 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake or JPEG? Revealing Common Biases in Generated Image Detection Datasets
Mar 28, 2024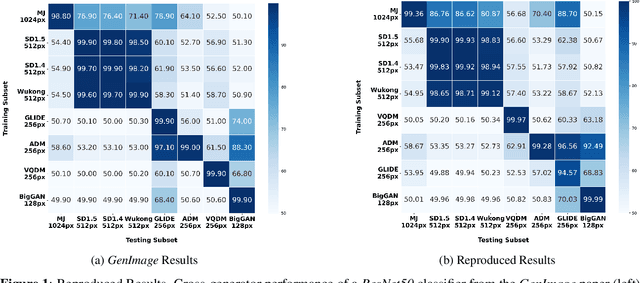
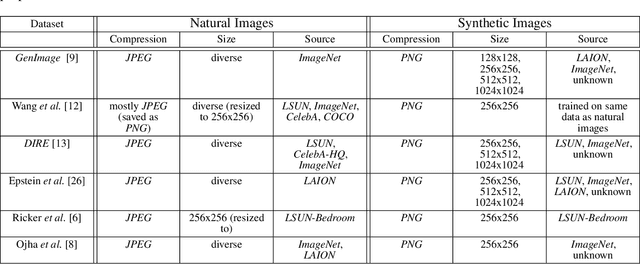
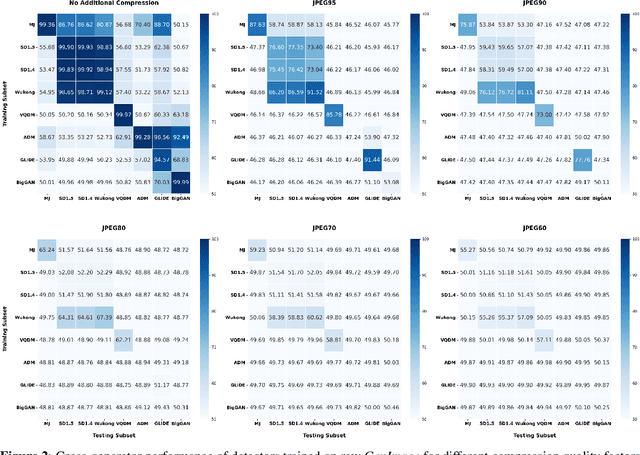

The widespread adoption of generative image models has highlighted the urgent need to detect artificial content, which is a crucial step in combating widespread manipulation and misinformation. Consequently, numerous detectors and associated datasets have emerged. However, many of these datasets inadvertently introduce undesirable biases, thereby impacting the effectiveness and evaluation of detectors. In this paper, we emphasize that many datasets for AI-generated image detection contain biases related to JPEG compression and image size. Using the GenImage dataset, we demonstrate that detectors indeed learn from these undesired factors. Furthermore, we show that removing the named biases substantially increases robustness to JPEG compression and significantly alters the cross-generator performance of evaluated detectors. Specifically, it leads to more than 11 percentage points increase in cross-generator performance for ResNet50 and Swin-T detectors on the GenImage dataset, achieving state-of-the-art results. We provide the dataset and source codes of this paper on the anonymous website: https://www.unbiased-genimage.org
Estimating the Robustness of Classification Models by the Structure of the Learned Feature-Space
Jun 23, 2021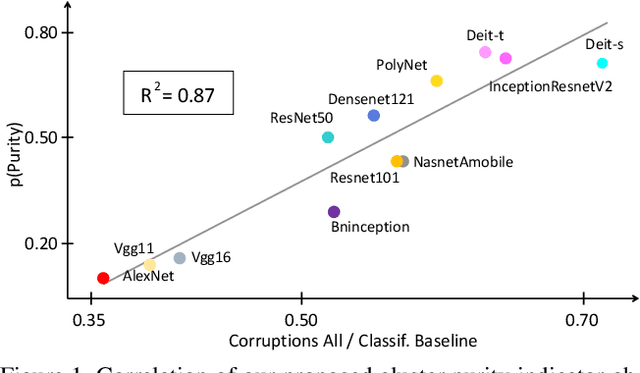
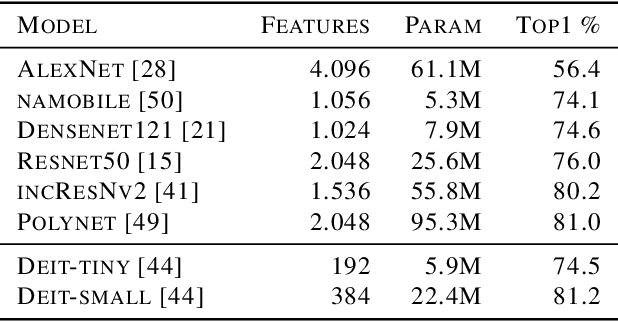
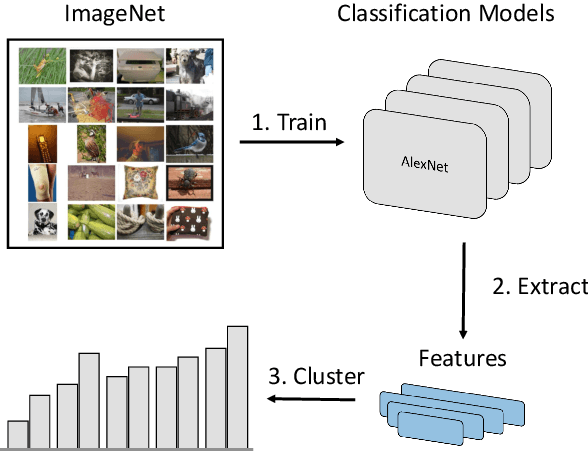
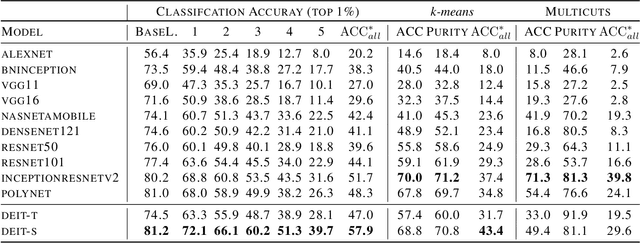
Over the last decade, the development of deep image classification networks has mostly been driven by the search for the best performance in terms of classification accuracy on standardized benchmarks like ImageNet. More recently, this focus has been expanded by the notion of model robustness, i.e. the generalization abilities of models towards previously unseen changes in the data distribution. While new benchmarks, like ImageNet-C, have been introduced to measure robustness properties, we argue that fixed testsets are only able to capture a small portion of possible data variations and are thus limited and prone to generate new overfitted solutions. To overcome these drawbacks, we suggest to estimate the robustness of a model directly from the structure of its learned feature-space. We introduce robustness indicators which are obtained via unsupervised clustering of latent representations inside a trained classifier and show very high correlations to the model performance on corrupted test data.
SpectralDefense: Detecting Adversarial Attacks on CNNs in the Fourier Domain
Mar 04, 2021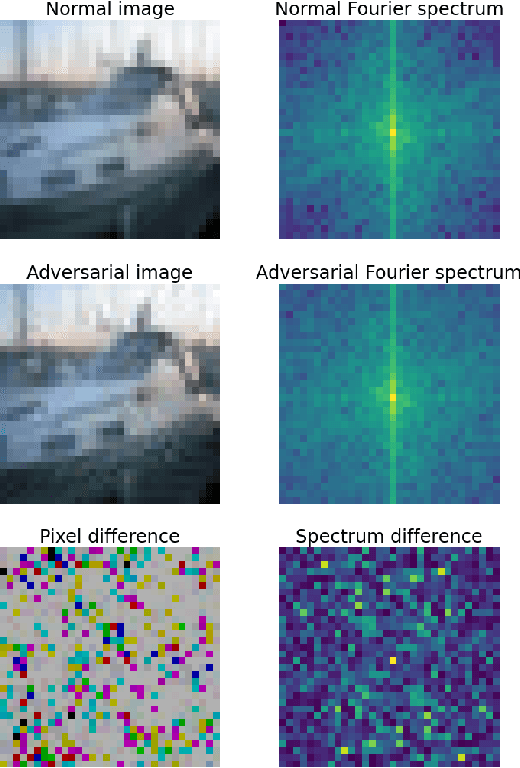

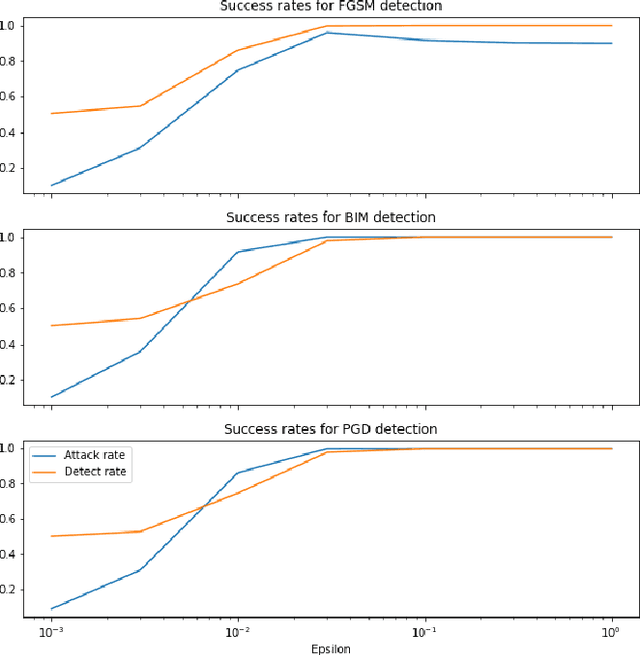
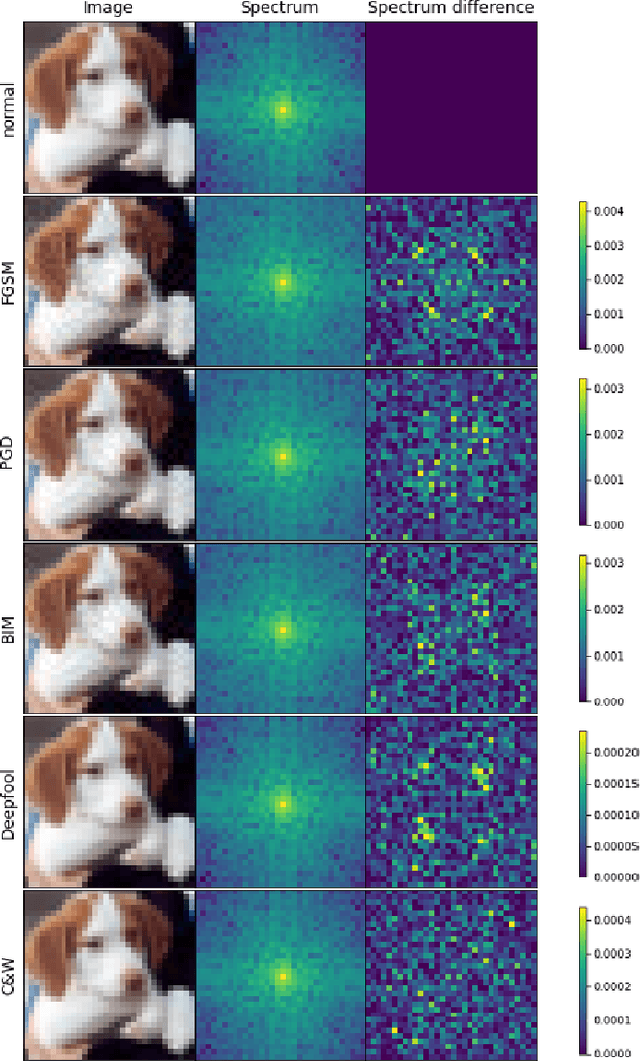
Despite the success of convolutional neural networks (CNNs) in many computer vision and image analysis tasks, they remain vulnerable against so-called adversarial attacks: Small, crafted perturbations in the input images can lead to false predictions. A possible defense is to detect adversarial examples. In this work, we show how analysis in the Fourier domain of input images and feature maps can be used to distinguish benign test samples from adversarial images. We propose two novel detection methods: Our first method employs the magnitude spectrum of the input images to detect an adversarial attack. This simple and robust classifier can successfully detect adversarial perturbations of three commonly used attack methods. The second method builds upon the first and additionally extracts the phase of Fourier coefficients of feature-maps at different layers of the network. With this extension, we are able to improve adversarial detection rates compared to state-of-the-art detectors on five different attack methods.
Latent Space Conditioning on Generative Adversarial Networks
Dec 16, 2020
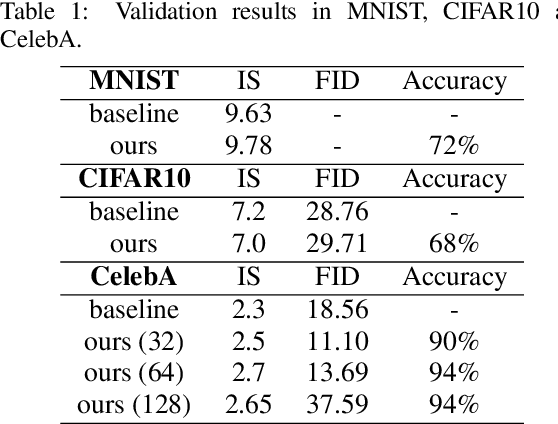

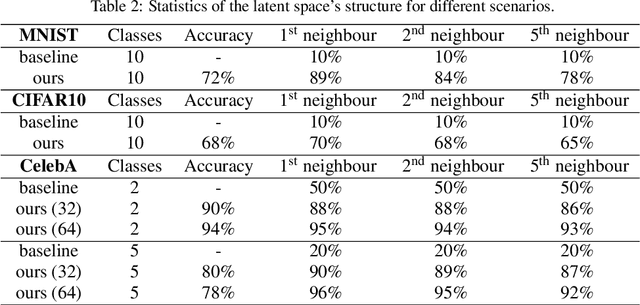
Generative adversarial networks are the state of the art approach towards learned synthetic image generation. Although early successes were mostly unsupervised, bit by bit, this trend has been superseded by approaches based on labelled data. These supervised methods allow a much finer-grained control of the output image, offering more flexibility and stability. Nevertheless, the main drawback of such models is the necessity of annotated data. In this work, we introduce an novel framework that benefits from two popular learning techniques, adversarial training and representation learning, and takes a step towards unsupervised conditional GANs. In particular, our approach exploits the structure of a latent space (learned by the representation learning) and employs it to condition the generative model. In this way, we break the traditional dependency between condition and label, substituting the latter by unsupervised features coming from the latent space. Finally, we show that this new technique is able to produce samples on demand keeping the quality of its supervised counterpart.
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Jul 06, 2020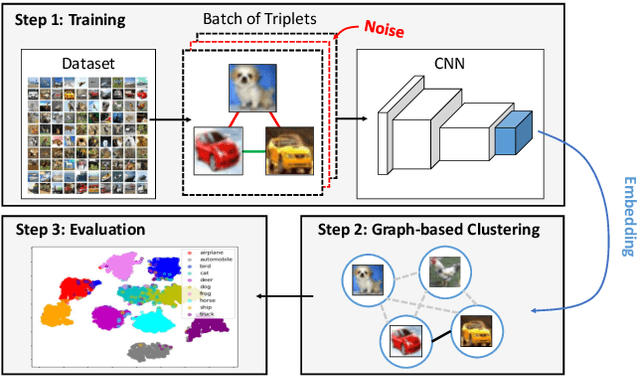
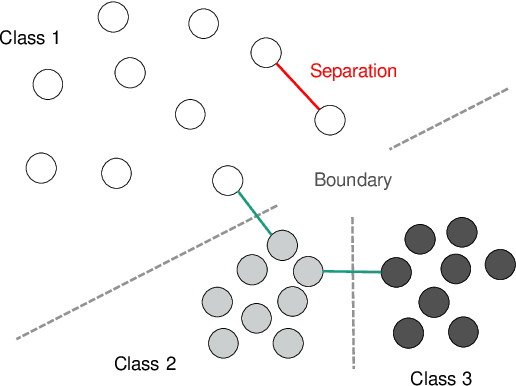
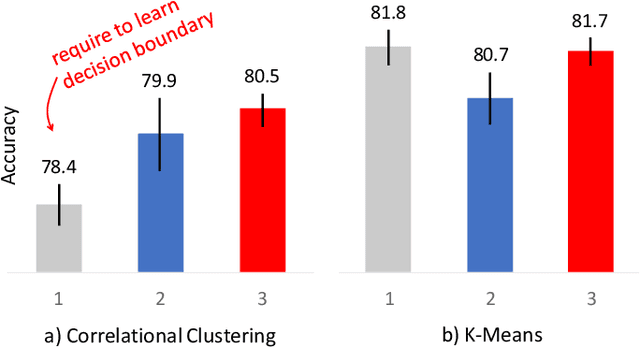
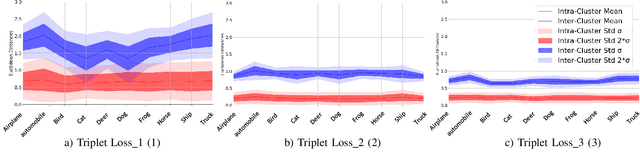
In this work, we evaluate two different image clustering objectives, k-means clustering and correlation clustering, in the context of Triplet Loss induced feature space embeddings. Specifically, we train a convolutional neural network to learn discriminative features by optimizing two popular versions of the Triplet Loss in order to study their clustering properties under the assumption of noisy labels. Additionally, we propose a new, simple Triplet Loss formulation, which shows desirable properties with respect to formal clustering objectives and outperforms the existing methods. We evaluate all three Triplet loss formulations for K-means and correlation clustering on the CIFAR-10 image classification dataset.
Local Facial Attribute Transfer through Inpainting
Feb 07, 2020
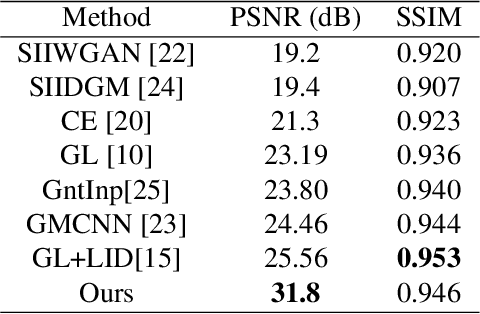
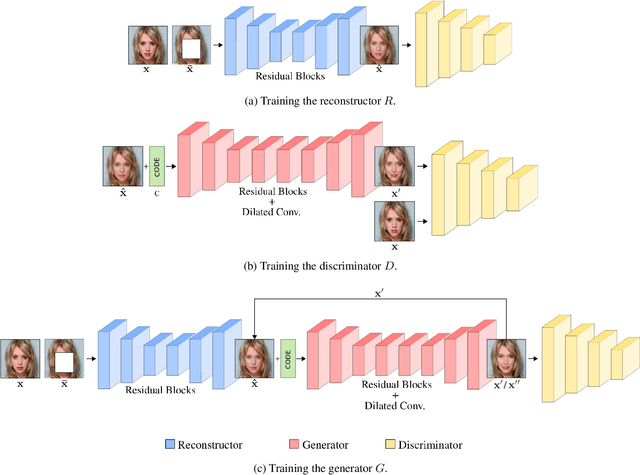
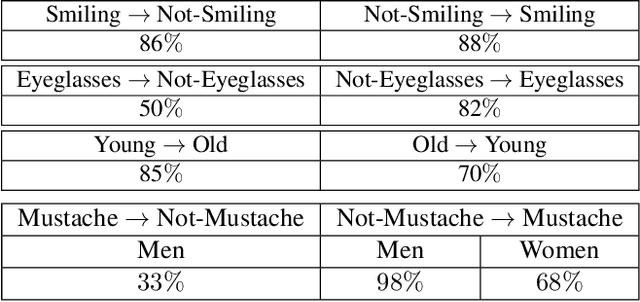
The term attribute transfer refers to the tasks of altering images in such a way, that the semantic interpretation of a given input image is shifted towards an intended direction, which is quantified by semantic attributes. Prominent example applications are photo realistic changes of facial features and expressions, like changing the hair color, adding a smile, enlarging the nose or altering the entire context of a scene, like transforming a summer landscape into a winter panorama. Recent advances in attribute transfer are mostly based on generative deep neural networks, using various techniques to manipulate images in the latent space of the generator. In this paper, we present a novel method for the common sub-task of local attribute transfers, where only parts of a face have to be altered in order to achieve semantic changes (e.g. removing a mustache). In contrast to previous methods, where such local changes have been implemented by generating new (global) images, we propose to formulate local attribute transfers as an inpainting problem. Removing and regenerating only parts of images, our Attribute Transfer Inpainting Generative Adversarial Network (ATI-GAN) is able to utilize local context information, resulting in visually sound results.
Scalable Hyperparameter Optimization with Lazy Gaussian Processes
Jan 16, 2020

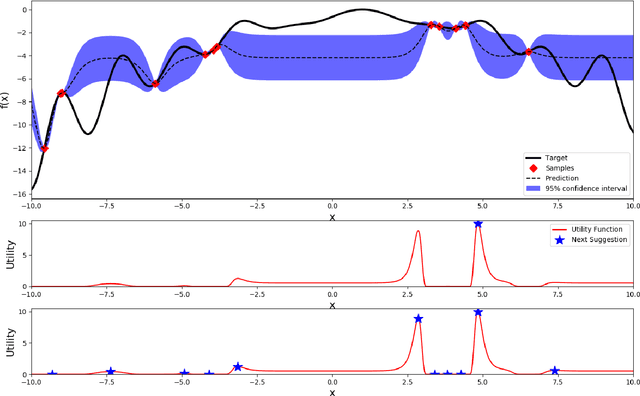
Most machine learning methods require careful selection of hyper-parameters in order to train a high performing model with good generalization abilities. Hence, several automatic selection algorithms have been introduced to overcome tedious manual (try and error) tuning of these parameters. Due to its very high sample efficiency, Bayesian Optimization over a Gaussian Processes modeling of the parameter space has become the method of choice. Unfortunately, this approach suffers from a cubic compute complexity due to underlying Cholesky factorization, which makes it very hard to be scaled beyond a small number of sampling steps. In this paper, we present a novel, highly accurate approximation of the underlying Gaussian Process. Reducing its computational complexity from cubic to quadratic allows an efficient strong scaling of Bayesian Optimization while outperforming the previous approach regarding optimization accuracy. The first experiments show speedups of a factor of 162 in single node and further speed up by a factor of 5 in a parallel environment.
Unmasking DeepFakes with simple Features
Nov 08, 2019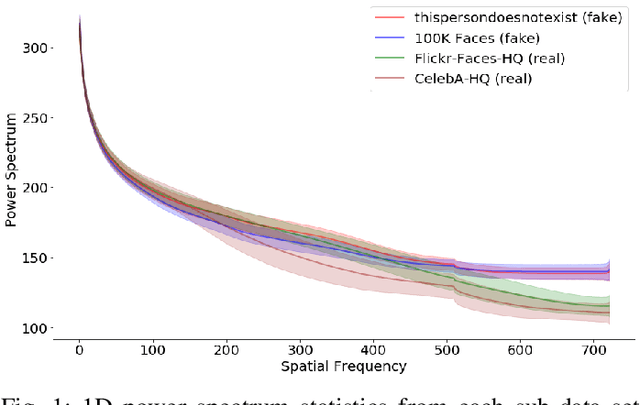
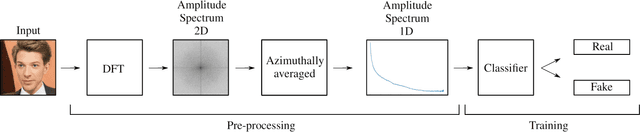

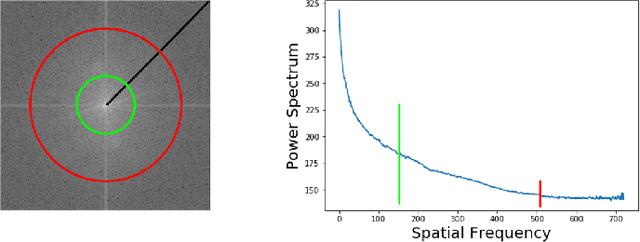
Deep generative models have recently achieved impressive results for many real-world applications, successfully generating high-resolution and diverse samples from complex datasets. Due to this improvement, fake digital contents have proliferated growing concern and spreading distrust in image content, leading to an urgent need for automated ways to detect these AI-generated fake images. Despite the fact that many face editing algorithms seem to produce realistic human faces, upon closer examination, they do exhibit artifacts in certain domains which are often hidden to the naked eye. In this work, we present a simple way to detect such fake face images - so-called DeepFakes. Our method is based on a classical frequency domain analysis followed by basic classifier. Compared to previous systems, which need to be fed with large amounts of labeled data, our approach showed very good results using only a few annotated training samples and even achieved good accuracies in fully unsupervised scenarios. For the evaluation on high resolution face images, we combined several public datasets of real and fake faces into a new benchmark: Faces-HQ. Given such high-resolution images, our approach reaches a perfect classification accuracy of 100% when it is trained on as little as 20 annotated samples. In a second experiment, in the evaluation of the medium-resolution images of the CelebA dataset, our method achieves 100% accuracy supervised and 96% in an unsupervised setting. Finally, evaluating a low-resolution video sequences of the FaceForensics++ dataset, our method achieves 91% accuracy detecting manipulated videos. Source Code: https://github.com/cc-hpc-itwm/DeepFakeDetection
Semi Few-Shot Attribute Translation
Oct 16, 2019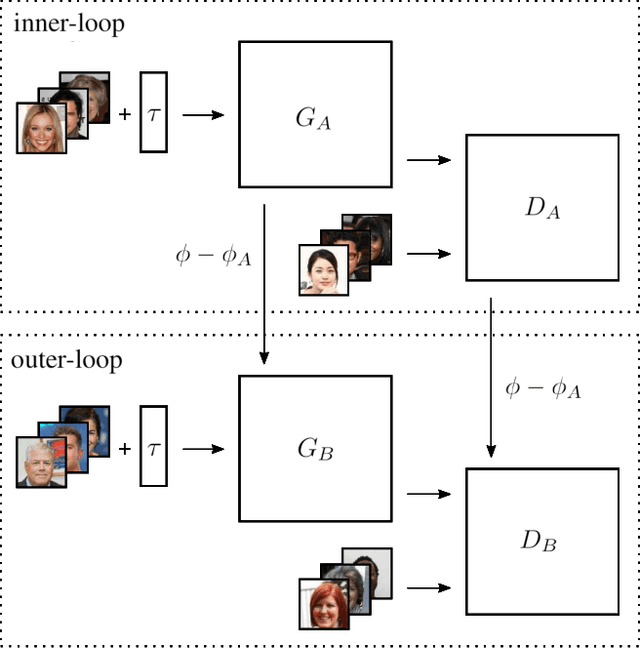
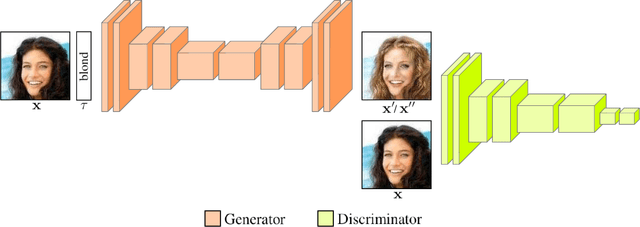


Recent studies have shown remarkable success in image-to-image translation for attribute transfer applications. However, most of existing approaches are based on deep learning and require an abundant amount of labeled data to produce good results, therefore limiting their applicability. In the same vein, recent advances in meta-learning have led to successful implementations with limited available data, allowing so-called few-shot learning. In this paper, we address this limitation of supervised methods, by proposing a novel approach based on GANs. These are trained in a meta-training manner, which allows them to perform image-to-image translations using just a few labeled samples from a new target class. This work empirically demonstrates the potential of training a GAN for few shot image-to-image translation on hair color attribute synthesis tasks, opening the door to further research on generative transfer learning.
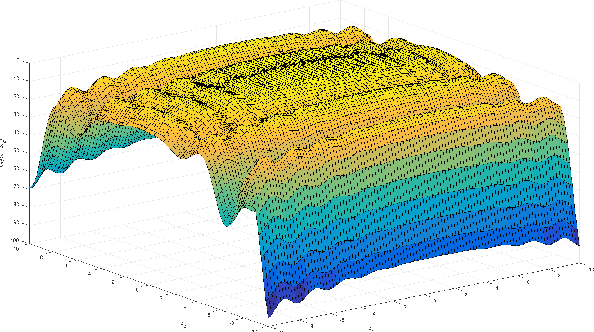
GradVis: Visualization and Second Order Analysis of Optimization Surfaces during the Training of Deep Neural Networks
Sep 27, 2019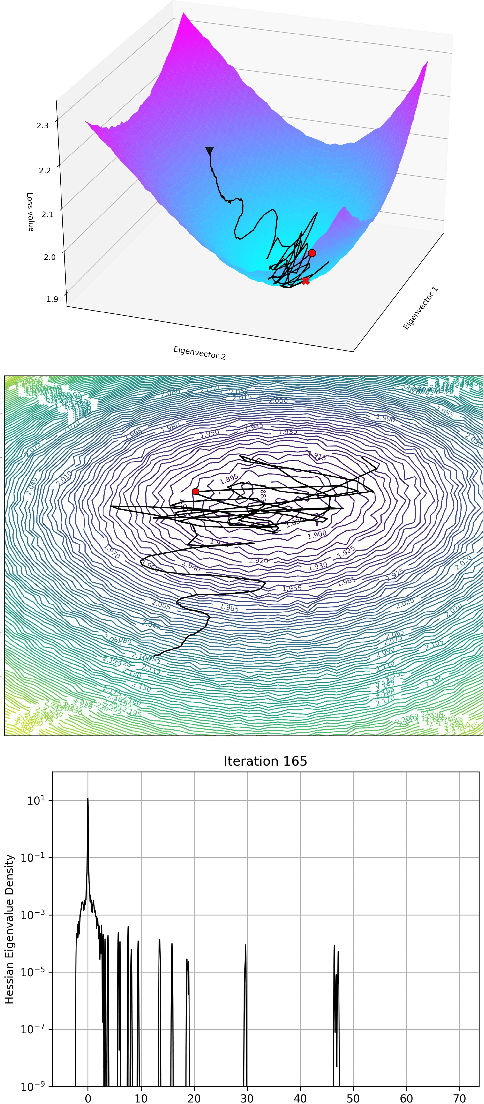



Current training methods for deep neural networks boil down to very high dimensional and non-convex optimization problems which are usually solved by a wide range of stochastic gradient descent methods. While these approaches tend to work in practice, there are still many gaps in the theoretical understanding of key aspects like convergence and generalization guarantees, which are induced by the properties of the optimization surface (loss landscape). In order to gain deeper insights, a number of recent publications proposed methods to visualize and analyze the optimization surfaces. However, the computational cost of these methods are very high, making it hardly possible to use them on larger networks. In this paper, we present the GradVis Toolbox, an open source library for efficient and scalable visualization and analysis of deep neural network loss landscapes in Tensorflow and PyTorch. Introducing more efficient mathematical formulations and a novel parallelization scheme, GradVis allows to plot 2d and 3d projections of optimization surfaces and trajectories, as well as high resolution second order gradient information for large networks.