 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIVER: Quantum-Informed Views for Enhanced Representations in Large ML Models
Jun 01, 2026Large machine learning models benefit substantially from multimodal inputs that provide a complementary view of the same example. We introduce QUIVER (QUantum-Informed Views for Enhanced Representations, a paradigm that enriches classical data-driven features with a quantum Fisher view: a geometrically motivated, basis-independent summary of higher-order correlations captured by a variational quantum circuit (VQC) trained to perform the same task. Unlike classical feature augmentation, the quantum Fisher information matrix encodes the intrinsic geometry of the learned quantum state manifold. While this feature map, motivated by quantum information theory, is ordinarily non-trivial to model classically, it can surface statistical structure that additional classical data or model capacity finds difficult to learn. This makes the quantum Fisher view a genuinely complementary modality rather than a redundant one. We demonstrate that QUIVER improves standard performance metrics on two benchmark datasets from very different fields: QM9 for predicting molecule properties, and JetClass for predicting jet flavor at the Large Hadron Collider (LHC). The core contribution, however, is domain-agnostic: the quantum Fisher view can be fused into a broad class of model architectures via targeted modifications to the base architecture, to incorporate information about the quantum geometry of the problem. These results demonstrate that quantum-geometric features, extracted from simulated variational circuits, can deliver measurable value for standard machine learning tasks, well before the advent of fault-tolerant quantum hardware.
From Information Geometry to Jet Substructure: A Triality of Cumulant Tensors, Energy Correlators, and Hypergraphs
May 04, 2026Pairwise Fisher graphs capture local covariance information, but they cannot distinguish an irreducible multi-observable radiation pattern from a collection of ordinary pairwise correlations. We show that this missing structure is naturally supplied by higher-order Fisher tensors. In a finite basis of binned EECs, ECFs, or EFPs, and in the natural exponential-family coordinates generated by that basis, the same local tensor has three equivalent interpretations: a coefficient in the local Kullback-Leibler expansion, a connected cumulant of the chosen correlator observables, and a signed weight on a hyperedge linking those observables. This gives an exact Fisher-correlator-hypergraph triality in the local exponential-family embedding. The triality provides a direct construction of physics-informed hypergraphs from correlator data. Extending the quadratic Fisher matrix to the first non-trivial higher tensor identifies genuinely connected multi-observable radiation patterns, supplies hyperedge weights for higher-order Laplacians and message passing, and gives a principled criterion for compressing observable bases beyond pairwise information. We develop these constructions and spell out why the exact cumulant interpretation is special to natural exponential-family coordinates. We illustrate the framework in four applications. In a minimal local-KL study, the cubic Fisher tensor reduces the KL truncation error and isolates the dominant triplet structure. In a two-versus-three prong jet substructure benchmark, the hypergraph selector improves compressed-basis classification. In a 33-observable basis-design problem, the Fisher hypergraph retains more third-order local response at twelve observables. A low-capacity learning benchmark then shows how the same Fisher hyperedges can be used as an interpretable inductive bias for message passing on correlator observables.
Quantum-Inspired Tensor Network Autoencoders for Anomaly Detection: A MERA-Based Approach
Apr 08, 2026We investigate whether a multiscale tensor-network architecture can provide a useful inductive bias for reconstruction-based anomaly detection in collider jets. Jets are produced by a branching cascade, so their internal structure is naturally organised across angular and momentum scales. This motivates an autoencoder that compresses information hierarchically and can reorganise short-range correlations before coarse-graining. Guided by this picture, we formulate a MERA-inspired autoencoder acting directly on ordered jet constituents. To the best of our knowledge, a MERA-inspired autoencoder has not previously been proposed, and this architecture has not been explored in collider anomaly detection. We compare this architecture to a dense autoencoder, the corresponding tree-tensor-network limit, and standard classical baselines within a common background-only reconstruction framework. The paper is organised around two main questions: whether locality-aware hierarchical compression is genuinely supported by the data, and whether the disentangling layers of MERA contribute beyond a simpler tree hierarchy. To address these questions, we combine benchmark comparisons with a training-free local-compressibility diagnostic and a direct identity-disentangler ablation. The resulting picture is that the locality-preserving multiscale structure is well matched to jet data, and that the MERA disentanglers become beneficial precisely when the compression bottleneck is strongest. Overall, the study supports locality-aware hierarchical compression as a useful inductive bias for jet anomaly detection.
From Reachability to Learnability: Geometric Design Principles for Quantum Neural Networks
Mar 03, 2026Classical deep networks are effective because depth enables adaptive geometric deformation of data representations. In quantum neural networks (QNNs), however, depth or state reachability alone does not guarantee this feature-learning capability. We study this question in the pure-state setting by viewing encoded data as an embedded manifold in $\mathbb{C}P^{2^n-1}$ and analysing infinitesimal unitary actions through Lie-algebra directions. We introduce Classical-to-Lie-algebra (CLA) maps and the criterion of almost Complete Local Selectivity (aCLS), which combines directional completeness with data-dependent local selectivity. Within this framework, we show that data-independent trainable unitaries are complete but non-selective, i.e. learnable rigid reorientations, whereas pure data encodings are selective but non-tunable, i.e. fixed deformations. Hence, geometric flexibility requires a non-trivial joint dependence on data and trainable weights. We further show that accessing high-dimensional deformations of many-qubit state manifolds requires parametrised entangling directions; fixed entanglers such as CNOT alone do not provide adaptive geometric control. Numerical examples validate that CLS-satisfying data re-uploading models outperform non-tunable schemes while requiring only a quarter of the gate operations. Thus, the resulting picture reframes QNN design from state reachability to controllable geometry of hidden quantum representations.
Machine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
Another Fit Bites the Dust: Conformal Prediction as a Calibration Standard for Machine Learning in High-Energy Physics
Dec 18, 2025Machine-learning techniques are essential in modern collider research, yet their probabilistic outputs often lack calibrated uncertainty estimates and finite-sample guarantees, limiting their direct use in statistical inference and decision-making. Conformal prediction (CP) provides a simple, distribution-free framework for calibrating arbitrary predictive models without retraining, yielding rigorous uncertainty quantification with finite-sample coverage guarantees under minimal exchangeability assumptions, without reliance on asymptotics, limit theorems, or Gaussian approximations. In this work, we investigate CP as a unifying calibration layer for machine-learning applications in high-energy physics. Using publicly available collider datasets and a diverse set of models, we show that a single conformal formalism can be applied across regression, binary and multi-class classification, anomaly detection, and generative modelling, converting raw model outputs into statistically valid prediction sets, typicality regions, and p-values with controlled false-positive rates. While conformal prediction does not improve raw model performance, it enforces honest uncertainty quantification and transparent error control. We argue that conformal calibration should be adopted as a standard component of machine-learning pipelines in collider physics, enabling reliable interpretation, robust comparisons, and principled statistical decisions in experimental and phenomenological analyses.
Improved Ground State Estimation in Quantum Field Theories via Normalising Flow-Assisted Neural Quantum States
Jun 13, 2025We propose a hybrid variational framework that enhances Neural Quantum States (NQS) with a Normalising Flow-based sampler to improve the expressivity and trainability of quantum many-body wavefunctions. Our approach decouples the sampling task from the variational ansatz by learning a continuous flow model that targets a discretised, amplitude-supported subspace of the Hilbert space. This overcomes limitations of Markov Chain Monte Carlo (MCMC) and autoregressive methods, especially in regimes with long-range correlations and volume-law entanglement. Applied to the transverse-field Ising model with both short- and long-range interactions, our method achieves comparable ground state energy errors with state-of-the-art matrix product states and lower energies than autoregressive NQS. For systems up to 50 spins, we demonstrate high accuracy and robust convergence across a wide range of coupling strengths, including regimes where competing methods fail. Our results showcase the utility of flow-assisted sampling as a scalable tool for quantum simulation and offer a new approach toward learning expressive quantum states in high-dimensional Hilbert spaces.
Communicating Likelihoods with Normalising Flows
Feb 13, 2025
We present a machine-learning-based workflow to model an unbinned likelihood from its samples. A key advancement over existing approaches is the validation of the learned likelihood using rigorous statistical tests of the joint distribution, such as the Kolmogorov-Smirnov test of the joint distribution. Our method enables the reliable communication of experimental and phenomenological likelihoods for subsequent analyses. We demonstrate its effectiveness through three case studies in high-energy physics. To support broader adoption, we provide an open-source reference implementation, nabu.
Optimal Equivariant Architectures from the Symmetries of Matrix-Element Likelihoods
Oct 24, 2024The Matrix-Element Method (MEM) has long been a cornerstone of data analysis in high-energy physics. It leverages theoretical knowledge of parton-level processes and symmetries to evaluate the likelihood of observed events. In parallel, the advent of geometric deep learning has enabled neural network architectures that incorporate known symmetries directly into their design, leading to more efficient learning. This paper presents a novel approach that combines MEM-inspired symmetry considerations with equivariant neural network design for particle physics analysis. Even though Lorentz invariance and permutation invariance overall reconstructed objects are the largest and most natural symmetry in the input domain, we find that they are sub-optimal in most practical search scenarios. We propose a longitudinal boost-equivariant message-passing neural network architecture that preserves relevant discrete symmetries. We present numerical studies demonstrating MEM-inspired architectures achieve new state-of-the-art performance in distinguishing di-Higgs decays to four bottom quarks from the QCD background, with enhanced sample and parameter efficiencies. This synergy between MEM and equivariant deep learning opens new directions for physics-informed architecture design, promising more powerful tools for probing physics beyond the Standard Model.
Collective variables of neural networks: empirical time evolution and scaling laws
Oct 09, 2024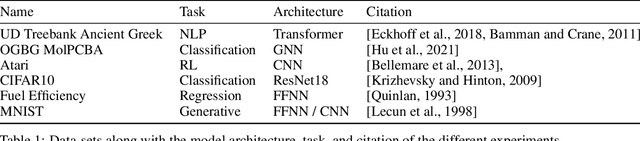
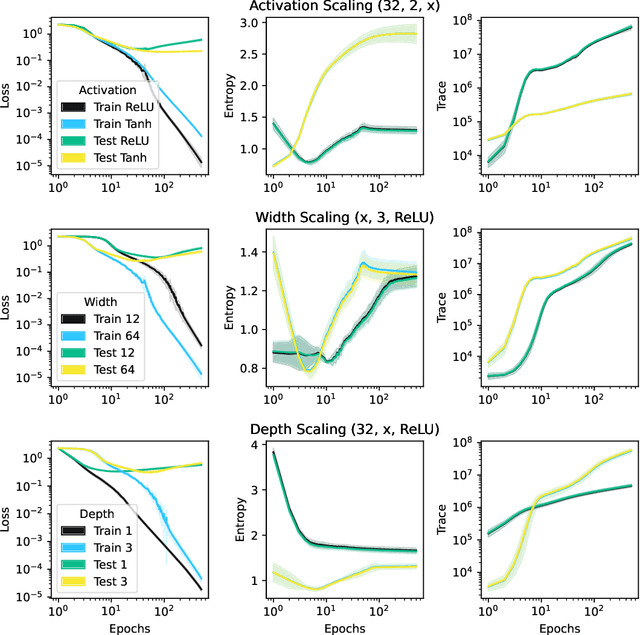
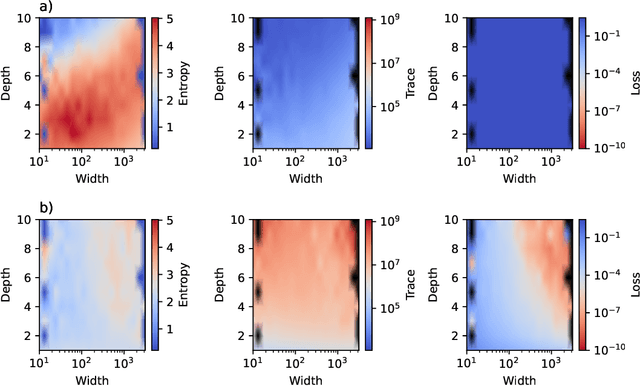
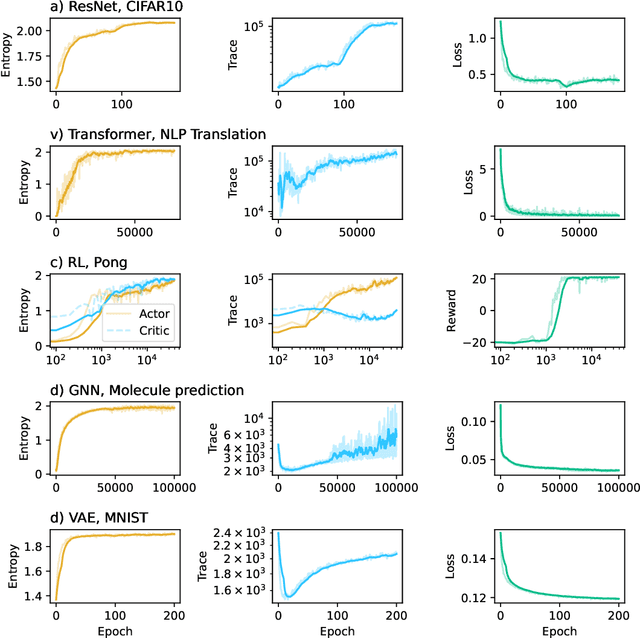
This work presents a novel means for understanding learning dynamics and scaling relations in neural networks. We show that certain measures on the spectrum of the empirical neural tangent kernel, specifically entropy and trace, yield insight into the representations learned by a neural network and how these can be improved through architecture scaling. These results are demonstrated first on test cases before being shown on more complex networks, including transformers, auto-encoders, graph neural networks, and reinforcement learning studies. In testing on a wide range of architectures, we highlight the universal nature of training dynamics and further discuss how it can be used to understand the mechanisms behind learning in neural networks. We identify two such dominant mechanisms present throughout machine learning training. The first, information compression, is seen through a reduction in the entropy of the NTK spectrum during training, and occurs predominantly in small neural networks. The second, coined structure formation, is seen through an increasing entropy and thus, the creation of structure in the neural network representations beyond the prior established by the network at initialization. Due to the ubiquity of the latter in deep neural network architectures and its flexibility in the creation of feature-rich representations, we argue that this form of evolution of the network's entropy be considered the onset of a deep learning regime.