 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould AI Leapfrog the Web? Evidence from Teachers in Sierra Leone
Feb 18, 2025



Access to digital information is a driver of economic development. But although 85% of sub-Saharan Africa's population is covered by mobile broadband signal, only 37% use the internet, and those who do seldom use the web. We investigate whether AI can bridge this gap by analyzing how 469 teachers use an AI chatbot in Sierra Leone. The chatbot, accessible via a common messaging app, is compared against traditional web search. Teachers use AI more frequently than web search for teaching assistance. Data cost is the most frequently cited reason for low internet usage across Africa. The average web search result consumes 3,107 times more data than an AI response, making AI 87% less expensive than web search. Additionally, only 2% of results for corresponding web searches contain content from Sierra Leone. In blinded evaluations, an independent sample of teachers rate AI responses as more relevant, helpful, and correct than web search results. These findings suggest that AI-driven solutions can cost-effectively bridge information gaps in low-connectivity regions.
(Machine) Learning What Policies Value
Jun 01, 2022

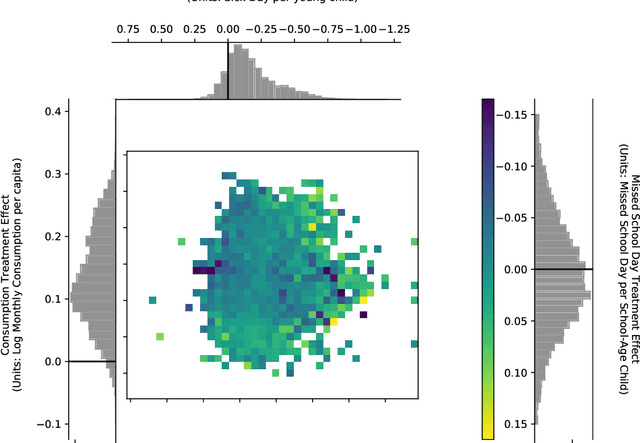
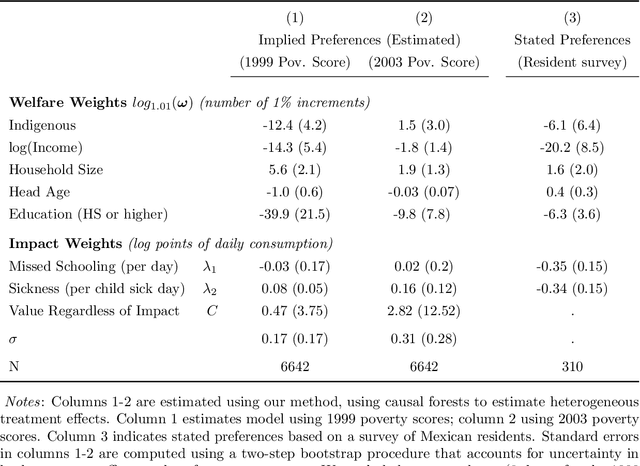
When a policy prioritizes one person over another, is it because they benefit more, or because they are preferred? This paper develops a method to uncover the values consistent with observed allocation decisions. We use machine learning methods to estimate how much each individual benefits from an intervention, and then reconcile its allocation with (i) the welfare weights assigned to different people; (ii) heterogeneous treatment effects of the intervention; and (iii) weights on different outcomes. We demonstrate this approach by analyzing Mexico's PROGRESA anti-poverty program. The analysis reveals that while the program prioritized certain subgroups -- such as indigenous households -- the fact that those groups benefited more implies that they were in fact assigned a lower welfare weight. The PROGRESA case illustrates how the method makes it possible to audit existing policies, and to design future policies that better align with values.
Manipulation-Proof Machine Learning
Apr 08, 2020


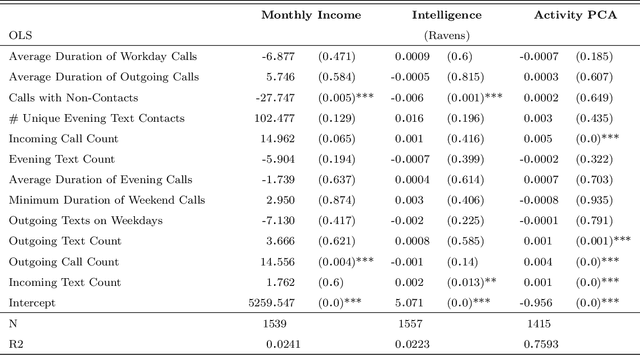
An increasing number of decisions are guided by machine learning algorithms. In many settings, from consumer credit to criminal justice, those decisions are made by applying an estimator to data on an individual's observed behavior. But when consequential decisions are encoded in rules, individuals may strategically alter their behavior to achieve desired outcomes. This paper develops a new class of estimator that is stable under manipulation, even when the decision rule is fully transparent. We explicitly model the costs of manipulating different behaviors, and identify decision rules that are stable in equilibrium. Through a large field experiment in Kenya, we show that decision rules estimated with our strategy-robust method outperform those based on standard supervised learning approaches.
Balancing Competing Objectives with Noisy Data: Score-Based Classifiers for Welfare-Aware Machine Learning
Mar 15, 2020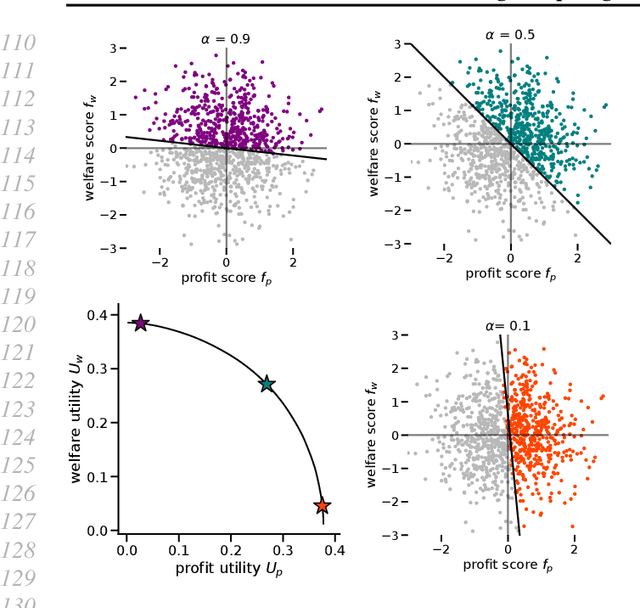
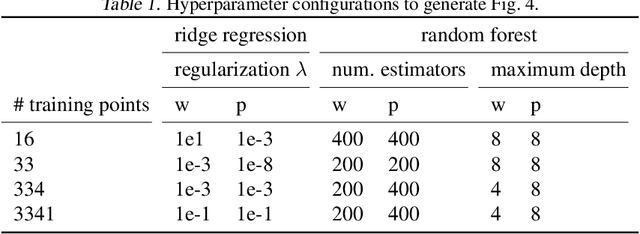
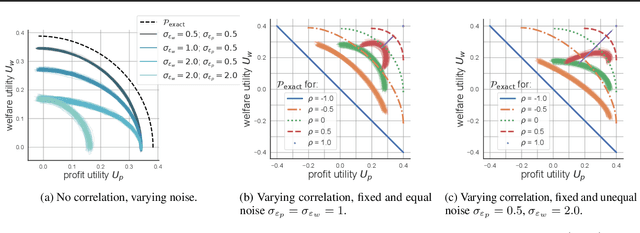
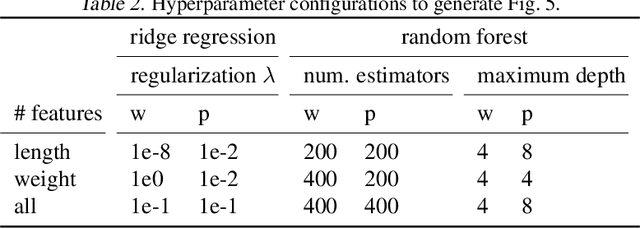
While real-world decisions involve many competing objectives, algorithmic decisions are often evaluated with a single objective function. In this paper, we study algorithmic policies which explicitly trade off between a private objective (such as profit) and a public objective (such as social welfare). We analyze a natural class of policies which trace an empirical Pareto frontier based on learned scores, and focus on how such decisions can be made in noisy or data-limited regimes. Our theoretical results characterize the optimal strategies in this class, bound the Pareto errors due to inaccuracies in the scores, and show an equivalence between optimal strategies and a rich class of fairness-constrained profit-maximizing policies. We then present empirical results in two different contexts --- online content recommendation and sustainable abalone fisheries --- to underscore the applicability of our approach to a wide range of practical decisions. Taken together, these results shed light on inherent trade-offs in using machine learning for decisions that impact social welfare.