 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperator-Level Quantum Acceleration of Non-Logconcave Sampling
May 08, 2025Sampling from probability distributions of the form $\sigma \propto e^{-\beta V}$, where $V$ is a continuous potential, is a fundamental task across physics, chemistry, biology, computer science, and statistics. However, when $V$ is non-convex, the resulting distribution becomes non-logconcave, and classical methods such as Langevin dynamics often exhibit poor performance. We introduce the first quantum algorithm that provably accelerates a broad class of continuous-time sampling dynamics. For Langevin dynamics, our method encodes the target Gibbs measure into the amplitudes of a quantum state, identified as the kernel of a block matrix derived from a factorization of the Witten Laplacian operator. This connection enables Gibbs sampling via singular value thresholding and yields the first provable quantum advantage with respect to the Poincar\'e constant in the non-logconcave setting. Building on this framework, we further develop the first quantum algorithm that accelerates replica exchange Langevin diffusion, a widely used method for sampling from complex, rugged energy landscapes.
The ESPRIT algorithm under high noise: Optimal error scaling and noisy super-resolution
Apr 05, 2024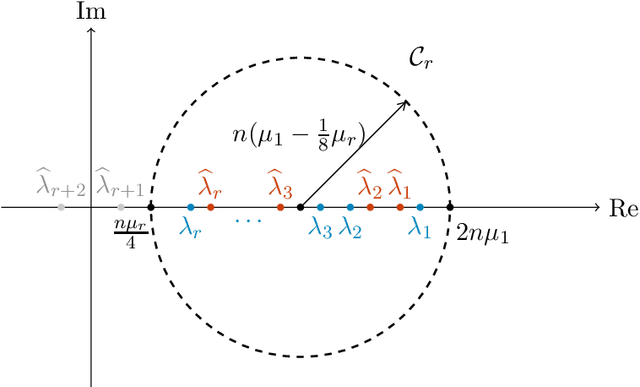
Subspace-based signal processing techniques, such as the Estimation of Signal Parameters via Rotational Invariant Techniques (ESPRIT) algorithm, are popular methods for spectral estimation. These algorithms can achieve the so-called super-resolution scaling under low noise conditions, surpassing the well-known Nyquist limit. However, the performance of these algorithms under high-noise conditions is not as well understood. Existing state-of-the-art analysis indicates that ESPRIT and related algorithms can be resilient even for signals where each observation is corrupted by statistically independent, mean-zero noise of size $\mathcal{O}(1)$, but these analyses only show that the error $\epsilon$ decays at a slow rate $\epsilon=\mathcal{\tilde{O}}(n^{-1/2})$ with respect to the cutoff frequency $n$. In this work, we prove that under certain assumptions of bias and high noise, the ESPRIT algorithm can attain a significantly improved error scaling $\epsilon = \mathcal{\tilde{O}}(n^{-3/2})$, exhibiting noisy super-resolution scaling beyond the Nyquist limit. We further establish a theoretical lower bound and show that this scaling is optimal. Our analysis introduces novel matrix perturbation results, which could be of independent interest.
Convergence of stochastic gradient descent on parameterized sphere with applications to variational Monte Carlo simulation
Mar 24, 2023



We analyze stochastic gradient descent (SGD) type algorithms on a high-dimensional sphere which is parameterized by a neural network up to a normalization constant. We provide a new algorithm for the setting of supervised learning and show its convergence both theoretically and numerically. We also provide the first proof of convergence for the unsupervised setting, which corresponds to the widely used variational Monte Carlo (VMC) method in quantum physics.
On the Global Convergence of Gradient Descent for multi-layer ResNets in the mean-field regime
Oct 06, 2021Finding the optimal configuration of parameters in ResNet is a nonconvex minimization problem, but first-order methods nevertheless find the global optimum in the overparameterized regime. We study this phenomenon with mean-field analysis, by translating the training process of ResNet to a gradient-flow partial differential equation (PDE) and examining the convergence properties of this limiting process. The activation function is assumed to be $2$-homogeneous or partially $1$-homogeneous; the regularized ReLU satisfies the latter condition. We show that if the ResNet is sufficiently large, with depth and width depending algebraically on the accuracy and confidence levels, first-order optimization methods can find global minimizers that fit the training data.
Overparameterization of deep ResNet: zero loss and mean-field analysis
Jun 17, 2021Finding parameters in a deep neural network (NN) that fit training data is a nonconvex optimization problem, but a basic first-order optimization method (gradient descent) finds a global solution with perfect fit in many practical situations. We examine this phenomenon for the case of Residual Neural Networks (ResNet) with smooth activation functions in a limiting regime in which both the number of layers (depth) and the number of neurons in each layer (width) go to infinity. First, we use a mean-field-limit argument to prove that the gradient descent for parameter training becomes a partial differential equation (PDE) that characterizes gradient flow for a probability distribution in the large-NN limit. Next, we show that the solution to the PDE converges in the training time to a zero-loss solution. Together, these results imply that training of the ResNet also gives a near-zero loss if the Resnet is large enough. We give estimates of the depth and width needed to reduce the loss below a given threshold, with high probability.
Constrained Ensemble Langevin Monte Carlo
Feb 08, 2021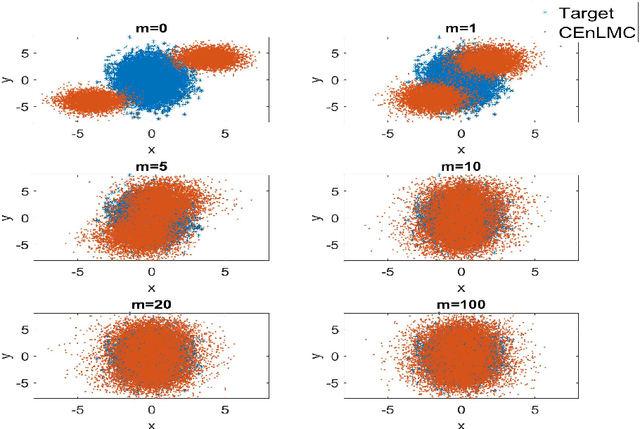
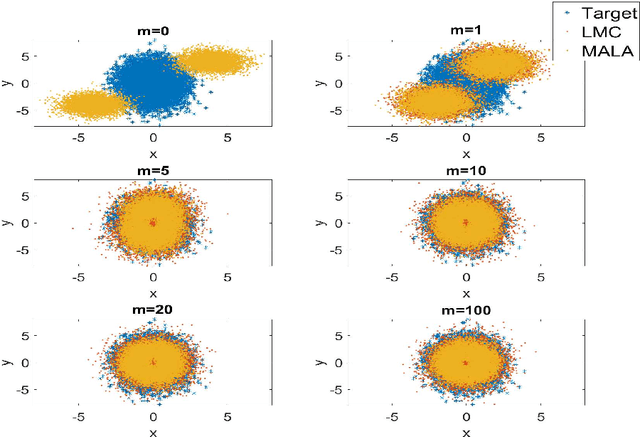
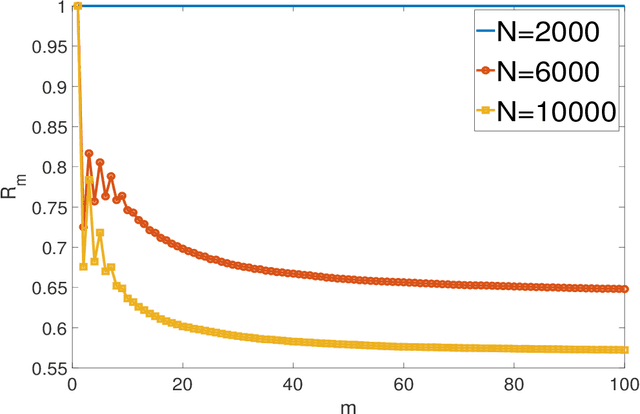
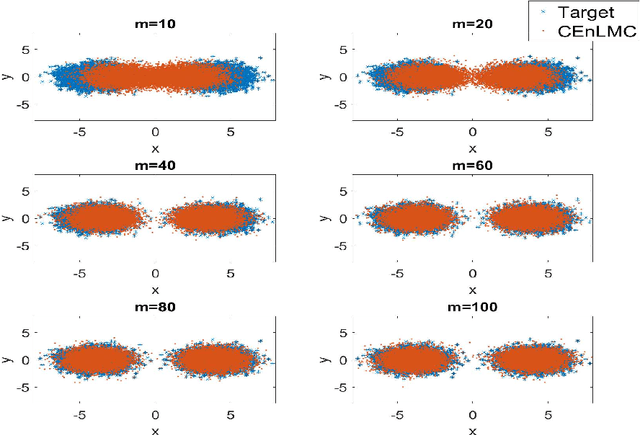
The classical Langevin Monte Carlo method looks for i.i.d. samples from a target distribution by descending along the gradient of the target distribution. It is popular partially due to its fast convergence rate. However, the numerical cost is sometimes high because the gradient can be hard to obtain. One approach to eliminate the gradient computation is to employ the concept of "ensemble", where a large number of particles are evolved together so that the neighboring particles provide gradient information to each other. In this article, we discuss two algorithms that integrate the ensemble feature into LMC, and the associated properties. There are two sides of our discovery: 1. By directly surrogating the gradient using the ensemble approximation, we develop Ensemble Langevin Monte Carlo. We show that this method is unstable due to a potentially small denominator that induces high variance. We provide a counterexample to explicitly show this instability. 2. We then change the strategy and enact the ensemble approximation to the gradient only in a constrained manner, to eliminate the unstable points. The algorithm is termed Constrained Ensemble Langevin Monte Carlo. We show that, with a proper tuning, the surrogation takes place often enough to bring the reasonable numerical saving, while the induced error is still low enough for us to maintain the fast convergence rate, up to a controllable discretization and ensemble error. Such combination of ensemble method and LMC shed light on inventing gradient-free algorithms that produce i.i.d. samples almost exponentially fast.
Random Coordinate Underdamped Langevin Monte Carlo
Oct 22, 2020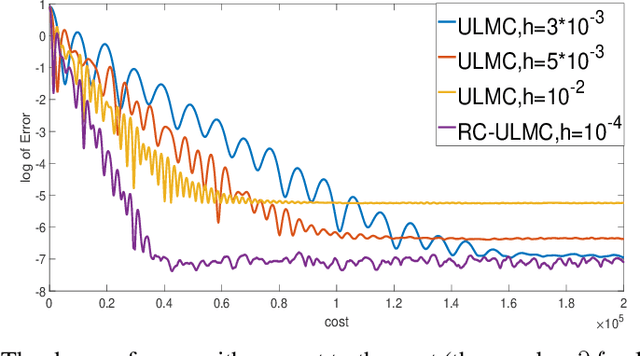
The Underdamped Langevin Monte Carlo (ULMC) is a popular Markov chain Monte Carlo sampling method. It requires the computation of the full gradient of the log-density at each iteration, an expensive operation if the dimension of the problem is high. We propose a sampling method called Random Coordinate ULMC (RC-ULMC), which selects a single coordinate at each iteration to be updated and leaves the other coordinates untouched. We investigate the computational complexity of RC-ULMC and compare it with the classical ULMC for strongly log-concave probability distributions. We show that RC-ULMC is always cheaper than the classical ULMC, with a significant cost reduction when the problem is highly skewed and high dimensional. Our complexity bound for RC-ULMC is also tight in terms of dimension dependence.
Random Coordinate Langevin Monte Carlo
Oct 03, 2020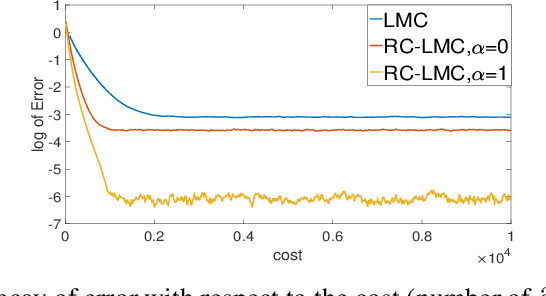
Langevin Monte Carlo (LMC) is a popular Markov chain Monte Carlo sampling method. One drawback is that it requires the computation of the full gradient at each iteration, an expensive operation if the dimension of the problem is high. We propose a new sampling method: Random Coordinate LMC (RC-LMC). At each iteration, a single coordinate is randomly selected to be updated by a multiple of the partial derivative along this direction plus noise, and all other coordinates remain untouched. We investigate the total complexity of RC-LMC and compare it with the classical LMC for log-concave probability distributions. When the gradient of the log-density is Lipschitz, RC-LMC is less expensive than the classical LMC if the log-density is highly skewed for high dimensional problems, and when both the gradient and the Hessian of the log-density are Lipschitz, RC-LMC is always cheaper than the classical LMC, by a factor proportional to the square root of the problem dimension. In the latter case, our estimate of complexity is sharp with respect to the dimension.
Langevin Monte Carlo: random coordinate descent and variance reduction
Jul 29, 2020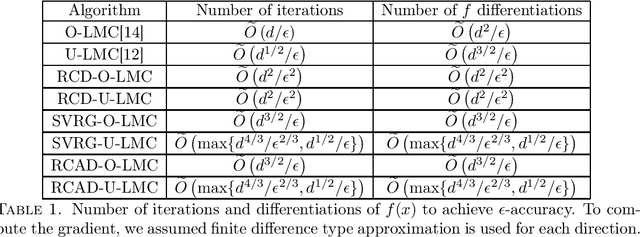
Sampling from a log-concave distribution function on $\mathbb{R}^d$ (with $d\gg 1$) is a popular problem that has wide applications. In this paper we study the application of random coordinate descent method (RCD) on the Langevin Monte Carlo (LMC) sampling method, and we find two sides of the theory: 1. The direct application of RCD on LMC does reduce the number of finite differencing approximations per iteration, but it induces a large variance error term. More iterations are then needed, and ultimately the method gains no computational advantage; 2. When variance reduction techniques (such as SAGA and SVRG) are incorporated in RCD-LMC, the variance error term is reduced. The new methods, compared to the vanilla LMC, reduce the total computational cost by $d$ folds, and achieve the optimal cost rate. We perform our investigations in both overdamped and underdamped settings.
Variance reduction for Langevin Monte Carlo in high dimensional sampling problems
Jun 21, 2020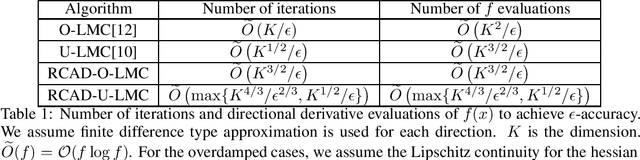
Sampling from a log-concave distribution function is one core problem that has wide applications in Bayesian statistics and machine learning. While most gradient free methods have slow convergence rate, the Langevin Monte Carlo (LMC) that provides fast convergence requires the computation of gradients. In practice one uses finite-differencing approximations as surrogates, and the method is expensive in high-dimensions. A natural strategy to reduce computational cost in each iteration is to utilize random gradient approximations, such as random coordinate descent (RCD) or simultaneous perturbation stochastic approximation (SPSA).We show by a counterexample that blindly applying RCD does not achieve the goal in the most general setting. The high variance induced by the randomness means a larger number of iterations are needed, and this balances out the saving in each iteration. We then introduce a new variance reduction approach, termed Randomized Coordinates Averaging Descent (RCAD), and incorporate it with both overdamped and underdamped LMC. The methods are termed RCAD-O-LMC and RCAD-U-LMC respectively. The methods still sit in the random gradient approximation framework, and thus the computational cost in each iteration is low. However, by employing RCAD, the variance is reduced, so the methods converge within the same number of iterations as the classical overdamped and underdamped LMC. This leads to a computational saving overall.