 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould AI Leapfrog the Web? Evidence from Teachers in Sierra Leone
Feb 18, 2025



Access to digital information is a driver of economic development. But although 85% of sub-Saharan Africa's population is covered by mobile broadband signal, only 37% use the internet, and those who do seldom use the web. We investigate whether AI can bridge this gap by analyzing how 469 teachers use an AI chatbot in Sierra Leone. The chatbot, accessible via a common messaging app, is compared against traditional web search. Teachers use AI more frequently than web search for teaching assistance. Data cost is the most frequently cited reason for low internet usage across Africa. The average web search result consumes 3,107 times more data than an AI response, making AI 87% less expensive than web search. Additionally, only 2% of results for corresponding web searches contain content from Sierra Leone. In blinded evaluations, an independent sample of teachers rate AI responses as more relevant, helpful, and correct than web search results. These findings suggest that AI-driven solutions can cost-effectively bridge information gaps in low-connectivity regions.
Multi-environment Topic Models
Oct 31, 2024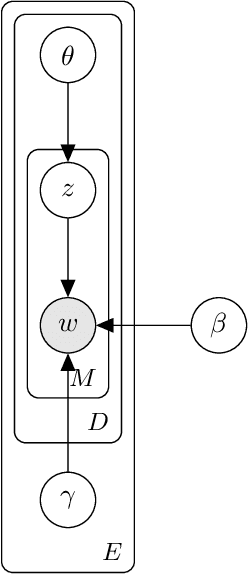
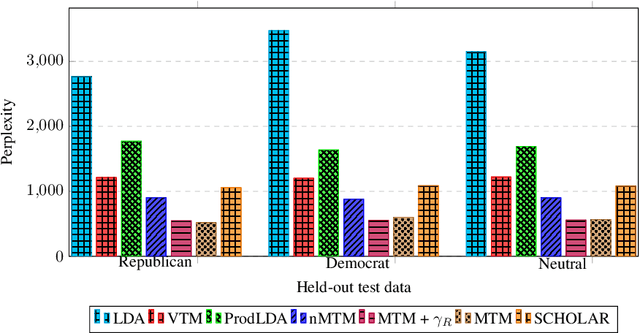

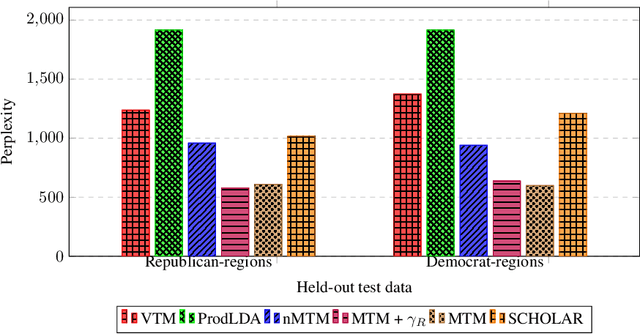
Probabilistic topic models are a powerful tool for extracting latent themes from large text datasets. In many text datasets, we also observe per-document covariates (e.g., source, style, political affiliation) that act as environments that modulate a "global" (environment-agnostic) topic representation. Accurately learning these representations is important for prediction on new documents in unseen environments and for estimating the causal effect of topics on real-world outcomes. To this end, we introduce the Multi-environment Topic Model (MTM), an unsupervised probabilistic model that separates global and environment-specific terms. Through experimentation on various political content, from ads to tweets and speeches, we show that the MTM produces interpretable global topics with distinct environment-specific words. On multi-environment data, the MTM outperforms strong baselines in and out-of-distribution. It also enables the discovery of accurate causal effects.