 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Generative Models by Manifold Entropic Metrics
Oct 25, 2024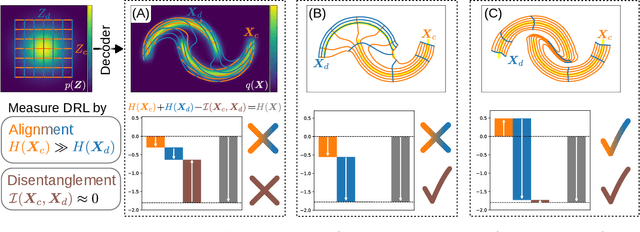
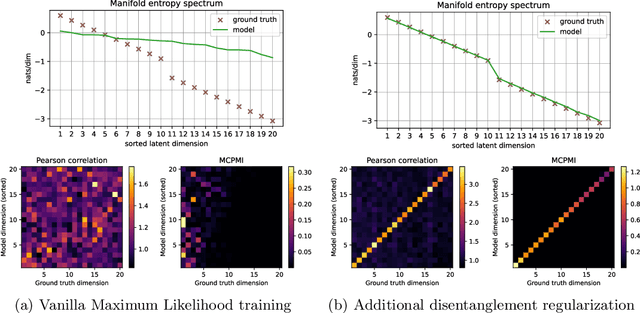
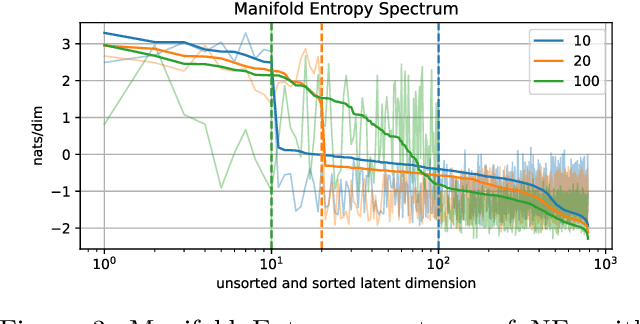
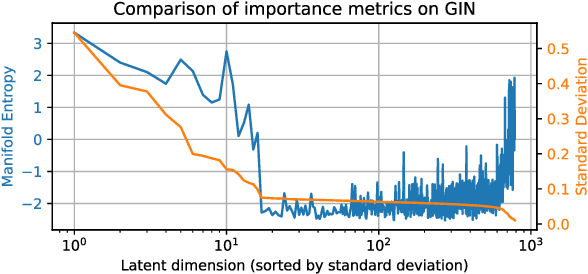
Good generative models should not only synthesize high quality data, but also utilize interpretable representations that aid human understanding of their behavior. However, it is difficult to measure objectively if and to what degree desirable properties of disentangled representations have been achieved. Inspired by the principle of independent mechanisms, we address this difficulty by introducing a novel set of tractable information-theoretic evaluation metrics. We demonstrate the usefulness of our metrics on illustrative toy examples and conduct an in-depth comparison of various normalizing flow architectures and $\beta$-VAEs on the EMNIST dataset. Our method allows to sort latent features by importance and assess the amount of residual correlations of the resulting concepts. The most interesting finding of our experiments is a ranking of model architectures and training procedures in terms of their inductive bias to converge to aligned and disentangled representations during training.