 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multiple Person Tracking using AutoEncoder-Based Lifted Multicuts
Paper and Code
Feb 04, 2020
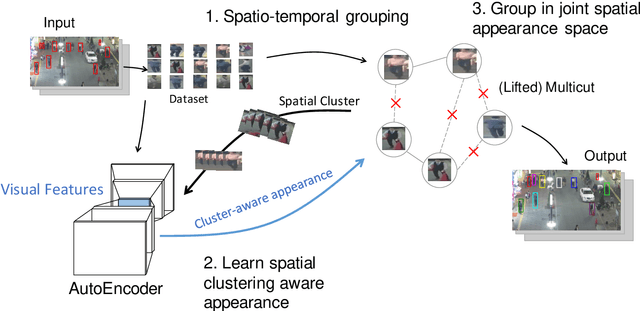


Multiple Object Tracking (MOT) is a long-standing task in computer vision. Current approaches based on the tracking by detection paradigm either require some sort of domain knowledge or supervision to associate data correctly into tracks. In this work, we present an unsupervised multiple object tracking approach based on visual features and minimum cost lifted multicuts. Our method is based on straight-forward spatio-temporal cues that can be extracted from neighboring frames in an image sequences without superivison. Clustering based on these cues enables us to learn the required appearance invariances for the tracking task at hand and train an autoencoder to generate suitable latent representation. Thus, the resulting latent representations can serve as robust appearance cues for tracking even over large temporal distances where no reliable spatio-temporal features could be extracted. We show that, despite being trained without using the provided annotations, our model provides competitive results on the challenging MOT Benchmark for pedestrian tracking.