 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Adversarial Training for Zero-Shot Voice Cloning
Aug 28, 2024A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
Toward Zero Oracle Word Error Rate on the Switchboard Benchmark
Jun 13, 2022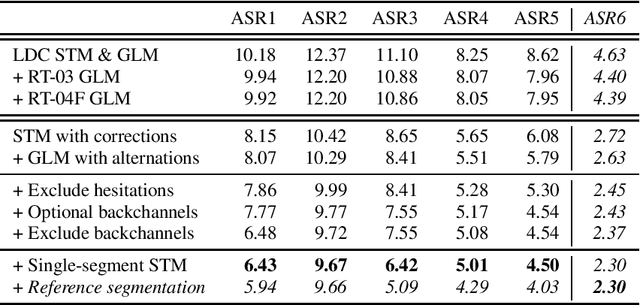
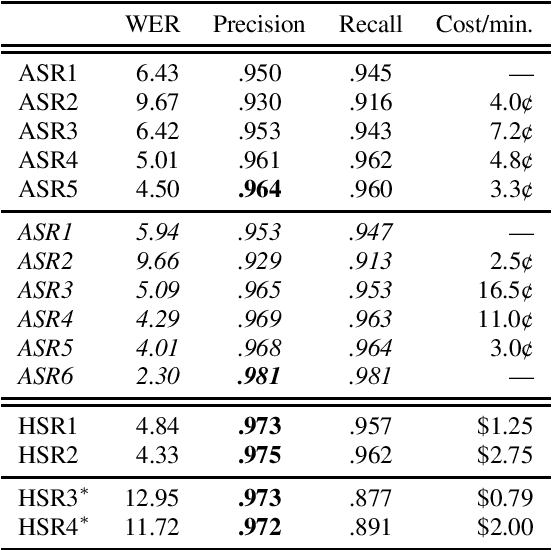
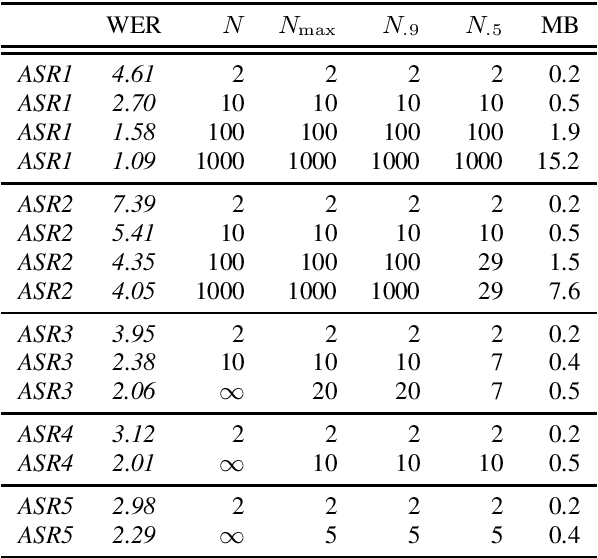
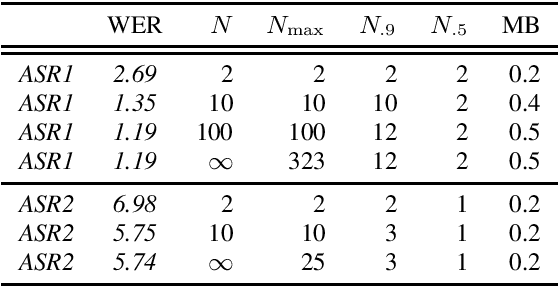
The "Switchboard benchmark" is a very well-known test set in automatic speech recognition (ASR) research, establishing record-setting performance for systems that claim human-level transcription accuracy. This work highlights lesser-known practical considerations of this evaluation, demonstrating major improvements in word error rate (WER) by correcting the reference transcriptions and deviating from the official scoring methodology. In this more detailed and reproducible scheme, even commercial ASR systems can score below 5\% WER and the established record for a research system is lowered to 2.3%. An alternative metric of transcript precision is proposed, which does not penalize deletions and appears to be more discriminating for human vs. machine performance. While commercial ASR systems are still below this threshold, a research system is shown to clearly surpass the accuracy of commercial human speech recognition. This work also explores using standardized scoring tools to compute oracle WER by selecting the best among a list of alternatives. A phrase alternatives representation is compared to utterance-level N-best lists and word-level data structures; using dense lattices and adding out-of-vocabulary words, this achieves an oracle WER of 0.18%.