 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the selection and effectiveness of pseudo-absences for species distribution modeling with deep learning
Jan 03, 2024



Species distribution modeling is a highly versatile tool for understanding the intricate relationship between environmental conditions and species occurrences. However, the available data often lacks information on confirmed species absence and is limited to opportunistically sampled, presence-only observations. To overcome this limitation, a common approach is to employ pseudo-absences, which are specific geographic locations designated as negative samples. While pseudo-absences are well-established for single-species distribution models, their application in the context of multi-species neural networks remains underexplored. Notably, the significant class imbalance between species presences and pseudo-absences is often left unaddressed. Moreover, the existence of different types of pseudo-absences (e.g., random and target-group background points) adds complexity to the selection process. Determining the optimal combination of pseudo-absences types is difficult and depends on the characteristics of the data, particularly considering that certain types of pseudo-absences can be used to mitigate geographic biases. In this paper, we demonstrate that these challenges can be effectively tackled by integrating pseudo-absences in the training of multi-species neural networks through modifications to the loss function. This adjustment involves assigning different weights to the distinct terms of the loss function, thereby addressing both the class imbalance and the choice of pseudo-absence types. Additionally, we propose a strategy to set these loss weights using spatial block cross-validation with presence-only data. We evaluate our approach using a benchmark dataset containing independent presence-absence data from six different regions and report improved results when compared to competing approaches.
So2Sat LCZ42: A Benchmark Dataset for Global Local Climate Zones Classification
Dec 19, 2019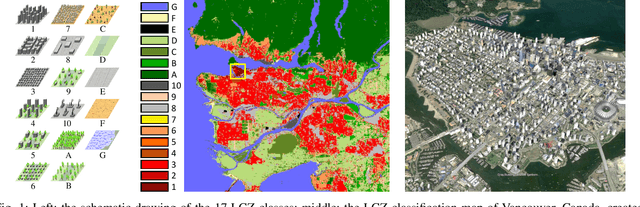
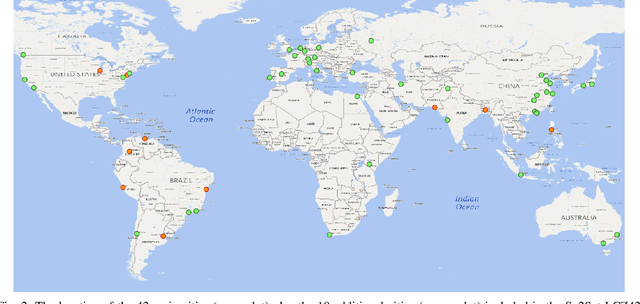

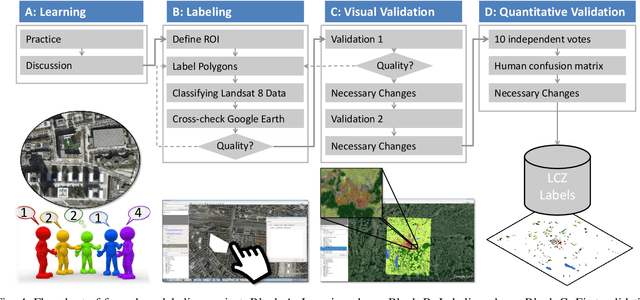
Access to labeled reference data is one of the grand challenges in supervised machine learning endeavors. This is especially true for an automated analysis of remote sensing images on a global scale, which enables us to address global challenges such as urbanization and climate change using state-of-the-art machine learning techniques. To meet these pressing needs, especially in urban research, we provide open access to a valuable benchmark dataset named "So2Sat LCZ42," which consists of local climate zone (LCZ) labels of about half a million Sentinel-1 and Sentinel-2 image patches in 42 urban agglomerations (plus 10 additional smaller areas) across the globe. This dataset was labeled by 15 domain experts following a carefully designed labeling work flow and evaluation process over a period of six months. As rarely done in other labeled remote sensing dataset, we conducted rigorous quality assessment by domain experts. The dataset achieved an overall confidence of 85%. We believe this LCZ dataset is a first step towards an unbiased globallydistributed dataset for urban growth monitoring using machine learning methods, because LCZ provide a rather objective measure other than many other semantic land use and land cover classifications. It provides measures of the morphology, compactness, and height of urban areas, which are less dependent on human and culture. This dataset can be accessed from http://doi.org/10.14459/2018mp1483140.