 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(Machine) Learning What Policies Value
Jun 01, 2022

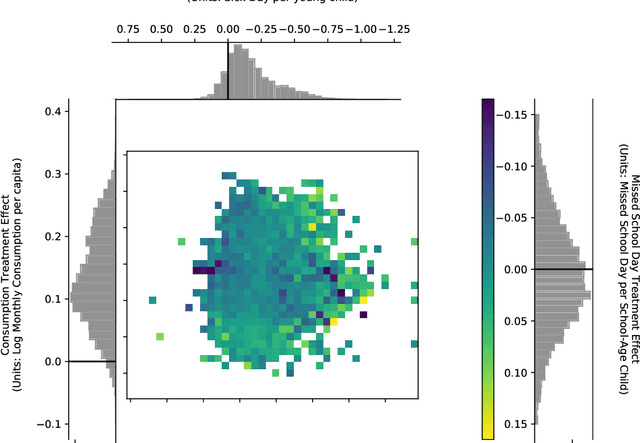
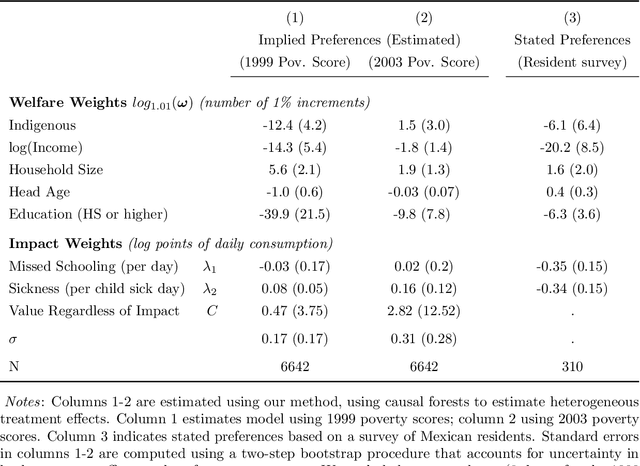
When a policy prioritizes one person over another, is it because they benefit more, or because they are preferred? This paper develops a method to uncover the values consistent with observed allocation decisions. We use machine learning methods to estimate how much each individual benefits from an intervention, and then reconcile its allocation with (i) the welfare weights assigned to different people; (ii) heterogeneous treatment effects of the intervention; and (iii) weights on different outcomes. We demonstrate this approach by analyzing Mexico's PROGRESA anti-poverty program. The analysis reveals that while the program prioritized certain subgroups -- such as indigenous households -- the fact that those groups benefited more implies that they were in fact assigned a lower welfare weight. The PROGRESA case illustrates how the method makes it possible to audit existing policies, and to design future policies that better align with values.
Micro-Estimates of Wealth for all Low- and Middle-Income Countries
Apr 15, 2021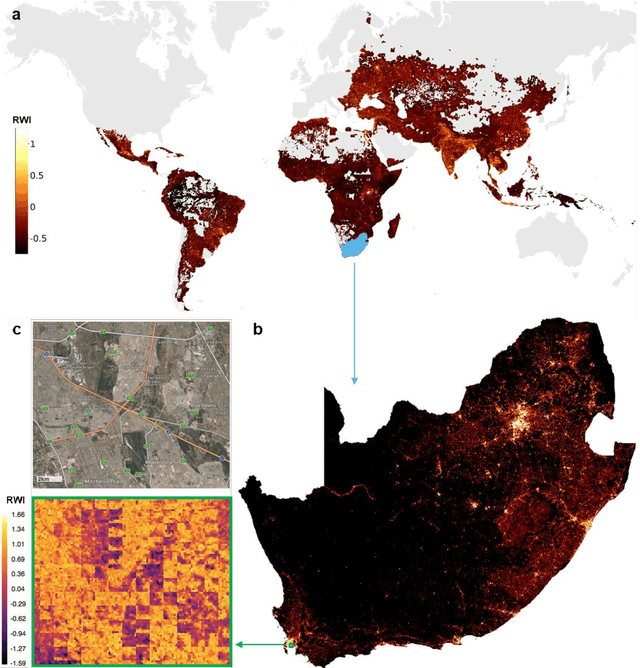
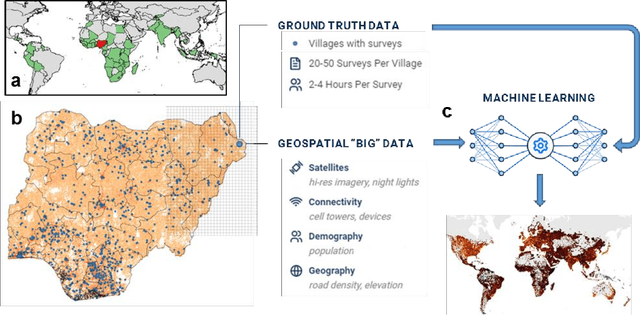
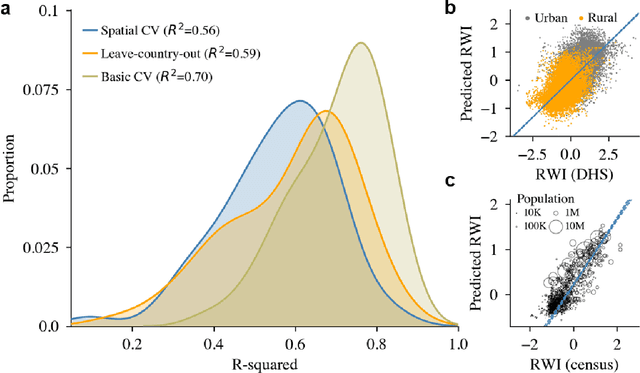
Many critical policy decisions, from strategic investments to the allocation of humanitarian aid, rely on data about the geographic distribution of wealth and poverty. Yet many poverty maps are out of date or exist only at very coarse levels of granularity. Here we develop the first micro-estimates of wealth and poverty that cover the populated surface of all 135 low and middle-income countries (LMICs) at 2.4km resolution. The estimates are built by applying machine learning algorithms to vast and heterogeneous data from satellites, mobile phone networks, topographic maps, as well as aggregated and de-identified connectivity data from Facebook. We train and calibrate the estimates using nationally-representative household survey data from 56 LMICs, then validate their accuracy using four independent sources of household survey data from 18 countries. We also provide confidence intervals for each micro-estimate to facilitate responsible downstream use. These estimates are provided free for public use in the hope that they enable targeted policy response to the COVID-19 pandemic, provide the foundation for new insights into the causes and consequences of economic development and growth, and promote responsible policymaking in support of the Sustainable Development Goals.
Manipulation-Proof Machine Learning
Apr 08, 2020


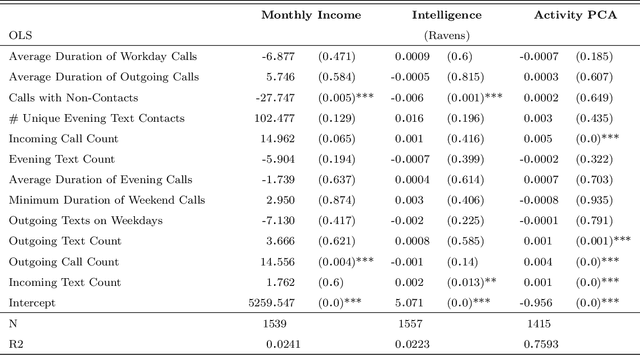
An increasing number of decisions are guided by machine learning algorithms. In many settings, from consumer credit to criminal justice, those decisions are made by applying an estimator to data on an individual's observed behavior. But when consequential decisions are encoded in rules, individuals may strategically alter their behavior to achieve desired outcomes. This paper develops a new class of estimator that is stable under manipulation, even when the decision rule is fully transparent. We explicitly model the costs of manipulating different behaviors, and identify decision rules that are stable in equilibrium. Through a large field experiment in Kenya, we show that decision rules estimated with our strategy-robust method outperform those based on standard supervised learning approaches.
Multi-GCN: Graph Convolutional Networks for Multi-View Networks, with Applications to Global Poverty
Jan 31, 2019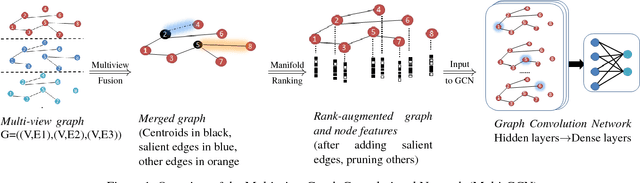



With the rapid expansion of mobile phone networks in developing countries, large-scale graph machine learning has gained sudden relevance in the study of global poverty. Recent applications range from humanitarian response and poverty estimation to urban planning and epidemic containment. Yet the vast majority of computational tools and algorithms used in these applications do not account for the multi-view nature of social networks: people are related in myriad ways, but most graph learning models treat relations as binary. In this paper, we develop a graph-based convolutional network for learning on multi-view networks. We show that this method outperforms state-of-the-art semi-supervised learning algorithms on three different prediction tasks using mobile phone datasets from three different developing countries. We also show that, while designed specifically for use in poverty research, the algorithm also outperforms existing benchmarks on a broader set of learning tasks on multi-view networks, including node labelling in citation networks.
Machine Learning Across Cultures: Modeling the Adoption of Financial Services for the Poor
Jun 16, 2016
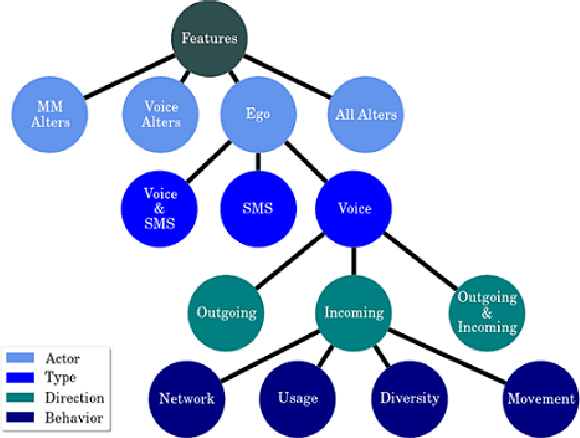
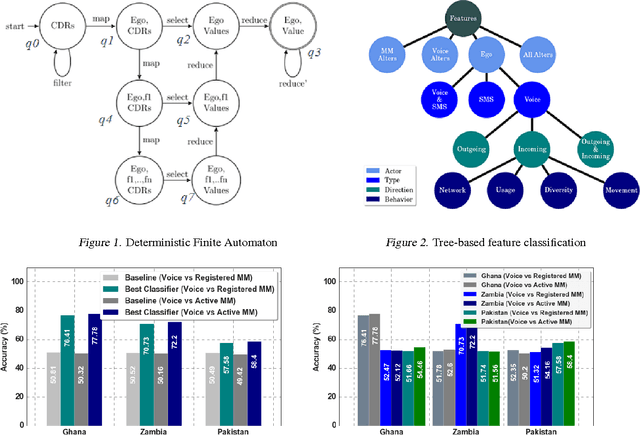

Recently, mobile operators in many developing economies have launched "Mobile Money" platforms that deliver basic financial services over the mobile phone network. While many believe that these services can improve the lives of the poor, a consistent difficulty has been identifying individuals most likely to benefit from access to the new technology. Here, we combine terabyte-scale data from three different mobile phone operators from Ghana, Pakistan, and Zambia, to better understand the behavioral determinants of mobile money adoption. Our supervised learning models provide insight into the best predictors of adoption in three very distinct cultures. We find that models fit on one population fail to generalize to another, and in general are highly context-dependent. These findings highlight the need for a nuanced approach to understanding the role and potential of financial services for the poor.