 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples are Misaligned in Diffusion Model Manifolds
Paper and Code
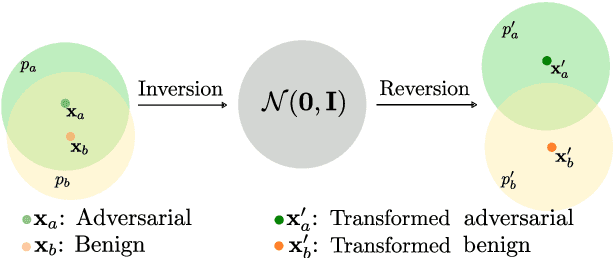
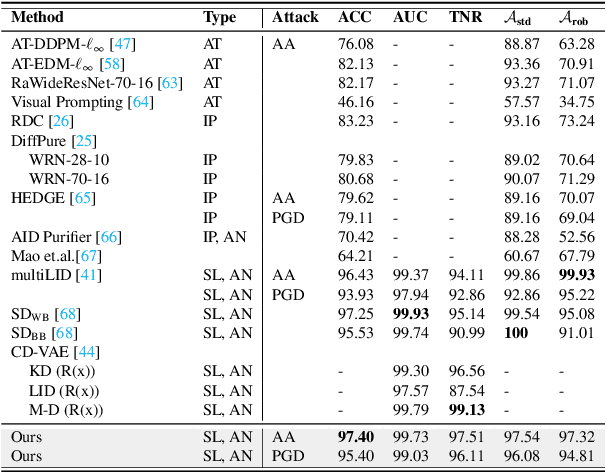
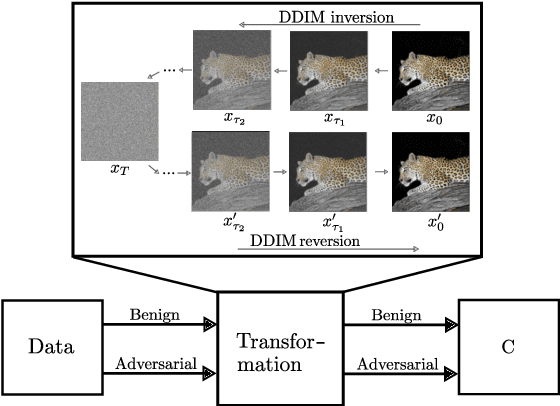
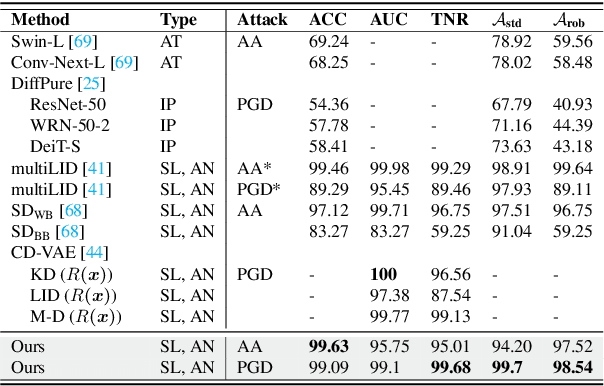
In recent years, diffusion models (DMs) have drawn significant attention for their success in approximating data distributions, yielding state-of-the-art generative results. Nevertheless, the versatility of these models extends beyond their generative capabilities to encompass various vision applications, such as image inpainting, segmentation, adversarial robustness, among others. This study is dedicated to the investigation of adversarial attacks through the lens of diffusion models. However, our objective does not involve enhancing the adversarial robustness of image classifiers. Instead, our focus lies in utilizing the diffusion model to detect and analyze the anomalies introduced by these attacks on images. To that end, we systematically examine the alignment of the distributions of adversarial examples when subjected to the process of transformation using diffusion models. The efficacy of this approach is assessed across CIFAR-10 and ImageNet datasets, including varying image sizes in the latter. The results demonstrate a notable capacity to discriminate effectively between benign and attacked images, providing compelling evidence that adversarial instances do not align with the learned manifold of the DMs.