 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJuggling With Representations: On the Information Transfer Between Imagery, Point Clouds, and Meshes for Multi-Modal Semantics
Paper and Code
Mar 12, 2021

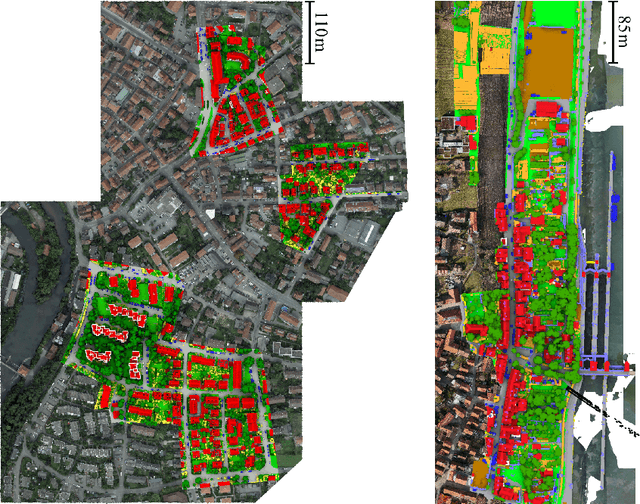
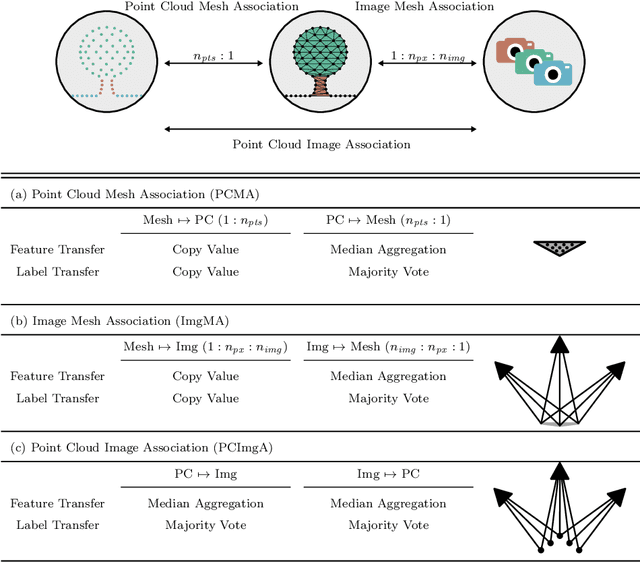
The automatic semantic segmentation of the huge amount of acquired remote sensing data has become an important task in the last decade. Images and Point Clouds (PCs) are fundamental data representations, particularly in urban mapping applications. Textured 3D meshes integrate both data representations geometrically by wiring the PC and texturing the surface elements with available imagery. We present a mesh-centered holistic geometry-driven methodology that explicitly integrates entities of imagery, PC and mesh. Due to its integrative character, we choose the mesh as the core representation that also helps to solve the visibility problem for points in imagery. Utilizing the proposed multi-modal fusion as the backbone and considering the established entity relationships, we enable the sharing of information across the modalities imagery, PC and mesh in a two-fold manner: (i) feature transfer and (ii) label transfer. By these means, we achieve to enrich feature vectors to multi-modal feature vectors for each representation. Concurrently, we achieve to label all representations consistently while reducing the manual label effort to a single representation. Consequently, we facilitate to train machine learning algorithms and to semantically segment any of these data representations - both in a multi-modal and single-modal sense. The paper presents the association mechanism and the subsequent information transfer, which we believe are cornerstones for multi-modal scene analysis. Furthermore, we discuss the preconditions and limitations of the presented approach in detail. We demonstrate the effectiveness of our methodology on the ISPRS 3D semantic labeling contest (Vaihingen 3D) and a proprietary data set (Hessigheim 3D).