 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDurIAN-E 2: Duration Informed Attention Network with Adaptive Variational Autoencoder and Adversarial Learning for Expressive Text-to-Speech Synthesis
Paper and Code
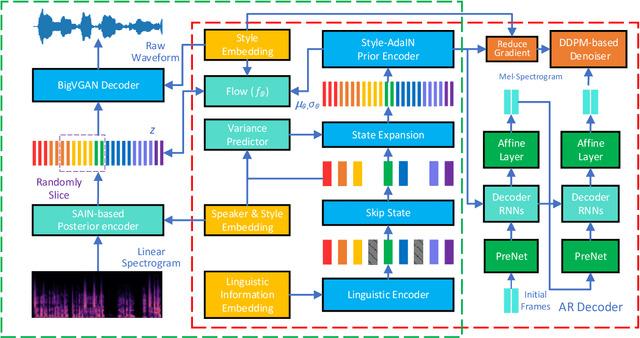
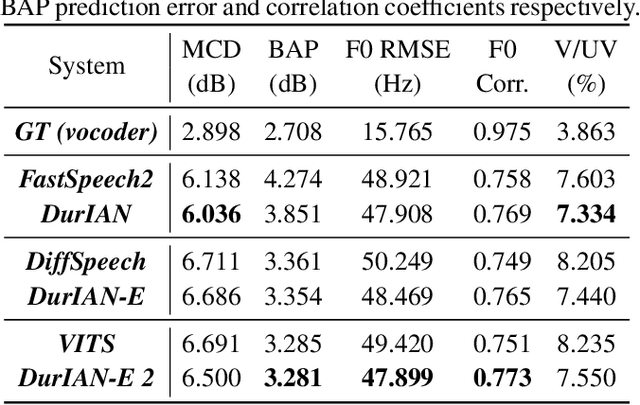
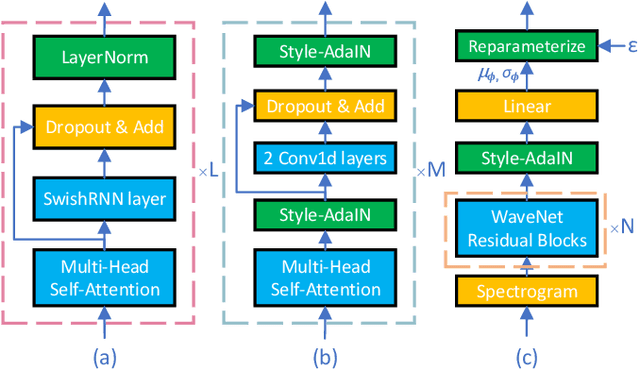

This paper proposes an improved version of DurIAN-E (DurIAN-E 2), which is also a duration informed attention neural network for expressive and high-fidelity text-to-speech (TTS) synthesis. Similar with the DurIAN-E model, multiple stacked SwishRNN-based Transformer blocks are utilized as linguistic encoders and Style-Adaptive Instance Normalization (SAIN) layers are also exploited into frame-level encoders to improve the modeling ability of expressiveness in the proposed the DurIAN-E 2. Meanwhile, motivated by other TTS models using generative models such as VITS, the proposed DurIAN-E 2 utilizes variational autoencoders (VAEs) augmented with normalizing flows and a BigVGAN waveform generator with adversarial training strategy, which further improve the synthesized speech quality and expressiveness. Both objective test and subjective evaluation results prove that the proposed expressive TTS model DurIAN-E 2 can achieve better performance than several state-of-the-art approaches besides DurIAN-E.