 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRADE: Transfer of Distributions between External Conditions with Normalizing Flows
Oct 25, 2024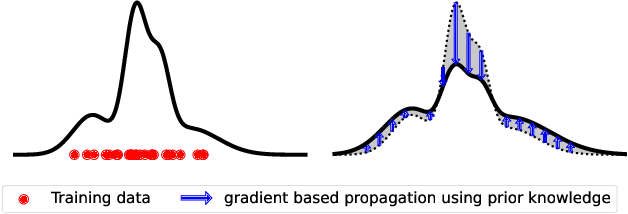



Modeling distributions that depend on external control parameters is a common scenario in diverse applications like molecular simulations, where system properties like temperature affect molecular configurations. Despite the relevance of these applications, existing solutions are unsatisfactory as they require severely restricted model architectures or rely on backward training, which is prone to unstable training. We introduce TRADE, which overcomes these limitations by formulating the learning process as a boundary value problem. By initially training the model for a specific condition using either i.i.d. samples or backward KL training, we establish a boundary distribution. We then propagate this information across other conditions using the gradient of the unnormalized density with respect to the external parameter. This formulation, akin to the principles of physics-informed neural networks, allows us to efficiently learn parameter-dependent distributions without restrictive assumptions. Experimentally, we demonstrate that TRADE achieves excellent results in a wide range of applications, ranging from Bayesian inference and molecular simulations to physical lattice models.
Learning Distributions on Manifolds with Free-form Flows
Dec 15, 2023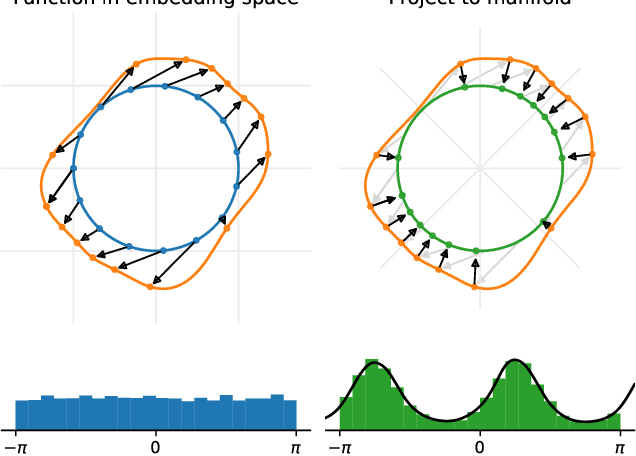

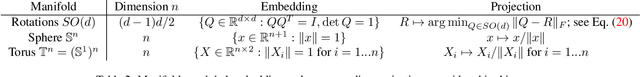
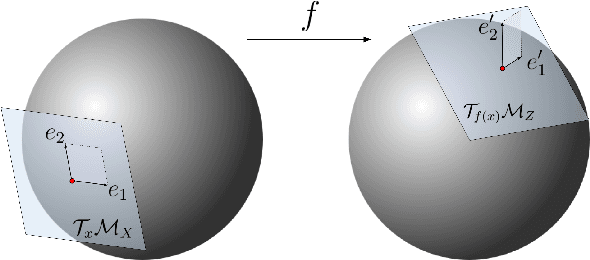
Many real world data, particularly in the natural sciences and computer vision, lie on known Riemannian manifolds such as spheres, tori or the group of rotation matrices. The predominant approaches to learning a distribution on such a manifold require solving a differential equation in order to sample from the model and evaluate densities. The resulting sampling times are slowed down by a high number of function evaluations. In this work, we propose an alternative approach which only requires a single function evaluation followed by a projection to the manifold. Training is achieved by an adaptation of the recently proposed free-form flow framework to Riemannian manifolds. The central idea is to estimate the gradient of the negative log-likelihood via a trace evaluated in the tangent space. We evaluate our method on various manifolds, and find significantly faster inference at competitive performance compared to previous work. We make our code public at https://github.com/vislearn/FFF.
Free-form Flows: Make Any Architecture a Normalizing Flow
Oct 25, 2023

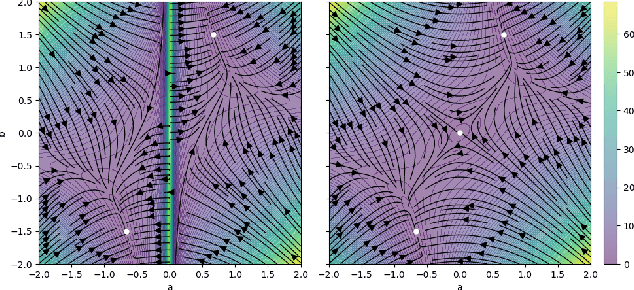
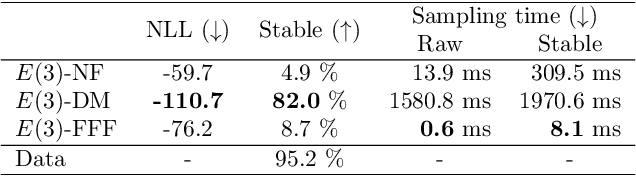
Normalizing Flows are generative models that directly maximize the likelihood. Previously, the design of normalizing flows was largely constrained by the need for analytical invertibility. We overcome this constraint by a training procedure that uses an efficient estimator for the gradient of the change of variables formula. This enables any dimension-preserving neural network to serve as a generative model through maximum likelihood training. Our approach allows placing the emphasis on tailoring inductive biases precisely to the task at hand. Specifically, we achieve excellent results in molecule generation benchmarks utilizing $E(n)$-equivariant networks. Moreover, our method is competitive in an inverse problem benchmark, while employing off-the-shelf ResNet architectures.
On the Convergence Rate of Gaussianization with Random Rotations
Jun 23, 2023



Gaussianization is a simple generative model that can be trained without backpropagation. It has shown compelling performance on low dimensional data. As the dimension increases, however, it has been observed that the convergence speed slows down. We show analytically that the number of required layers scales linearly with the dimension for Gaussian input. We argue that this is because the model is unable to capture dependencies between dimensions. Empirically, we find the same linear increase in cost for arbitrary input $p(x)$, but observe favorable scaling for some distributions. We explore potential speed-ups and formulate challenges for further research.
Maximum Likelihood Training of Autoencoders
Jun 02, 2023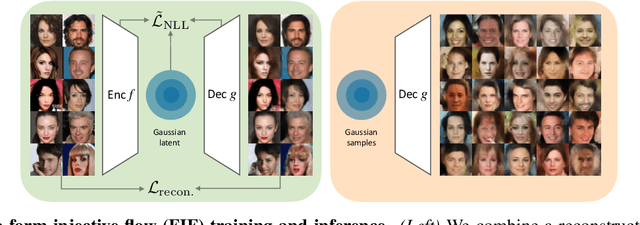

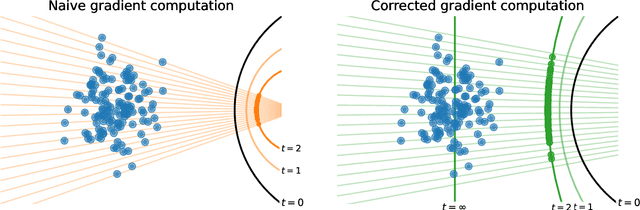

Maximum likelihood training has favorable statistical properties and is popular for generative modeling, especially with normalizing flows. On the other hand, generative autoencoders promise to be more efficient than normalizing flows due to the manifold hypothesis. In this work, we introduce successful maximum likelihood training of unconstrained autoencoders for the first time, bringing the two paradigms together. To do so, we identify and overcome two challenges: Firstly, existing maximum likelihood estimators for free-form networks are unacceptably slow, relying on iteration schemes whose cost scales linearly with latent dimension. We introduce an improved estimator which eliminates iteration, resulting in constant cost (roughly double the runtime per batch of a vanilla autoencoder). Secondly, we demonstrate that naively applying maximum likelihood to autoencoders can lead to divergent solutions and use this insight to motivate a stable maximum likelihood training objective. We perform extensive experiments on toy, tabular and image data, demonstrating the competitive performance of the resulting model. We call our model the maximum likelihood autoencoder (MLAE).
Generative Invertible Quantum Neural Networks
Feb 24, 2023



Invertible Neural Networks (INN) have become established tools for the simulation and generation of highly complex data. We propose a quantum-gate algorithm for a Quantum Invertible Neural Network (QINN) and apply it to the LHC data of jet-associated production of a Z-boson that decays into leptons, a standard candle process for particle collider precision measurements. We compare the QINN's performance for different loss functions and training scenarios. For this task, we find that a hybrid QINN matches the performance of a significantly larger purely classical INN in learning and generating complex data.
Generative Networks for Precision Enthusiasts
Oct 22, 2021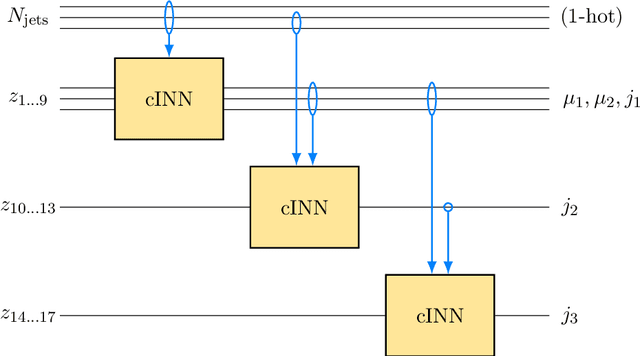
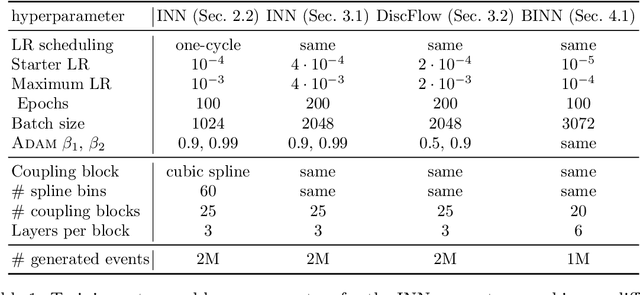
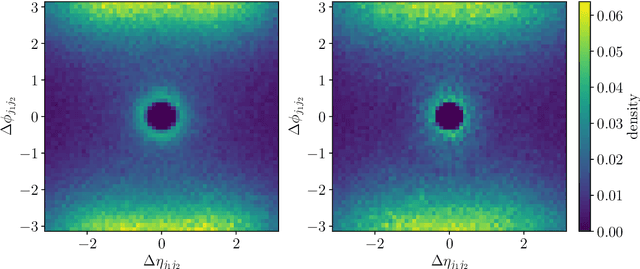
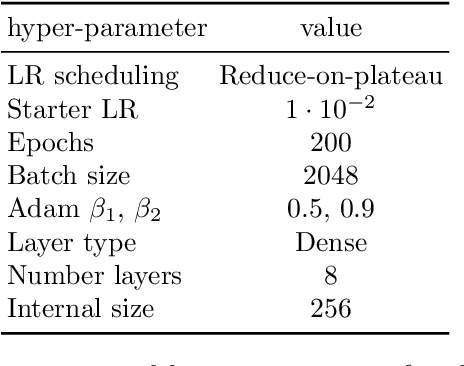
Generative networks are opening new avenues in fast event generation for the LHC. We show how generative flow networks can reach percent-level precision for kinematic distributions, how they can be trained jointly with a discriminator, and how this discriminator improves the generation. Our joint training relies on a novel coupling of the two networks which does not require a Nash equilibrium. We then estimate the generation uncertainties through a Bayesian network setup and through conditional data augmentation, while the discriminator ensures that there are no systematic inconsistencies compared to the training data.