 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Voice Application Recommender System for Unhandled Utterances in Intelligent Personal Assistant
Oct 19, 2021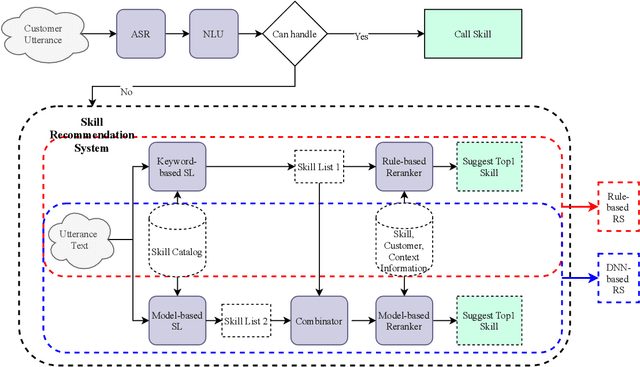
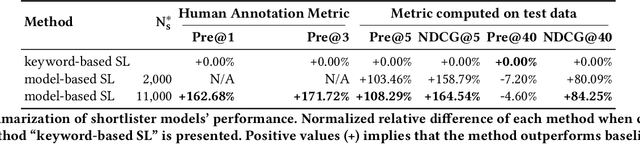

Intelligent personal assistants (IPA) enable voice applications that facilitate people's daily tasks. However, due to the complexity and ambiguity of voice requests, some requests may not be handled properly by the standard natural language understanding (NLU) component. In such cases, a simple reply like "Sorry, I don't know" hurts the user's experience and limits the functionality of IPA. In this paper, we propose a two-stage shortlister-reranker recommender system to match third-party voice applications (skills) to unhandled utterances. In this approach, a skill shortlister is proposed to retrieve candidate skills from the skill catalog by calculating both lexical and semantic similarity between skills and user requests. We also illustrate how to build a new system by using observed data collected from a baseline rule-based system, and how the exposure biases can generate discrepancy between offline and human metrics. Lastly, we present two relabeling methods that can handle the incomplete ground truth, and mitigate exposure bias. We demonstrate the effectiveness of our proposed system through extensive offline experiments. Furthermore, we present online A/B testing results that show a significant boost on user experience satisfaction.
MT-BioNER: Multi-task Learning for Biomedical Named Entity Recognition using Deep Bidirectional Transformers
Jan 24, 2020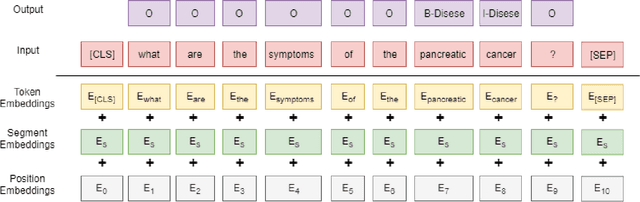


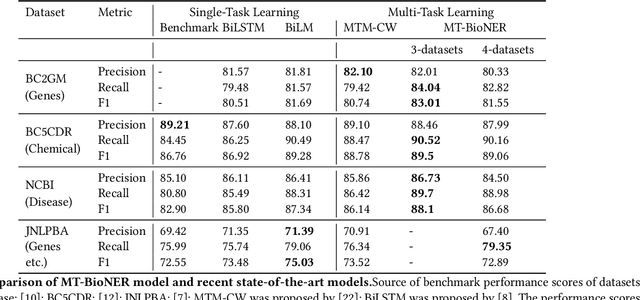
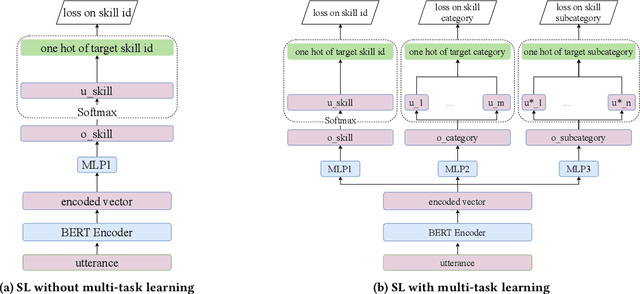
Conversational agents such as Cortana, Alexa and Siri are continuously working on increasing their capabilities by adding new domains. The support of a new domain includes the design and development of a number of NLU components for domain classification, intents classification and slots tagging (including named entity recognition). Each component only performs well when trained on a large amount of labeled data. Second, these components are deployed on limited-memory devices which requires some model compression. Third, for some domains such as the health domain, it is hard to find a single training data set that covers all the required slot types. To overcome these mentioned problems, we present a multi-task transformer-based neural architecture for slot tagging. We consider the training of a slot tagger using multiple data sets covering different slot types as a multi-task learning problem. The experimental results on the biomedical domain have shown that the proposed approach outperforms the previous state-of-the-art systems for slot tagging on the different benchmark biomedical datasets in terms of (time and memory) efficiency and effectiveness. The output slot tagger can be used by the conversational agent to better identify entities in the input utterances.