 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-BioNER: Multi-task Learning for Biomedical Named Entity Recognition using Deep Bidirectional Transformers
Jan 24, 2020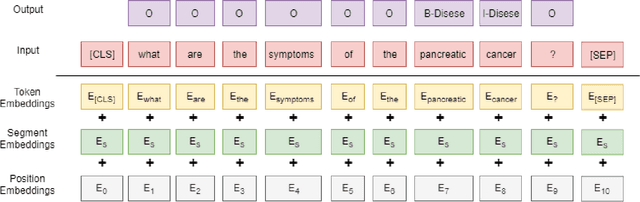


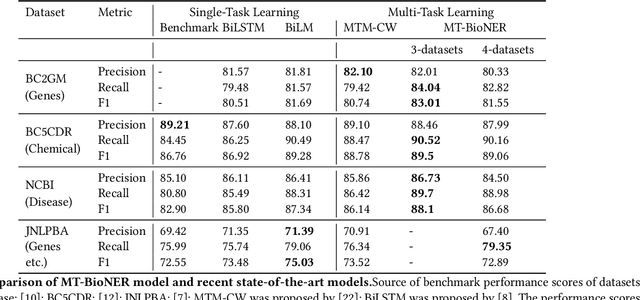
Conversational agents such as Cortana, Alexa and Siri are continuously working on increasing their capabilities by adding new domains. The support of a new domain includes the design and development of a number of NLU components for domain classification, intents classification and slots tagging (including named entity recognition). Each component only performs well when trained on a large amount of labeled data. Second, these components are deployed on limited-memory devices which requires some model compression. Third, for some domains such as the health domain, it is hard to find a single training data set that covers all the required slot types. To overcome these mentioned problems, we present a multi-task transformer-based neural architecture for slot tagging. We consider the training of a slot tagger using multiple data sets covering different slot types as a multi-task learning problem. The experimental results on the biomedical domain have shown that the proposed approach outperforms the previous state-of-the-art systems for slot tagging on the different benchmark biomedical datasets in terms of (time and memory) efficiency and effectiveness. The output slot tagger can be used by the conversational agent to better identify entities in the input utterances.
Multi-GCN: Graph Convolutional Networks for Multi-View Networks, with Applications to Global Poverty
Jan 31, 2019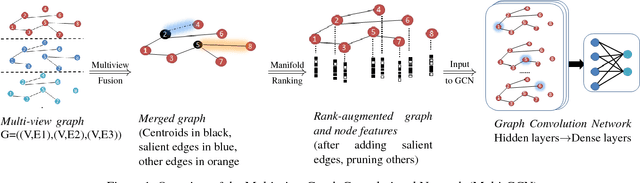



With the rapid expansion of mobile phone networks in developing countries, large-scale graph machine learning has gained sudden relevance in the study of global poverty. Recent applications range from humanitarian response and poverty estimation to urban planning and epidemic containment. Yet the vast majority of computational tools and algorithms used in these applications do not account for the multi-view nature of social networks: people are related in myriad ways, but most graph learning models treat relations as binary. In this paper, we develop a graph-based convolutional network for learning on multi-view networks. We show that this method outperforms state-of-the-art semi-supervised learning algorithms on three different prediction tasks using mobile phone datasets from three different developing countries. We also show that, while designed specifically for use in poverty research, the algorithm also outperforms existing benchmarks on a broader set of learning tasks on multi-view networks, including node labelling in citation networks.
Determinants of Mobile Money Adoption in Pakistan
Nov 13, 2017
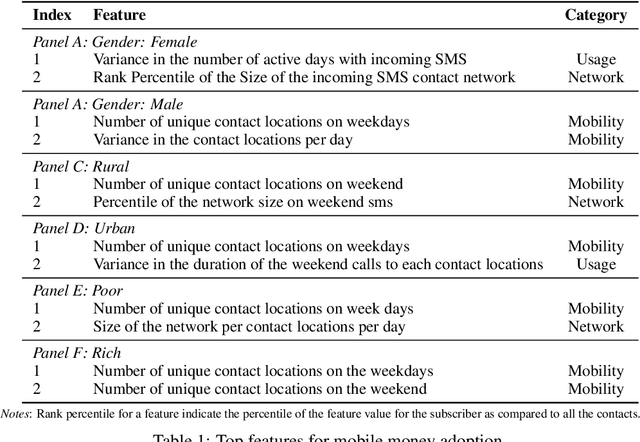
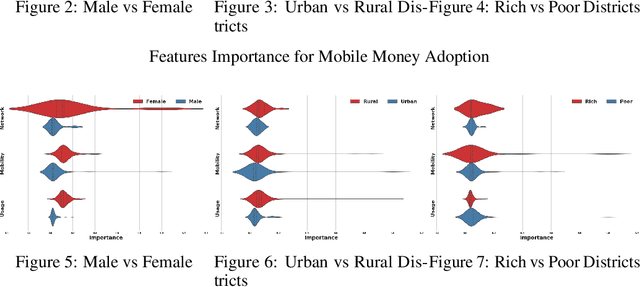
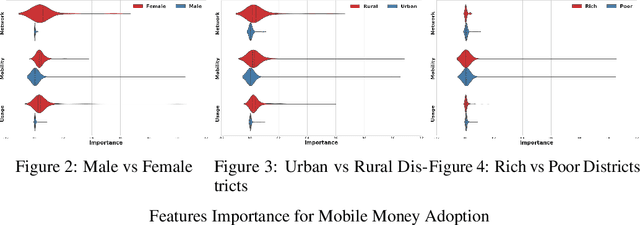
In this work, we analyze the problem of adoption of mobile money in Pakistan by using the call detail records of a major telecom company as our input. Our results highlight the fact that different sections of the society have different patterns of adoption of digital financial services but user mobility related features are the most important one when it comes to adopting and using mobile money services.
Machine Learning Across Cultures: Modeling the Adoption of Financial Services for the Poor
Jun 16, 2016
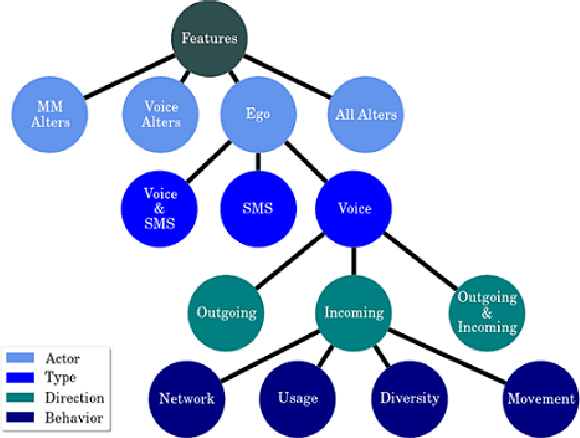
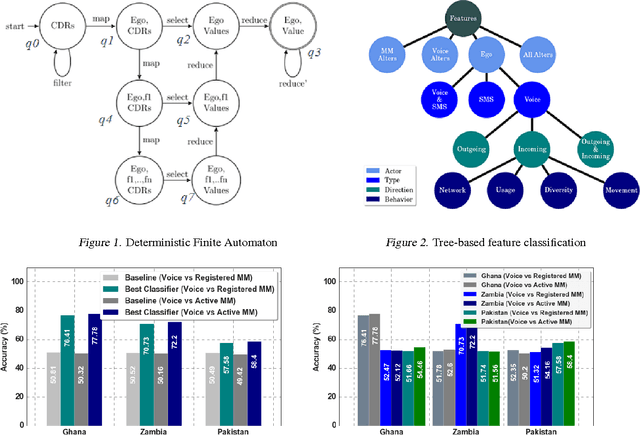

Recently, mobile operators in many developing economies have launched "Mobile Money" platforms that deliver basic financial services over the mobile phone network. While many believe that these services can improve the lives of the poor, a consistent difficulty has been identifying individuals most likely to benefit from access to the new technology. Here, we combine terabyte-scale data from three different mobile phone operators from Ghana, Pakistan, and Zambia, to better understand the behavioral determinants of mobile money adoption. Our supervised learning models provide insight into the best predictors of adoption in three very distinct cultures. We find that models fit on one population fail to generalize to another, and in general are highly context-dependent. These findings highlight the need for a nuanced approach to understanding the role and potential of financial services for the poor.