 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
Paper and Code
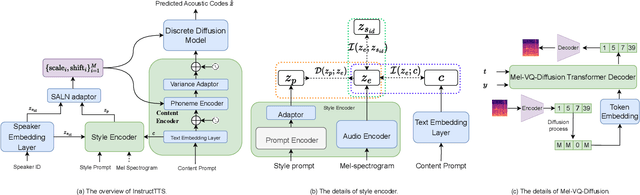
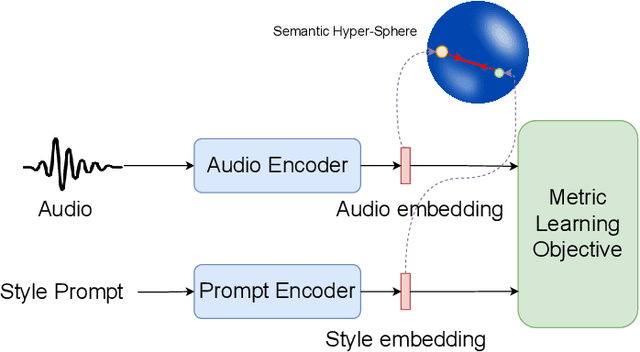
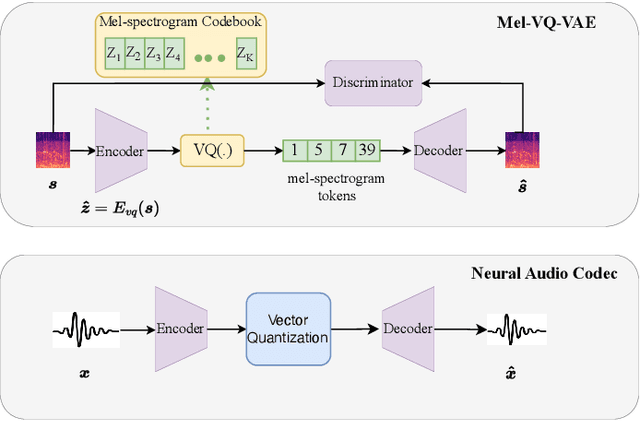
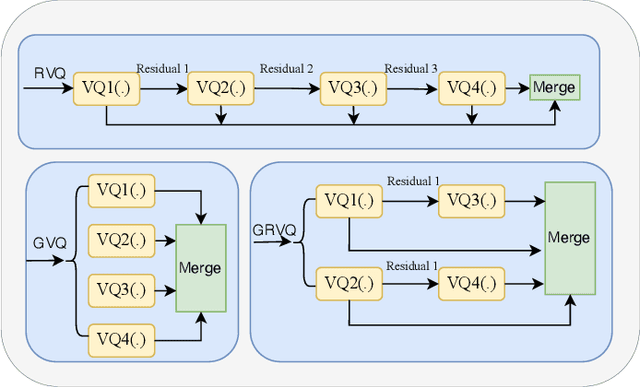
Expressive text-to-speech (TTS) aims to synthesize different speaking style speech according to human's demands. Nowadays, there are two common ways to control speaking styles: (1) Pre-defining a group of speaking style and using categorical index to denote different speaking style. However, there are limitations in the diversity of expressiveness, as these models can only generate the pre-defined styles. (2) Using reference speech as style input, which results in a problem that the extracted style information is not intuitive or interpretable. In this study, we attempt to use natural language as style prompt to control the styles in the synthetic speech, \textit{e.g.}, ``Sigh tone in full of sad mood with some helpless feeling". Considering that there is no existing TTS corpus which is proper to benchmark this novel task, we first construct a speech corpus, whose speech samples are annotated with not only content transcriptions but also style descriptions in natural language. Then we propose an expressive TTS model, named as InstructTTS, which is novel in the sense of following aspects: (1) We fully take the advantage of self-supervised learning and cross-modal metric learning, and propose a novel three-stage training procedure to obtain a robust sentence embedding model, which can effectively capture semantic information from the style prompts and control the speaking style in the generated speech. (2) We propose to model acoustic features in discrete latent space and train a novel discrete diffusion probabilistic model to generate vector-quantized (VQ) acoustic tokens rather than the commonly-used mel spectrogram. (3) We jointly apply mutual information (MI) estimation and minimization during acoustic model training to minimize style-speaker and style-content MI, avoiding possible content and speaker information leakage from the style prompt.