 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness and representation in satellite-based poverty maps: Evidence of urban-rural disparities and their impacts on downstream policy
May 02, 2023
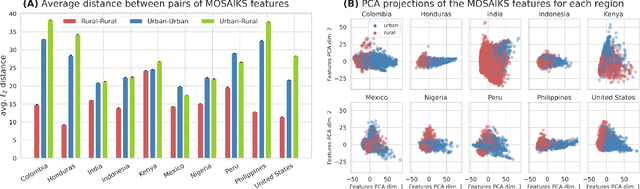


Poverty maps derived from satellite imagery are increasingly used to inform high-stakes policy decisions, such as the allocation of humanitarian aid and the distribution of government resources. Such poverty maps are typically constructed by training machine learning algorithms on a relatively modest amount of ``ground truth" data from surveys, and then predicting poverty levels in areas where imagery exists but surveys do not. Using survey and satellite data from ten countries, this paper investigates disparities in representation, systematic biases in prediction errors, and fairness concerns in satellite-based poverty mapping across urban and rural lines, and shows how these phenomena affect the validity of policies based on predicted maps. Our findings highlight the importance of careful error and bias analysis before using satellite-based poverty maps in real-world policy decisions.
Can Strategic Data Collection Improve the Performance of Poverty Prediction Models?
Nov 16, 2022

Machine learning-based estimates of poverty and wealth are increasingly being used to guide the targeting of humanitarian aid and the allocation of social assistance. However, the ground truth labels used to train these models are typically borrowed from existing surveys that were designed to produce national statistics -- not to train machine learning models. Here, we test whether adaptive sampling strategies for ground truth data collection can improve the performance of poverty prediction models. Through simulations, we compare the status quo sampling strategies (uniform at random and stratified random sampling) to alternatives that prioritize acquiring training data based on model uncertainty or model performance on sub-populations. Perhaps surprisingly, we find that none of these active learning methods improve over uniform-at-random sampling. We discuss how these results can help shape future efforts to refine machine learning-based estimates of poverty.
Program Targeting with Machine Learning and Mobile Phone Data: Evidence from an Anti-Poverty Intervention in Afghanistan
Jun 22, 2022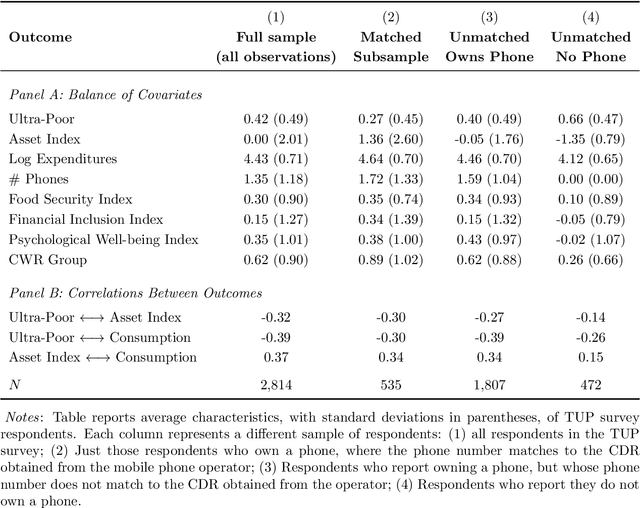
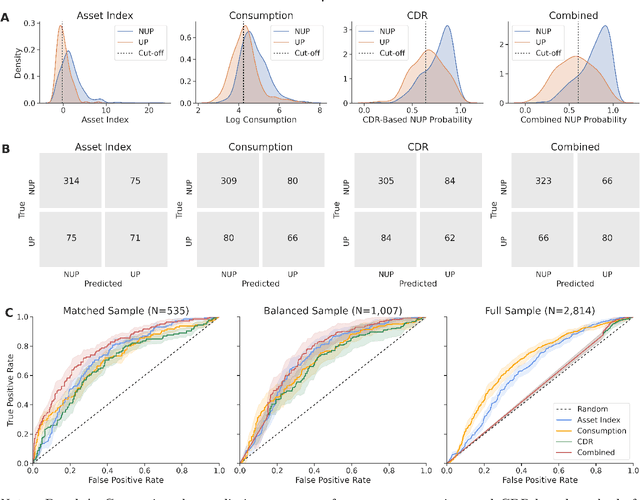
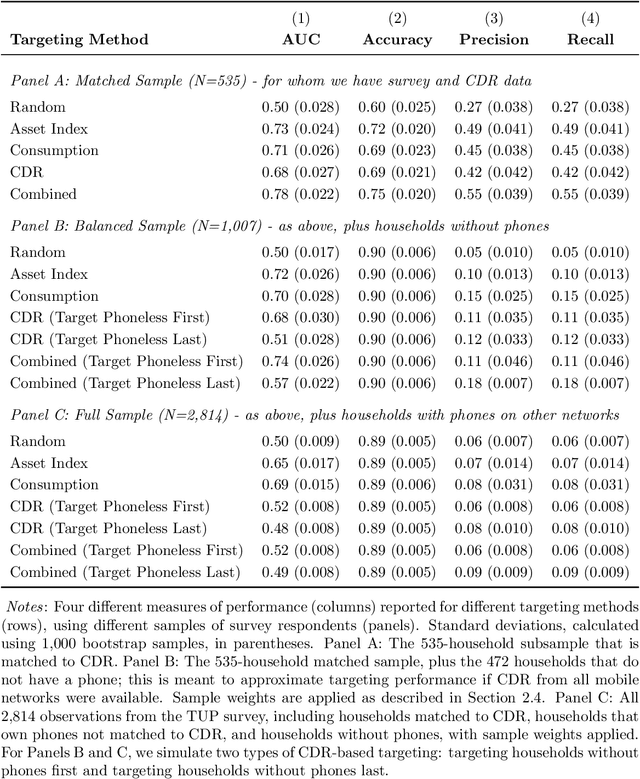
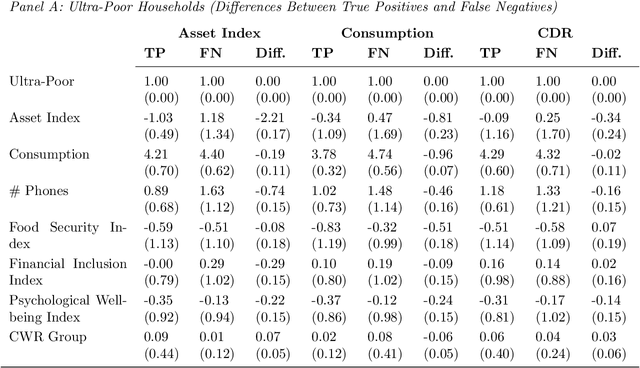
Can mobile phone data improve program targeting? By combining rich survey data from a "big push" anti-poverty program in Afghanistan with detailed mobile phone logs from program beneficiaries, we study the extent to which machine learning methods can accurately differentiate ultra-poor households eligible for program benefits from ineligible households. We show that machine learning methods leveraging mobile phone data can identify ultra-poor households nearly as accurately as survey-based measures of consumption and wealth; and that combining survey-based measures with mobile phone data produces classifications more accurate than those based on a single data source.
Balancing Competing Objectives with Noisy Data: Score-Based Classifiers for Welfare-Aware Machine Learning
Mar 15, 2020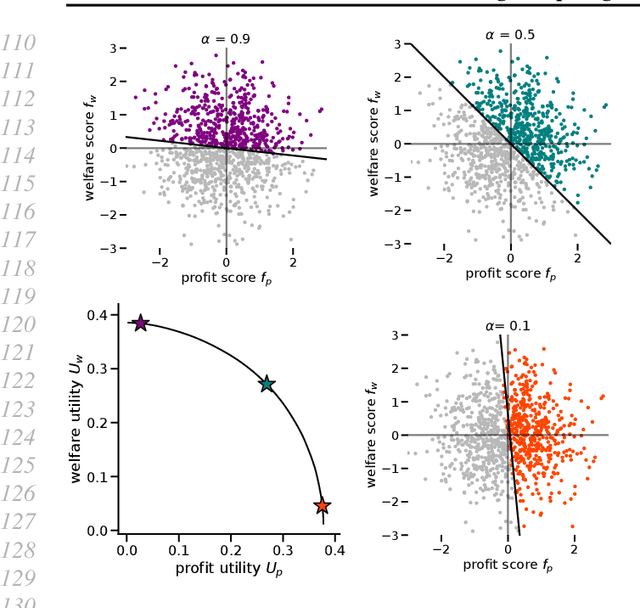
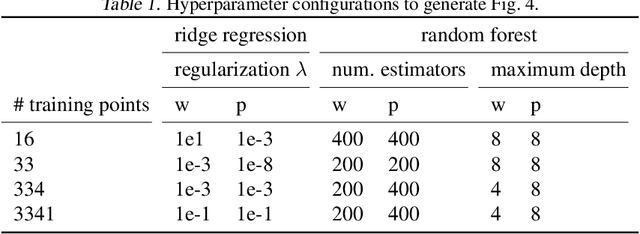
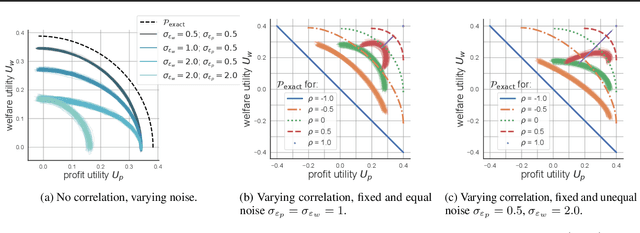
While real-world decisions involve many competing objectives, algorithmic decisions are often evaluated with a single objective function. In this paper, we study algorithmic policies which explicitly trade off between a private objective (such as profit) and a public objective (such as social welfare). We analyze a natural class of policies which trace an empirical Pareto frontier based on learned scores, and focus on how such decisions can be made in noisy or data-limited regimes. Our theoretical results characterize the optimal strategies in this class, bound the Pareto errors due to inaccuracies in the scores, and show an equivalence between optimal strategies and a rich class of fairness-constrained profit-maximizing policies. We then present empirical results in two different contexts --- online content recommendation and sustainable abalone fisheries --- to underscore the applicability of our approach to a wide range of practical decisions. Taken together, these results shed light on inherent trade-offs in using machine learning for decisions that impact social welfare.
Determinants of Mobile Money Adoption in Pakistan
Nov 13, 2017
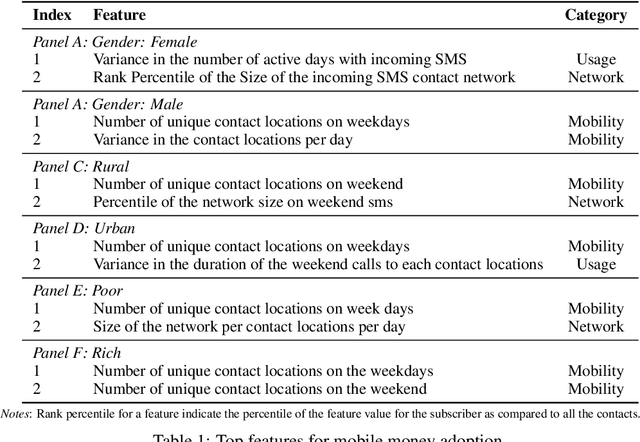
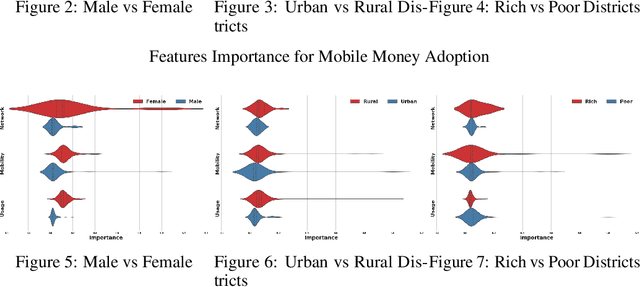
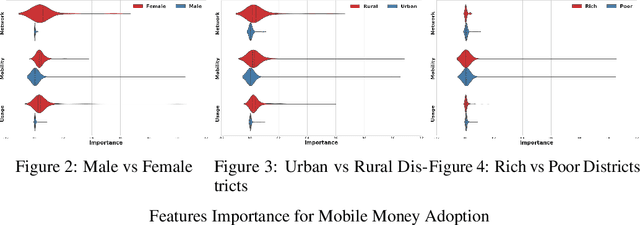
In this work, we analyze the problem of adoption of mobile money in Pakistan by using the call detail records of a major telecom company as our input. Our results highlight the fact that different sections of the society have different patterns of adoption of digital financial services but user mobility related features are the most important one when it comes to adopting and using mobile money services.
Predicting Student Dropout in Higher Education
Mar 07, 2017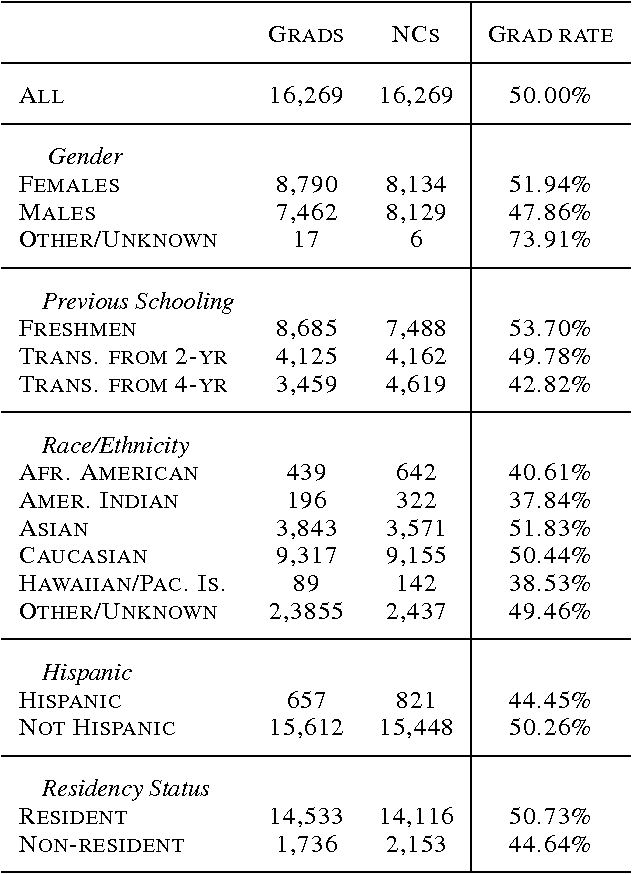
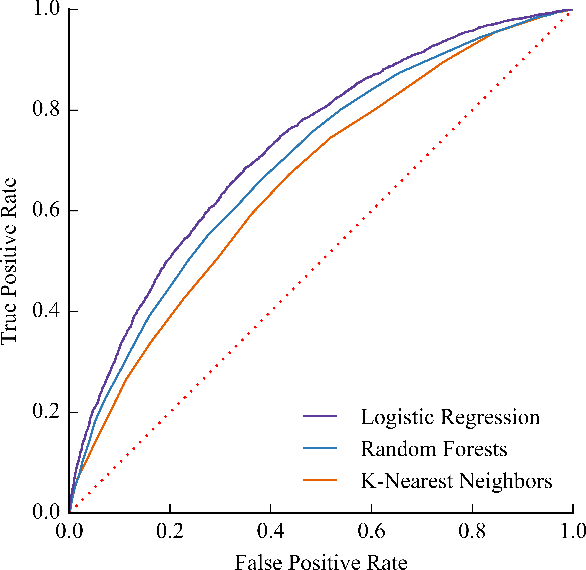

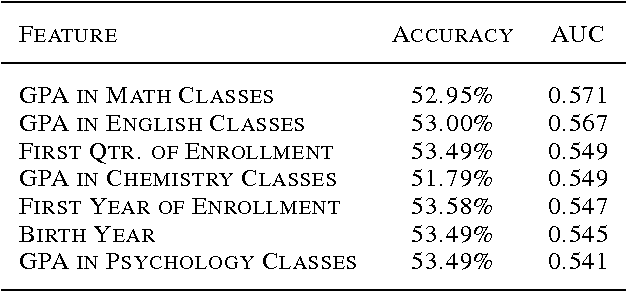
Each year, roughly 30% of first-year students at US baccalaureate institutions do not return for their second year and over $9 billion is spent educating these students. Yet, little quantitative research has analyzed the causes and possible remedies for student attrition. Here, we describe initial efforts to model student dropout using the largest known dataset on higher education attrition, which tracks over 32,500 students' demographics and transcript records at one of the nation's largest public universities. Our results highlight several early indicators of student attrition and show that dropout can be accurately predicted even when predictions are based on a single term of academic transcript data. These results highlight the potential for machine learning to have an impact on student retention and success while pointing to several promising directions for future work.
Behavioral Modeling for Churn Prediction: Early Indicators and Accurate Predictors of Custom Defection and Loyalty
Dec 20, 2015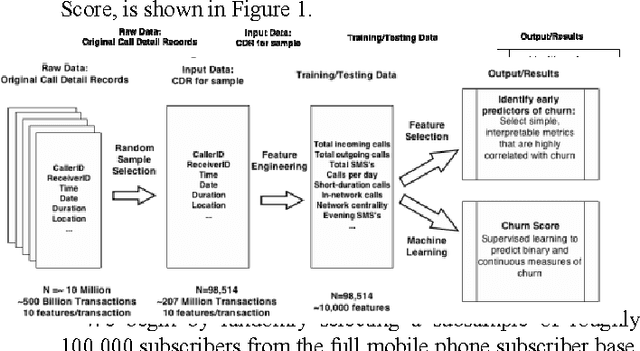

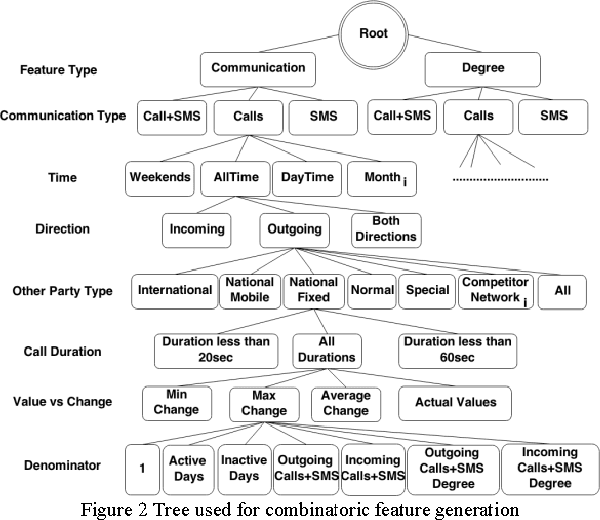
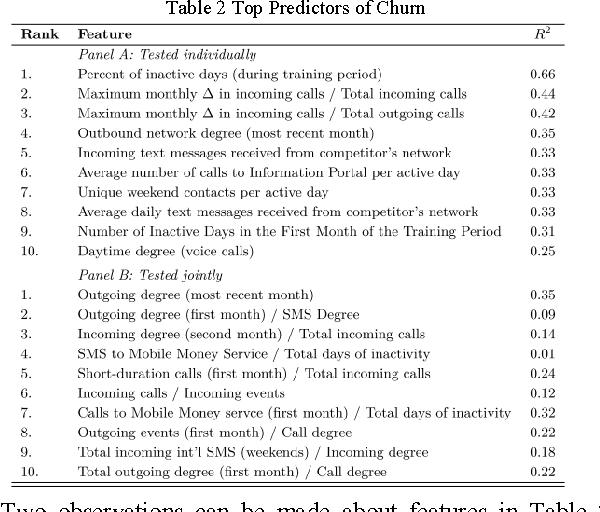
Churn prediction, or the task of identifying customers who are likely to discontinue use of a service, is an important and lucrative concern of firms in many different industries. As these firms collect an increasing amount of large-scale, heterogeneous data on the characteristics and behaviors of customers, new methods become possible for predicting churn. In this paper, we present a unified analytic framework for detecting the early warning signs of churn, and assigning a "Churn Score" to each customer that indicates the likelihood that the particular individual will churn within a predefined amount of time. This framework employs a brute force approach to feature engineering, then winnows the set of relevant attributes via feature selection, before feeding the final feature-set into a suite of supervised learning algorithms. Using several terabytes of data from a large mobile phone network, our method identifies several intuitive - and a few surprising - early warning signs of churn, and our best model predicts whether a subscriber will churn with 89.4% accuracy.