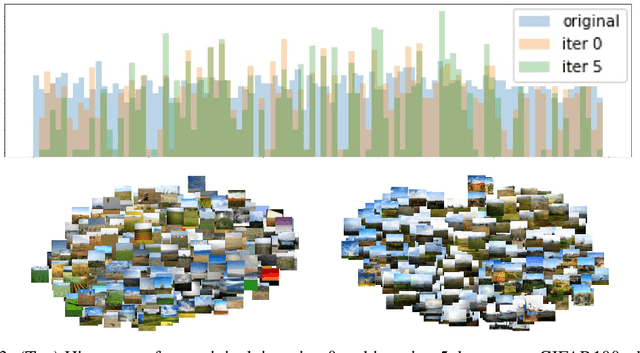
A fundamental and still largely unsolved question in the context of Generative Adversarial Networks is whether they are truly able to capture the real data distribution and, consequently, to sample from it. In particular, the multidimensional nature of image distributions leads to a complex evaluation of the diversity of GAN distributions. Existing approaches provide only a partial understanding of this issue, leaving the question unanswered. In this work, we introduce a loop-training scheme for the systematic investigation of observable shifts between the distributions of real training data and GAN generated data. Additionally, we introduce several bounded measures for distribution shifts, which are both easy to compute and to interpret. Overall, the combination of these methods allows an explorative investigation of innate limitations of current GAN algorithms. Our experiments on different data-sets and multiple state-of-the-art GAN architectures show large shifts between input and output distributions, showing that existing theoretical guarantees towards the convergence of output distributions appear not to be holding in practice.
FacialGAN: Style Transfer and Attribute Manipulation on Synthetic Faces
Oct 18, 2021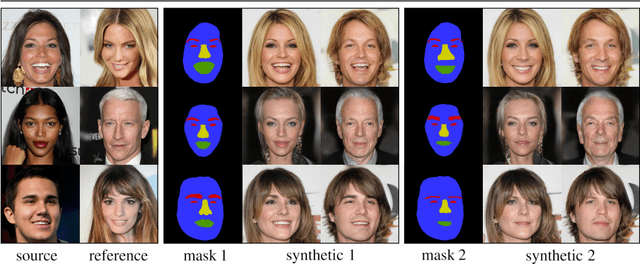
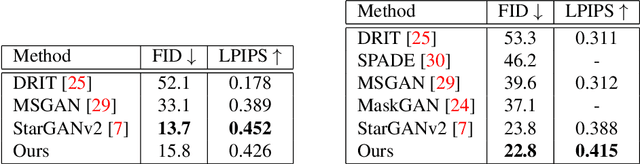
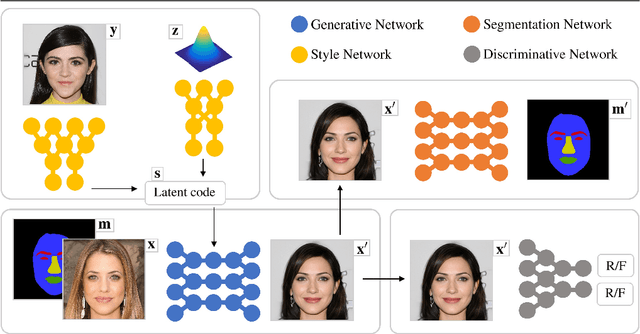

Facial image manipulation is a generation task where the output face is shifted towards an intended target direction in terms of facial attribute and styles. Recent works have achieved great success in various editing techniques such as style transfer and attribute translation. However, current approaches are either focusing on pure style transfer, or on the translation of predefined sets of attributes with restricted interactivity. To address this issue, we propose FacialGAN, a novel framework enabling simultaneous rich style transfers and interactive facial attributes manipulation. While preserving the identity of a source image, we transfer the diverse styles of a target image to the source image. We then incorporate the geometry information of a segmentation mask to provide a fine-grained manipulation of facial attributes. Finally, a multi-objective learning strategy is introduced to optimize the loss of each specific tasks. Experiments on the CelebA-HQ dataset, with CelebAMask-HQ as semantic mask labels, show our model's capacity in producing visually compelling results in style transfer, attribute manipulation, diversity and face verification. For reproducibility, we provide an interactive open-source tool to perform facial manipulations, and the Pytorch implementation of the model.
Combining Transformer Generators with Convolutional Discriminators
May 21, 2021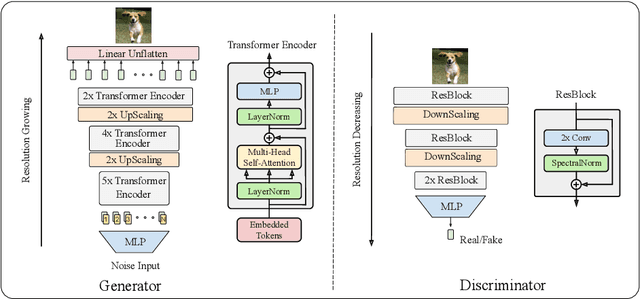
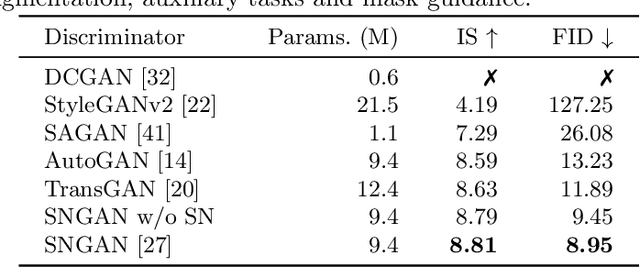
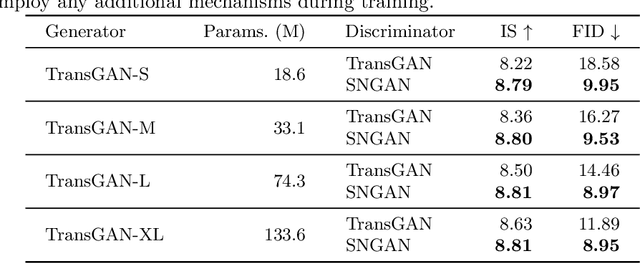

Transformer models have recently attracted much interest from computer vision researchers and have since been successfully employed for several problems traditionally addressed with convolutional neural networks. At the same time, image synthesis using generative adversarial networks (GANs) has drastically improved over the last few years. The recently proposed TransGAN is the first GAN using only transformer-based architectures and achieves competitive results when compared to convolutional GANs. However, since transformers are data-hungry architectures, TransGAN requires data augmentation, an auxiliary super-resolution task during training, and a masking prior to guide the self-attention mechanism. In this paper, we study the combination of a transformer-based generator and convolutional discriminator and successfully remove the need of the aforementioned required design choices. We evaluate our approach by conducting a benchmark of well-known CNN discriminators, ablate the size of the transformer-based generator, and show that combining both architectural elements into a hybrid model leads to better results. Furthermore, we investigate the frequency spectrum properties of generated images and observe that our model retains the benefits of an attention based generator.
Combating Mode Collapse in GAN training: An Empirical Analysis using Hessian Eigenvalues
Dec 17, 2020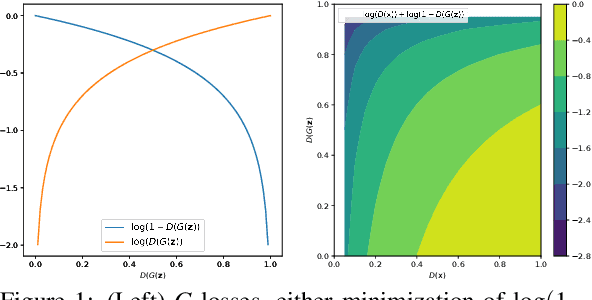
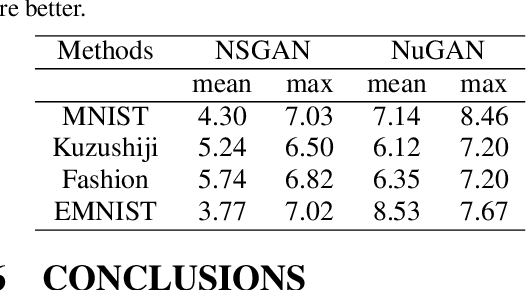
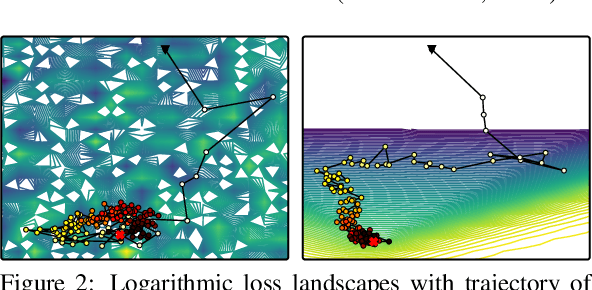
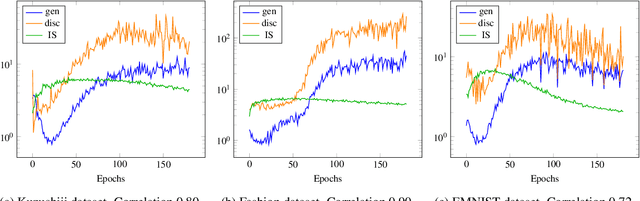
Generative adversarial networks (GANs) provide state-of-the-art results in image generation. However, despite being so powerful, they still remain very challenging to train. This is in particular caused by their highly non-convex optimization space leading to a number of instabilities. Among them, mode collapse stands out as one of the most daunting ones. This undesirable event occurs when the model can only fit a few modes of the data distribution, while ignoring the majority of them. In this work, we combat mode collapse using second-order gradient information. To do so, we analyse the loss surface through its Hessian eigenvalues, and show that mode collapse is related to the convergence towards sharp minima. In particular, we observe how the eigenvalues of the $G$ are directly correlated with the occurrence of mode collapse. Finally, motivated by these findings, we design a new optimization algorithm called nudged-Adam (NuGAN) that uses spectral information to overcome mode collapse, leading to empirically more stable convergence properties.
Latent Space Conditioning on Generative Adversarial Networks
Dec 16, 2020
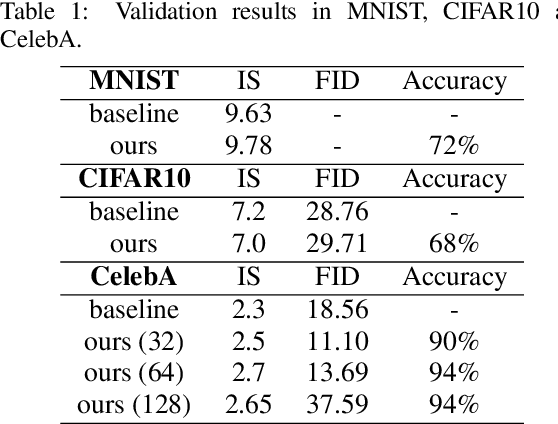

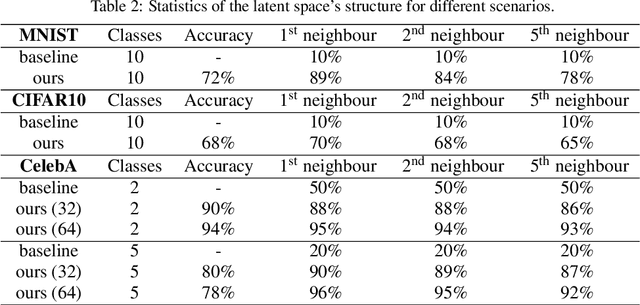
Generative adversarial networks are the state of the art approach towards learned synthetic image generation. Although early successes were mostly unsupervised, bit by bit, this trend has been superseded by approaches based on labelled data. These supervised methods allow a much finer-grained control of the output image, offering more flexibility and stability. Nevertheless, the main drawback of such models is the necessity of annotated data. In this work, we introduce an novel framework that benefits from two popular learning techniques, adversarial training and representation learning, and takes a step towards unsupervised conditional GANs. In particular, our approach exploits the structure of a latent space (learned by the representation learning) and employs it to condition the generative model. In this way, we break the traditional dependency between condition and label, substituting the latter by unsupervised features coming from the latent space. Finally, we show that this new technique is able to produce samples on demand keeping the quality of its supervised counterpart.