 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pretraining and Controlled Augmentation Improve Rare Wildlife Recognition in UAV Images
Paper and Code
Aug 17, 2021

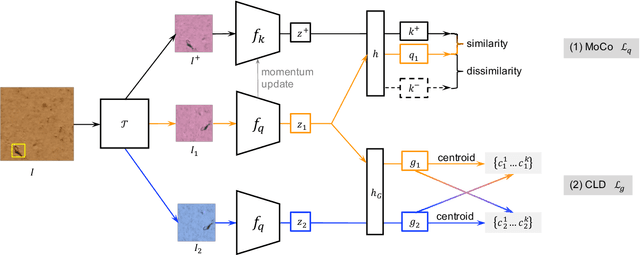

Automated animal censuses with aerial imagery are a vital ingredient towards wildlife conservation. Recent models are generally based on deep learning and thus require vast amounts of training data. Due to their scarcity and minuscule size, annotating animals in aerial imagery is a highly tedious process. In this project, we present a methodology to reduce the amount of required training data by resorting to self-supervised pretraining. In detail, we examine a combination of recent contrastive learning methodologies like Momentum Contrast (MoCo) and Cross-Level Instance-Group Discrimination (CLD) to condition our model on the aerial images without the requirement for labels. We show that a combination of MoCo, CLD, and geometric augmentations outperforms conventional models pre-trained on ImageNet by a large margin. Crucially, our method still yields favorable results even if we reduce the number of training animals to just 10%, at which point our best model scores double the recall of the baseline at similar precision. This effectively allows reducing the number of required annotations to a fraction while still being able to train high-accuracy models in such highly challenging settings.