 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decentralized Policy Gradient Approach to Multi-task Reinforcement Learning
Jun 08, 2020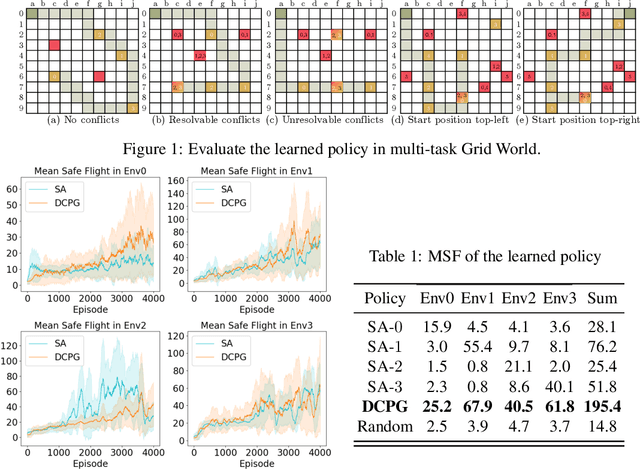
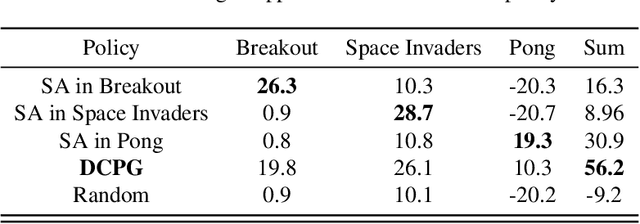

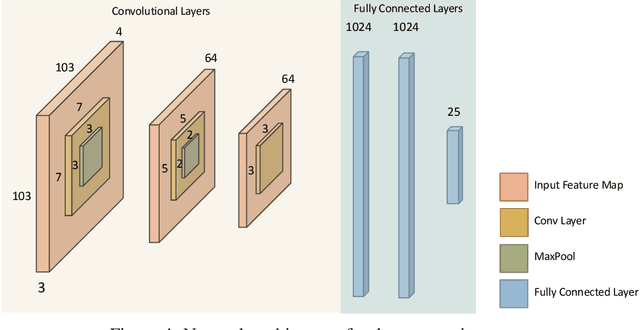
We develop a mathematical framework for solving multi-task reinforcement learning problems based on a type of decentralized policy gradient method. The goal in multi-task reinforcement learning is to learn a common policy that operates effectively in different environments; these environments have similar (or overlapping) state and action spaces, but have different rewards and dynamics. Agents immersed in each of these environments communicate with other agents by sharing their models (i.e. their policy parameterizations) but not their state/reward paths. Our analysis provides a convergence rate for a consensus-based distributed, entropy-regularized policy gradient method for finding such a policy. We demonstrate the effectiveness of the proposed method using a series of numerical experiments. These experiments range from small-scale "Grid World" problems that readily demonstrate the trade-offs involved in multi-task learning to large-scale problems, where common policies are learned to play multiple Atari games or to navigate an airborne drone in multiple (simulated) environments.